Event Loop
Event Loop即事件循环,是指浏览器或者Nodejs解决javascript单线程运行时异步逻辑不会阻塞的一种机制。
Event Loop是一个执行模型,不同的运行环境有不同的实现,浏览器和nodejs基于不同的技术实现自己的event loop。
- 浏览器的Event Loop是在HTML5规范中明确定义。
- Nodejs的Event Loop是libuv实现的。
- libuv已经对Event Loop作出了实现,HTML5规范中只是定义的浏览器中Event Loop的模型,具体的实现交给了浏览器厂商。
宏队列和微队列
在javascript中,任务被分为两种,一种为宏任务(macrotask),也称为task,一种为微任务(microtask),也称为jobs。
宏任务主要包括:
- script全部代码
- setTimeout
- setInterval
- setImmediate (Nodejs独有,浏览器暂时不支持,只有IE10支持)
- requestAnimationFrame (浏览器独有)
- I/O
- UI rendering (浏览器独有)
微任务主要包括:
- process.nextTick (Nodejs独有)
- Promise
- Object.observe (废弃)
- MutationObserver
浏览器中的Event Loop
Javascript 有一个主线程 main thread 和 一个调用栈(执行栈) call-stack,所有任务都会被放到调用栈等待主线程的执行。
JS调用栈采用的是后进先出的规则,当函数执行时,会被添加到调用栈的顶部,当执行栈执行完后,就会从栈顶移除,直到栈内被清空。
Javascript单线程任务可以分为同步任务和异步任务,同步任务会在调用栈内按照顺序依次被主线程执行,异步任务会在异步任务有了结果后,将注册的回调函数放入任务队列中等待主线程空闲的时候(调用栈被清空的时候),被读取到调用栈内等待主线程的执行
任务队列 Task Queue, 是先进先出的数据结构。

浏览器Event Loop的具体流程:
- 执行全局Javascript的同步代码,可能包含一些同步语句,也可以是异步语句(setTimeout语句不执行回调函数里面的,Promise中.then之前的语句)
- 全局Javascript执行完毕后,调用栈call-stack会被清空
- 从微队列microtask queue中取出位于首部的回调函数,放入到调用栈call-stack中执行,执行完毕后从调用栈中删除,microtask queue的长度减1。
- 继续从微队列microtask queue的队首取出任务,放到调用栈中执行,依次循环往复,直至微任务队列microtask queue中的任务都被调用栈执行完毕。特别注意,如果在执行微任务microtask过程中,又产生了微任务microtask,新产生的微任务也会追加到微任务队列microtask queue的尾部,新生成的微任务也会在当前周期中被执行完毕。
- microtask queue中的任务都被执行完毕后,microtask queue为空队列,调用栈也处于空闲阶段
- 执行UI rendering
- 从宏队列macrotask queue的队首取出宏任务,放入调用栈中执行。
- 执行完后,调用栈为空闲状态
- 重复 3 - 8 的步骤,直至宏任务队列的任务都被执行完毕。
…
浏览器Event Loop的3个重点:
- 宏队列macrotask queue每次只从中取出一个任务放到调用栈中执行,执行完后去执行微任务队列中的所有任务
- 微任务队列中的所有任务都会依次取出来执行,只是微任务队列中的任务清空
- UI rendering 的执行节点在微任务队列执行完毕后,宏任务队列中取出任务执行之前执行
NodeJs中的Event Loop
libuv结构

NodeJs中的宏任务队列和微任务队列
NodeJs的Event Loop中,执行宏任务队列的回调有6个阶段

Node的Event Loop可以分为6个阶段,各个阶段执行的任务如下所示:
timers: 执行setTimeout和setInterval中到期的callback。I/O callbacks: 执行几乎所有的回调,除了close callbacks以及timers调度的回调和setImmediate()调度的回调。idle, prepare: 仅在内部使用。poll: 最重要的阶段,检索新的I/O事件,在适当的情况下回阻塞在该阶段。check: 执行setImmediate的callback(setImmediate()会将事件回调插入到事件队列的尾部,主线程和事件队列的任务执行完毕后会立即执行setImmediate中传入的回调函数)。close callbacks: 执行close事件的callback,例如socket.on(‘close’, fn)或则http.server.on(‘close’, fn)等。
NodeJs中的宏任务队列可以分为下列4个:
- Timers Queue
- I/O Callbacks Queue
- Check Queue
- Close Callbacks Queue
在浏览器中只有一个宏任务队列,所有宏任务都会放入到宏任务队列中等待放入执行栈中被主线程执行,NodeJs中有4个宏任务队列,不同类型的宏任务会被放入到不同的宏任务队列中。
NodeJs中的微任务队列可以分为下列2个:
Next Tick Queue: 放置process.nextTick(callback)的回调函数Other Micro Queue: 其他microtask,例如Promise等
在浏览器中只有一个微任务队列,所有微任务都会放入到微任务队列中等待放入执行栈中被主线程执行,NodeJs中有2个微任务队列,不同类型的微任务会被放入到不同的微任务队列中。

NodeJs的Event Loop的具体流程:
- 执行全局Javascript的同步代码,可能包含一些同步语句,也可以是异步语句(setTimeout语句不执行回调函数里面的,Promise中.then之前的语句)。
- 执行微任务队列中的微任务,先执行Next Tick Queue队列中的所有的所有任务,再执行Other Micro Queue队列中的所有任务。
- 开始执行宏任务队列中的任务,共6个阶段,从第1个阶段开始执行每个阶段对应宏任务队列中的所有任务,注意,这里执行的是该阶段宏任务队列中的所有的任务,浏览器Event Loop每次只会中宏任务队列中取出队首的任务执行,执行完后开始执行微任务队列中的任务,NodeJs的Event Loop会执行完该阶段中宏任务队列中的所有任务后,才开始执行微任务队列中的任务,也就是步骤2。
- Timers Queue -> 步骤2 -> I/O Callbacks Queue -> 步骤2 -> Check Queue -> 步骤2 -> Close Callback Queue -> 步骤2 -> Timers Queue -> ……
特别注意:
- 上述的第三步,当 NodeJs 版本小于11时,NodeJs的Event Loop会执行完该阶段中宏任务队列中的所有任务
- 当 NodeJS 版本大于等于11时,在timer阶段的setTimeout,setInterval…和在check阶段的setImmediate都在node11里面都修改为一旦执行一个阶段里的一个任务就立刻执行微任务队列。为了和浏览器更加趋同。
NodeJs的Event Loop的microtask queue和macrotask queue的执行顺序详情


当setTimeout(fn, 0)和setImmediate(fn)放在同一同步代码中执行时,可能会出现下面两种情况:
第一种情况: 同步代码执行完后,timer还没到期,setImmediate中注册的回调函数先放入到Check Queue的宏任务队列中,先执行微任务队列,然后开始执行宏任务队列,先从Timers Queue开始,由于在Timer Queue中未发现任何的回调函数,往下阶段走,直到Check Queue中发现setImmediate中注册的回调函数,先执行,然后timer到期,setTimeout注册的回调函数会放入到Timers Queue的宏任务队列中,下一轮后再次执行到Timers Queue阶段时,才会再Timers Queue中发现了setTimeout注册的回调函数,于是执行该timer的回调,所以,setImmediate(fn)注册的回调函数会早于setTimeout(fn, 0)注册的回调函数执行。
第二种情况: 同步代码执行完之前,timer已经到期,setTimeout注册的回调函数会放入到Timers Queue的宏任务队列中,执行同步代码到setImmediate时,将其回调函数注册到Check Queue中,同步代码执行完后,先执行微任务队列,然后开始执行宏任务队列,先从Timers Queue开始,在Timers Queue发现了timer中注册的回调函数,取出执行,往下阶段走,到Check Queue中发现setImmediate中注册的回调函数,又执行,所以这种情况时,setTimeout(fn, 0)注册的回调函数会早于setImmediate(fn)注册的回调函数执行。
在同步代码中同时调setTimeout(fn, 0)和setImmediate执行顺序情况是不确定的,但是如果把他们放在一个IO的回调,比如readFile(‘xx’, function () {// ….})回调中,那么IO回调是在I/O Callbacks Queue中,setTimeout到期回调注册到Timers Queue,setImmediate回调注册到Check Queue,I/O Callbacks Queue执行完到Check Queue,Timers Queue得到下个循环周期,所以setImmediate回调这种情况下肯定比setTimeout(fn, 0)回调先执行。
1 | setImmediate(function A() { |
注:
- setImmediate中如果又存在setImmediate语句,内部的setImmediate语句注册的回调函数会在下一个
check阶段来执行,并不在当前的check阶段来执行。
poll 阶段详解:
poll 阶段主要又两个功能:
- 当timers到达指定的时间后,执行指定的timer的回调(Executing scripts for timers whose threshold has elapsed, then)。
- 处理poll队列的事件(Processing events in the poll queue)。
当进入到poll阶段,并且没有timers被调用的时候,会出现下面的情况:
- 如果poll队列不为空,Event Loop将同步执行poll queue中的任务,直到poll queue队列为空或者执行的callback达到上限。
- 如果poll队列为空,会发生下面的情况:
- 如果脚本执行过setImmediate代码,Event Loop会结束poll阶段,直接进入check阶段,执行Check Queue中调用setImmediate注册的回调函数。
- 如果脚本没有执行过setImmediate代码,poll阶段将等待callback被添加到队列中,然后立即执行。
当进入到poll阶段,并且调用了timers的话,会发生下面的情况:
- 一旦poll queue为空,Event Loop会检测Timers Queue中是否存在任务,如果存在任务的话,Event Loop会回到timer阶段并执行Timers Queue中timers注册的回调函数。执行完后是进入check阶段,还是又重新进入I/O callbacks阶段?
setTimeout 对比 setImmediate
- setTimeout(fn, 0)在timers阶段执行,并且是在poll阶段进行判断是否达到指定的timer时间才会执行
- setImmediate(fn)在check阶段执行
两者的执行顺序要根据当前的执行环境才能确定:
- 如果两者都在主模块(main module)调用,那么执行先后取决于进程性能,顺序随机
- 如果两者都不在主模块调用,即在一个I/O Circle中调用,那么setImmediate的回调永远先执行,因为会先到Check阶段
setImmediate 对比 process.nextTick
- setImmediate(fn)的回调任务会插入到宏队列Check Queue中
- process.nextTick(fn)的回调任务会插入到微队列Next Tick Queue中
- process.nextTick(fn)调用深度有限制,上限是1000,而setImmediate则没有
Fetch API使用的常见问题及其解决办法
XMLHttpRequest在发送web请求时需要开发者配置相关请求信息和成功后的回调,尽管开发者只关心请求成功后的业务处理,但是也要配置其他繁琐内容,导致配置和调用比较混乱,也不符合关注分离的原则;fetch的出现正是为了解决XHR存在的这些问题。
fetch是基于Promise设计的,让开发者只关注请求成功后的业务逻辑处理,其他的不用关心,相当简单,FetchAPI的优点如下:
- 语法简单,更加语义化
- 基于标准的Promise实现,支持async/await
- 使用isomorphic-fetch可以方便同构
使用fetch来进行项目开发时,也是有一些常见问题的,下面就来说说fetch使用的常见问题。
Fetch 兼容性问题
fetch是相对较新的技术,当然就会存在浏览器兼容性的问题,借用上面应用文章的一幅图加以说明fetch在各种浏览器的原生支持情况:

从上图可以看出各个浏览器的低版本都不支持fetch技术。
如何在所有浏览器中通用fetch呢,当然就要考虑fetch的polyfill了。
fetch是基于Promise来实现的,所以在低版本浏览器中Promise可能也未被原生支持,所以还需要Promise的polyfill;大多数情况下,实现fetch的polyfill需要涉及到的:
- promise的polyfill,例如es6-promise、babel-polyfill提供的promise实现。
- fetch的polyfill实现,例如isomorphic-fetch和whatwg-fetch
IE浏览器中IE8/9还比较特殊:IE8它使用的是ES3,而IE9则对ES5部分支持。这种情况下还需要ES5的polyfill es5-shim支持了。
上述有关promise的polyfill实现,需要说明的是:
babel-runtime是不能作为Promise的polyfill的实现的,否则在IE8/9下使用fetch会报Promise未定义。为什么?我想大家猜到了,因为babel-runtime实现的polyfill是局部实现而不是全局实现,fetch底层实现用到Promise就是从全局中去取的,拿不到这报上述错误。
fetch的polyfill实现思路:
首先判断浏览器是否原生支持fetch,否则结合Promise使用XMLHttpRequest的方式来实现;这正是whatwg-fetch的实现思路,而同构应用中使用的isomorphic-fetch,其客户端fetch的实现是直接require(“whatwg-fetch”)来实现的。
fetch默认不携带cookie
fetch发送请求默认是不发送cookie的,不管是同域还是跨域;
对于那些需要权限验证的请求就可能无法正常获取数据,可以配置其credentials项,其有3个值:
- omit: 默认值,忽略cookie的发送
- same-origin: 表示cookie只能同域发送,不能跨域发送
- include: cookie既可以同域发送,也可以跨域发送
credentials所表达的含义,其实与XHR2中的withCredentials属性类似,表示请求是否携带cookie;
若要fetch请求携带cookie信息,只需设置一下credentials选项即可,例如fetch(url, {credentials: ‘include’});
fetch默认对服务端通过Set-Cookie头设置的cookie也会忽略,若想选择接受来自服务端的cookie信息,也必须要配置credentials选项;
fetch请求对某些错误http状态不会reject
主要是由fetch返回promise导致的,因为fetch返回的promise在某些错误的http状态下如400、500等不会reject,相反它会被resolve;只有网络错误会导致请求不能完成时,fetch 才会被 reject;所以一般会对fetch请求做一层封装。
1 | function checkStatus(response) { |
fetch不支持超时timeout处理
fetch不像大多数ajax库那样对请求设置超时timeout,它没有有关请求超时的功能,所以在fetch标准添加超时功能之前,都需要polyfill该特性。
实际上,我们真正需要的是abort(), timeout可以通过timeout+abort方式来实现,起到真正超时丢弃当前的请求。
目前的fetch指导规范中,fetch并不是一个具体实例,而只是一个方法;其返回的promise实例根据Promise指导规范标准是不能abort的,也不能手动改变promise实例的状态,只能由内部来根据请求结果来改变promise的状态。
实现fetch的timeout功能,其思想就是新创建一个可以手动控制promise状态的实例,根据不同情况来对新promise实例进行resolve或者reject,从而达到实现timeout的功能;
根据github上timeout handling上的讨论,目前可以有两种不同的解决方法:
方法一: 单纯setTimeout方法
1 | var fetchOrigin = fetch; |
使用这种方式还可模拟XHR的abort方法
1 | var fetchOrigin = fetch; |
方法二: 利用Promise.race方法
Promise.race方法接受一个promise实例数组参数,表示多个promise实例中任何一个最先改变状态,那么race方法返回的promise实例状态就跟着改变
1 | var fetchOrigin = fetch; |
对fetch的timeout的上述实现方式补充几点:
- timeout不是请求连接超时的含义,它表示发送请求到接收响应的时间,包括请求的连接、服务器处理及服务器响应回来的时间。
- fetch的timeout即使超时发生了,本次请求也不会被abort丢弃掉,它在后台仍然会发送到服务器端,只是本次请求的响应内容被丢弃而已。
fetch不支持JSONP
fetch是与服务器端进行异步交互的,而JSONP是外链一个javascript资源,是JSON的一种“使用模式”,可用于解决主流浏览器的跨域数据访问的问题,并不是真正ajax,所以fetch与JSONP没有什么直接关联,当然至少目前是不支持JSONP的。
这里我们把JSONP与fetch关联在一起有点差强人意,fetch只是一个ajax库,我们不可能使fetch支持JSONP;只是我们要实现一个JSONP,只不过这个JSONP的实现要与fetch的实现类似,即基于Promise来实现一个JSONP;而其外在表现给人感觉是fetch支持JSONP一样;
目前比较成熟的开源JSONP实现fetch-jsonp给我们提供了解决方案,想了解可以自行前往。不过再次想唠叨一下其JSONP的实现步骤,因为在本人面试的前端候选人中大部分人对JSONP的实现语焉不详;
使用它非常简单,首先需要用npm安装fetch-jsonp
1 | npm install fetch-jsonp --save-dev |
fetch-jsonp源码如下所示:
1 | const defaultOptions = { |
具体的使用方式:
1 | fetchJsonp('/users.jsonp', { |
fetch不支持progress事件
XHR是原生支持progress事件的,例如下面代码这样:
1 | var xhr = new XMLHttpRequest(); |
但是fetch是不支持有关progress事件的;不过可喜的是,根据fetch的指导规范标准,其内部设计实现了Request和Response类;其中Response封装一些方法和属性,通过Response实例可以访问这些方法和属性,例如response.json()、response.body等等;
值得关注的地方是,response.body是一个可读字节流对象,其实现了一个getRender()方法,其具体作用是:
getRender()方法用于读取响应的原始字节流,该字节流是可以循环读取的,直至body内容传输完成;
因此,利用到这点可以模拟出fetch的progress。
代码实现如下:
1 | // fetch() returns a promise that resolves once headers have been received |
github上也有使用Promise+XHR结合的方式实现类fetch的progress效果(当然这跟fetch完全不搭边)可以参考这里,具体代码如下:
1 | function fetchProgress(url, opts={}, onProgress) { |
fetch跨域问题
既然是ajax库,就不可避免与跨域扯上关系;XHR2是支持跨域请求的,只不过要满足浏览器端支持CORS,服务器通过Access-Control-Allow-Origin来允许指定的源进行跨域,仅此一种方式。
与XHR2一样,fetch也是支持跨域请求的,只不过其跨域请求做法与XHR2一样,需要客户端与服务端支持;另外,fetch还支持一种跨域,不需要服务器支持的形式,具体可以通过其mode的配置项来说明。
fetch的mode配置项有3个值,如下:
- same-origin:该模式是不允许跨域的,它需要遵守同源策略,否则浏览器会返回一个error告知不能跨域;其对应的response type为basic。
- cors: 该模式支持跨域请求,顾名思义它是以CORS的形式跨域;当然该模式也可以同域请求不需要后端额外的CORS支持;其对应的response type为cors。
- no-cors: 该模式用于跨域请求但是服务器不带CORS响应头,也就是服务端不支持CORS;这也是fetch的特殊跨域请求方式;其对应的response type为opaque。
针对跨域请求,cors模式是常见跨域请求实现,但是fetch自带的no-cors跨域请求模式则较为陌生,该模式有一个比较明显的特点:
该模式允许浏览器发送本次跨域请求,但是不能访问响应返回的内容,这也是其response type为opaque不透明的原因。
这与<img />发送的请求类似,只是该模式不能访问响应的内容信息;但是它可以被其他APIs进行处理,例如ServiceWorker。另外,该模式返回的response可以在Cache API中被存储起来以便后续的对它的使用,这点对script、css和图片的CDN资源是非常合适的,因为这些资源响应头中都没有CORS头。
总的来说,fetch的跨域请求是使用CORS方式,需要浏览器和服务端的支持。
原型链和继承
JavaScript是一门面向对象的设计语言,在JS里除了null和undefined,其余一切皆为对象。其中Array/Function/Date/RegExp是Object对象的特殊实例实现,Boolean/Number/String也都有对应的基本包装类型的对象(具有内置的方法)。传统语言是依靠class类来完成面向对象的继承和多态等特性,而JS使用原型链和构造器来实现继承,依靠参数arguments.length来实现多态。并且在ES6里也引入了class关键字来实现类。
函数与对象的关系
有时我们会好奇为什么能给一个函数添加属性,函数难道不应该就是一个执行过程的作用域吗?
1 | var name = 'Hank'; |
我们能够给函数赋一个属性值,当我们输出这个函数时这个属性却无影无踪了,这到底是怎么回事,这个属性又保存在哪里了呢?
其实,在JS里,函数就是一个对象,这些属性自然就跟对象的属性一样被保存起来,函数名称指向这个对象的存储空间。
函数调用过程没查到资料,个人理解为:这个对象内部拥有一个内部属性[[function]]保存有该函数体的字符串形式,当使用()来调用的时候,就会实时对其进行动态解析和执行,如同**eval()**一样。

上图是JS的具体内存分配方式,JS中分为值类型和引用类型,值类型的数据大小固定,我们将其分配在栈里,直接保存其数据。而引用类型是对象,会动态的增删属性,大小不固定,我们把它分配到内存堆里,并用一个指针指向这片地址,也就是Person其实保存的是一个指向这片地址的指针。这里的Person对象是个函数实例,所以拥有特殊的内部属性[[function]]用于调用。同时它也拥有内部属性arguments/this/name,因为不相关,这里我们没有绘出,而展示了我们为其添加的属性age。
函数与原型的关系
同时在JS里,我们创建的每一个函数都有一个prototype(原型)属性,这个属性是一个指针,指向一个用于包含该函数所有实例的共享属性和方法的对象。而这个对象同时包含一个指针指向这个这个函数,这个指针就是constructor,这个函数也被成为构造函数。这样我们就完成了构造函数和原型对象的双向引用。
而上面的代码实质也就是当我们创建了Person构造函数之后,同步开辟了一片空间创建了一个对象作为Person的原型对象,可以通过Person.prototype来访问这个对象,也可以通过Person.prototype.constructor来访问Person该构造函数。通过构造函数我们可以往实例对象里添加属性,如上面的例子里的name属性和sayName()方法。我们也可以通过prototype来添加原型属性,如:

要注意属性和原型属性不是同一个东西,也并不保存在同一个空间里:
1 | Person.age; // 10 |
原型和实例的关系
现在有了构造函数和原型对象,那我们接下来new一个实例出来,这样才能真正体现面向对象编程的思想,也就是继承:
1 | var person1 = new Person('Lee'); |
我们新建了两个实例person1和person2,这些实例的内部都会包含一个指向其构造函数的原型对象的指针(内部属性),这个指针叫[[Prototype]],在ES5的标准上没有规定访问这个属性,但是大部分浏览器实现了**proto**的属性来访问它,成为了实际的通用属性,于是在ES6的附录里写进了该属性。__proto__前后的双下划线说明其本质上是一个内部属性,而不是对外访问的API,因此官方建议新的代码应当避免使用该属性,转而使用Object.setPrototypeOf()(写操作)、Object.getPrototypeOf()(读操作)、Object.create()(生成操作)代替。
这里的prototype我们称为显示原型,__proto__我们称为隐式原型。
1 | Object.getPrototypeOf({}) === Object.prototype; // true |
同时由于现代 JavaScript 引擎优化属性访问所带来的特性的关系,更改对象的 [[Prototype]]在各个浏览器和 JavaScript 引擎上都是一个很慢的操作。其在更改继承的性能上的影响是微妙而又广泛的,这不仅仅限于 obj.proto = … 语句上的时间花费,而且可能会延伸到任何代码,那些可以访问任何[[Prototype]]已被更改的对象的代码。如果你关心性能,你应该避免设置一个对象的 [[Prototype]]。相反,你应该使用 Object.create()来创建带有你想要的[[Prototype]]的新对象。
此时它们的关系是(为了清晰,忽略函数属性的指向,用(function)代指):

在这里我们可以看到两个实例指向了同一个原型对象,而在new的过程中调用了Person()方法,对每个实例分别初始化了name属性和sayName方法,属性值分别被保存,而方法作为引用对象也指向了不同的内存空间。
我们可以用几种方法来验证实例的原型指针到底指向的是不是构造函数的原型对象:
1 | person1.__proto__ === Person.prototype // true |
原型链
现在我们访问实例person1的属性和方法了:
1 | person1.name; // Lee |
想下这个问题,我们的name值来自于person1的属性,那么age值来自于哪?toString( )方法又在哪定义的呢?
这就是我们要说的原型链,原型链是实现继承的主要方法,其思想是利用原型让一个引用类型继承另一个引用类型的属性和方法。如果我们让一个原型对象等于另一个类型的实例,那么该原型对象就会包含一个指向另一个原型的指针,而如果另一个原型对象又是另一个原型的实例,那么上述关系依然成立,层层递进,就构成了实例与原型的链条,这就是原型链的概念。
上面代码的name来自于自身属性,age来自于原型属性,toString( )方法来自于Person原型对象的原型Object。当我们访问一个实例属性的时候,如果没有找到,我们就会继续搜索实例的原型,如果还没有找到,就递归搜索原型链直到原型链末端。我们可以来验证一下原型链的关系:
1 | Person.prototype.__proto__ === Object.prototype // true |
同时让我们更加深入的验证一些东西:
1 | Person.__proto__ === Function.prototype // true |
我们会发现Person是Function对象的实例,Function是Object对象的实例,Person原型是Object对象的实例。这证明了我们开篇的观点:JavaScript是一门面向对象的设计语言,在JS里除了null和undefined,其余一切皆为对象。
下面祭出我们的原型链图:

根据我们上面讲述的关于prototype/constructor/__proto__的内容,我相信你可以完全看懂这张图的内容。需要注意两点:
- 构造函数和对象原型一一对应,他们与实例一起作为三要素构成了三面这幅图。最左侧是实例,中间是构造函数,最右侧是对象原型。
- 最最右侧的null告诉我们:Object.prototype.proto = null,也就是Object.prototype是JS中一切对象的根源。其余的对象继承于它,并拥有自己的方法和属性。
6种继承方法
第一种: 原型链继承
利用原型链的特点进行继承
1 | function Super(){ |
优点:
- 可以实现继承。
缺点:
- 子类的原型属性集成了父类实例化对象,所有子类的实例化对象都共享原型对象的属性和方法
1 | var sub1 = new Son(); |
- 子类构造函数实例化对象时,无法传递参数给父类
第二种: 构造函数继承
通过构造函数call方法实现继承。
1 | function Super(){ |
优点:
实现父类实例化对象的独立性
还可以给父类实例化对象添加参数
缺点:
方法都在构造函数中定义,每次实例化对象都得创建一遍方法,基本无法实现函数复用
call方法仅仅调用了父级构造函数的属性及方法,没有办法访问父级构造函数原型对象的属性和方法
第三种: 组合继承
利用原型链继承和构造函数继承的各自优势进行组合使用
1 |
|
优点:
利用原型链继承,实现原型对象方法的继承,允许访问父级构造函数原型对象属性和方法,实现方法复用
利用构造函数继承,实现属性的继承,而且可以传递参数
缺点:
- 创建子类实例对象时,无论什么情况下,都会调用两次父级构造函数:一次是在创建子级原型的时候,另一次是在子级构造函数内部(call)
第四种: 原型式继承
创建一个函数,将参数作为一个对象的原型对象。
1 | function create(obj) { |
ES5规范化了这个原型继承,新增了Object.create()方法,接收两个参数,第一个为原型对象,第二个为要混合进新对象的属性,格式与Object.defineProperties()相同。
1 | Object.create(null, {name: {value: 'Greg', enumerable: true}}); |
优缺点:
- 跟原型链类似
第五种: 寄生继承
在原型式继承的基础上,在函数内部丰富对象
1 | function create(obj) { |
如果使用ES5Object.create来代替create函数的话,可以简化成如下所示:
1 | function Parasitic(obj) { |
优缺点:
- 跟构造函数继承类似,调用一次函数就得创建一遍方法,无法实现函数复用,效率较低
第六种: 寄生组合继承
利用组合继承和寄生继承各自优势
组合继承方法我们已经说了,它的缺点是两次调用父级构造函数,一次是在创建子级原型的时候,另一次是在子级构造函数内部,那么我们只需要优化这个问题就行了,即减少一次调用父级构造函数,正好利用寄生继承的特性,继承父级构造函数的原型来创建子级原型。
1 | function Super(name) { |
这种方式只调用了一次父类构造函数,只在子类上创建一次对象,同时保持原型链,还可以使用instanceof和isPrototypeOf()来判断原型,是我们最理想的继承方式。
第七种: ES6 Class类和extends关键字
ES6引进了class关键字,用于创建类,这里的类是作为ES5构造函数和原型对象的语法糖存在的,其功能大部分都可以被ES5实现,不过在语言层面上ES6也提供了部分支持。新的写法不过让对象原型看起来更加清晰,更像面向对象的语法而已。
1 | //定义类 |
我们看到其中的constructor方法就是之前的构造函数,this就是之前的原型对象,toString()就是定义在原型上的方法,只能使用new关键字来新建实例。语法差别在于我们不需要function关键字和逗号分割符。其中,所有的方法都直接定义在原型上,注意所有的方法都不可枚举。类的内部使用严格模式,并且不存在变量提升,其中的this指向类的实例。
new是从构造函数生成实例的命令。ES6 为new命令引入了一个new.target属性,该属性一般用在构造函数之中,返回new命令作用于的那个构造函数。如果构造函数不是通过new命令调用的,new.target会返回undefined,因此这个属性可以用来确定构造函数是怎么调用的。
类存在静态方法,使用static关键字表示,其只能类和继承的子类来进行调用,不能被实例调用,也就是不能被实例继承,所以我们称它为静态方法。类不存在内部方法和内部属性。
1 | class Foo { |
类通过extends关键字来实现继承,在继承的子类的构造函数里我们使用super关键字来表示对父类构造函数的引用;在静态方法里,super指向父类;在其它函数体内,super表示对父类原型属性的引用。其中super必须在子类的构造函数体内调用一次,因为我们需要调用时来绑定子类的元素对象,否则会报错。
1 | class ColorPoint extends Point { |
前端性能优化
性能优化是把双刃剑,有好的一面也有坏的一面。好的一面就是能提升网站性能,坏的一面就是配置麻烦,或者要遵守的规则太多。并且某些性能优化规则并不适用所有场景,需要谨慎使用。
下面列出来了前端性能的24条建议:
1. 减少 HTTP 请求
一个完整的 HTTP 请求需要经历 DNS 查找,TCP 握手,浏览器发出 HTTP 请求,服务器接收请求,服务器处理请求并发回响应,浏览器接收响应等过程。
接下来看一个具体的例子帮助理解 HTTP :

这是一个 HTTP 请求,请求的文件大小为 28.4KB。
名词解释:
- Queueing: 在请求队列中的时间。
- Stalled: 从TCP 连接建立完成,到真正可以传输数据之间的时间差,此时间包括代理协商时间。
- Proxy negotiation: 与代理服务器连接进行协商所花费的时间。
- DNS Lookup: 执行DNS查找所花费的时间,页面上的每个不同的域都需要进行DNS查找。
- Initial Connection / Connecting: 建立连接所花费的时间,包括TCP握手,重试和协商SSL。
- SSL: 完成SSL握手所花费的时间。
- Request sent: 发出网络请求所花费的时间,通常为一毫秒的时间。
- Waiting(TFFB): TFFB 是发出页面请求到接收到应答数据第一个字节的时间。
- Content Download: 接收响应数据所花费的时间。
从这个例子可以看出,真正下载数据的时间占比为 13.05 / 204.16 = 6.39%,文件越小,这个比例越小,文件越大,比例就越高。这就是为什么要建议将多个小文件合并为一个大文件,从而减少 HTTP 请求次数的原因。
2. 使用 HTTP2
HTTP2 相比 HTTP1.1 有如下几个优点:
解析速度快
服务器解析 HTTP1.1 的请求时,必须不断地读入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP2 是基于帧的协议,每个帧都有表示帧长度的字段。
多路复用
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。 多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。
首部压缩
HTTP2 提供了首部压缩功能。
例如有如下两个请求:
1 | // 请求1 |
从上面两个请求可以看出来,有很多数据都是重复的。如果可以把相同的首部存储起来,仅发送它们之间不同的部分,就可以节省不少的流量,加快请求的时间。
HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。
下面再来看一个简化的例子,假设客户端按顺序发送如下请求首部:
1 | Header1:foo |
当客户端发送请求时,它会根据首部值创建一张表:
| 索引 | 首部名称 | 值 |
|---|---|---|
| 62 | Header1 | foo |
| 63 | Header2 | bar |
| 64 | Header3 | bar |
如果服务器收到了请求,它会照样创建一张表。 当客户端发送下一个请求的时候,如果首部相同,它可以直接发送这样的首部块:
1 | 62 63 64 |
服务器会查找先前建立的表格,并把这些数字还原成索引对应的完整首部。
优先级
HTTP2 可以对比较紧急的请求设置一个较高的优先级,服务器在收到这样的请求后,可以优先处理。
流量控制
由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少。流量控制可以对不同的流的流量进行精确控制。
服务器推送
HTTP2 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确地请求。
例如当浏览器请求一个网站时,除了返回 HTML 页面外,服务器还可以根据 HTML 页面中的资源的 URL,来提前推送资源。
现在有很多网站已经开始使用 HTTP2 了,例如知乎:

其中 h2 是指 HTTP2 协议,http/1.1 则是指 HTTP1.1 协议。
参考资料:
3. 使用服务端渲染
客户端渲染: 获取 HTML 文件,根据需要下载 JavaScript 文件,运行文件,生成 DOM,再渲染。
服务端渲染:服务端返回 HTML 文件,客户端只需解析 HTML。
- 优点:首屏渲染快,SEO 好。
- 缺点:配置麻烦,增加了服务器的计算压力。
下面我用 Vue SSR 做示例,简单的描述一下 SSR 过程。
客户端渲染过程
- 访问客户端渲染的网站。
- 服务器返回一个包含了引入资源语句和 <div id=”app”></div> 的 HTML 文件。
- 客户端通过 HTTP 向服务器请求资源,当必要的资源都加载完毕后,执行 new Vue() 开始实例化并渲染页面。
服务端渲染过程
- 访问服务端渲染的网站。
- 服务器会查看当前路由组件需要哪些资源文件,然后将这些文件的内容填充到 HTML 文件。如果有 ajax 请求,就会执行它进行数据预取并填充到 HTML 文件里,最后返回这个 HTML 页面。
- 当客户端接收到这个 HTML 页面时,可以马上就开始渲染页面。与此同时,页面也会加载资源,当必要的资源都加载完毕后,开始执行 new Vue() 开始实例化并接管页面。
从上述两个过程中可以看出,区别就在于第二步。客户端渲染的网站会直接返回 HTML 文件,而服务端渲染的网站则会渲染完页面再返回这个 HTML 文件。
这样做的好处是什么?是更快的内容到达时间 (time-to-content)。
假设你的网站需要加载完 abcd 四个文件才能渲染完毕。并且每个文件大小为 1 M。
这样一算:客户端渲染的网站需要加载 4 个文件和 HTML 文件才能完成首页渲染,总计大小为 4M(忽略 HTML 文件大小)。而服务端渲染的网站只需要加载一个渲染完毕的 HTML 文件就能完成首页渲染,总计大小为已经渲染完毕的 HTML 文件(这种文件不会太大,一般为几百K,我的个人博客网站(SSR)加载的 HTML 文件为 400K)。这就是服务端渲染更快的原因。
参考资料:
4. 静态资源使用 CDN
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。我们都知道,当服务器离用户越远时,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
CDN 原理
当用户访问一个网站时,如果没有 CDN,过程是这样的:
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到网站服务器的 IP 地址。
- 本地 DNS 将 IP 地址发回给浏览器,浏览器向网站服务器 IP 地址发出请求并得到资源。

如果用户访问的网站部署了 CDN,过程是这样的:
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到全局负载均衡系统(GSLB)的 IP 地址。
- 本地 DNS 再向 GSLB 发出请求,GSLB 的主要功能是根据本地 DNS 的 IP 地址判断用户的位置,筛选出距离用户较近的本地负载均衡系统(SLB),并将该 SLB 的 IP 地址作为结果返回给本地 DNS。
- 本地 DNS 将 SLB 的 IP 地址发回给浏览器,浏览器向 SLB 发出请求。
- SLB 根据浏览器请求的资源和地址,选出最优的缓存服务器发回给浏览器。
- 浏览器再根据 SLB 发回的地址重定向到缓存服务器。
- 如果缓存服务器有浏览器需要的资源,就将资源发回给浏览器。如果没有,就向源服务器请求资源,再发给浏览器并缓存在本地。

参考资料:
5. 将 CSS 放在文件头部,JavaScript 文件放在底部
所有放在 head 标签里的 CSS 和 JS 文件都会堵塞渲染。如果这些 CSS 和 JS 需要加载和解析很久的话,那么页面就空白了。所以 JS 文件要放在底部,等 HTML 解析完了再加载 JS 文件。
那为什么 CSS 文件还要放在头部呢?
因为先加载 HTML 再加载 CSS,会让用户第一时间看到的页面是没有样式的、“丑陋”的,为了避免这种情况发生,就要将 CSS 文件放在头部了。
另外,JS 文件也不是不可以放在头部,只要给 script 标签加上 defer 属性就可以了,异步下载,延迟执行。
6. 使用字体图标 iconfont 代替图片图标
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如 font-size、color 等等,非常方便。并且字体图标是矢量图,不会失真。还有一个优点是生成的文件特别小。
压缩字体文件
使用 fontmin-webpack 插件对字体文件进行压缩。

参考资料:
7. 善用缓存,不重复加载相同的资源
为了避免用户每次访问网站都得请求文件,我们可以通过添加 Expires 或 max-age 来控制这一行为。Expires 设置了一个时间,只要在这个时间之前,浏览器都不会请求文件,而是直接使用缓存。而 max-age 是一个相对时间,建议使用 max-age 代替 Expires 。
不过这样会产生一个问题,当文件更新了怎么办?怎么通知浏览器重新请求文件?
可以通过更新页面中引用的资源链接地址,让浏览器主动放弃缓存,加载新资源。
具体做法是把资源地址 URL 的修改与文件内容关联起来,也就是说,只有文件内容变化,才会导致相应 URL 的变更,从而实现文件级别的精确缓存控制。什么东西与文件内容相关呢?我们会很自然的联想到利用数据摘要要算法对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据了。
参考资料:
8. 压缩文件
压缩文件可以减少文件下载时间,让用户体验性更好。
得益于 webpack 和 node 的发展,现在压缩文件已经非常方便了。
在 webpack 可以使用如下插件进行压缩:
- JavaScript:UglifyPlugin
- CSS :MiniCssExtractPlugin
- HTML:HtmlWebpackPlugin
其实,我们还可以做得更好。那就是使用 gzip 压缩。可以通过向 HTTP 请求头中的 Accept-Encoding 头添加 gzip 标识来开启这一功能。当然,服务器也得支持这一功能。
gzip 是目前最流行和最有效的压缩方法。举个例子,我用 Vue 开发的项目构建后生成的 app.js 文件大小为 1.4MB,使用 gzip 压缩后只有 573KB,体积减少了将近 60%。
附上 webpack 和 node 配置 gzip 的使用方法。
下载插件
1 | npm install compression-webpack-plugin --save-dev |
webpack 配置
1 | const CompressionPlugin = require('compression-webpack-plugin'); |
node 配置
1 | const compression = require('compression') |
9. 图片优化
(1). 图片延迟加载
在页面中,先不给图片设置路径,只有当图片出现在浏览器的可视区域时,才去加载真正的图片,这就是延迟加载。对于图片很多的网站来说,一次性加载全部图片,会对用户体验造成很大的影响,所以需要使用图片延迟加载。
首先可以将图片这样设置,在页面不可见时图片不会加载:
1 | <img data-src="https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4"> |
等页面可见时,使用 JS 加载图片:
1 | const img = document.querySelector('img') |
这样图片就加载出来了,完整的代码可以看一下参考资料。
参考资料:
(2). 响应式图片
响应式图片的优点是浏览器能够根据屏幕大小自动加载合适的图片。
通过 picture 实现
1 | <picture> |
通过 @media 实现
1 | @media (min-width: 769px) { |
(3). 调整图片大小
例如,你有一个 1920 * 1080 大小的图片,用缩略图的方式展示给用户,并且当用户鼠标悬停在上面时才展示全图。如果用户从未真正将鼠标悬停在缩略图上,则浪费了下载图片的时间。
所以,我们可以用两张图片来实行优化。一开始,只加载缩略图,当用户悬停在图片上时,才加载大图。还有一种办法,即对大图进行延迟加载,在所有元素都加载完成后手动更改大图的 src 进行下载。
(4). 降低图片质量
例如 JPG 格式的图片,100% 的质量和 90% 质量的通常看不出来区别,尤其是用来当背景图的时候。我经常用 PS 切背景图时, 将图片切成 JPG 格式,并且将它压缩到 60% 的质量,基本上看不出来区别。
压缩方法有两种,一是通过 webpack 插件 image-webpack-loader,二是通过在线网站进行压缩。
以下附上 webpack 插件 image-webpack-loader 的用法。
1 | npm install --save-dev image-webpack-loader |
webpack 配置
1 | { |
参考资料:
(5). 尽可能利用 CSS3 效果代替图片
有很多图片使用 CSS 效果(渐变、阴影等)就能画出来,这种情况选择 CSS3 效果更好。因为代码大小通常是图片大小的几分之一甚至几十分之一。
(6). 使用 webp 格式的图片
WebP 的优势体现在它具有更优的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性,在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一。
参考资料:
10. 通过 webpack 按需加载代码,提取第三库代码,减少 ES6 转为 ES5 的冗余代码
懒加载或者按需加载,是一种很好的优化网页或应用的方式。这种方式实际上是先把你的代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用另外一些新的代码块。这样加快了应用的初始加载速度,减轻了它的总体体积,因为某些代码块可能永远不会被加载。
根据文件内容生成文件名,结合 import 动态引入组件实现按需加载
通过配置 output 的 filename 属性可以实现这个需求。filename 属性的值选项中有一个 [contenthash],它将根据文件内容创建出唯一 hash。当文件内容发生变化时,[contenthash] 也会发生变化。
1 | { |
提取第三方库
由于引入的第三方库一般都比较稳定,不会经常改变。所以将它们单独提取出来,作为长期缓存是一个更好的选择。 这里需要使用 webpack4 的 splitChunk 插件 cacheGroups 选项。
1 | optimization: { |
- test: 过滤 modules,默认为所有的 modules,可匹配模块路径或 chunk 名字,当匹配到某个 chunk 的名字时,这个 chunk 里面引入的所有 module 都会选中。可以传递的值类型:RegExp、String和Function。
- priority: 权重,数字越大表示优先级越高。一个 module 可能会满足多个 cacheGroups 的正则匹配,到底将哪个缓存组应用于这个 module,取决于优先级。
- reuseExistingChunk: 表示是否使用已有的 chunk,true 则表示如果当前的 chunk 包含的模块已经被抽取出去了,那么将不会重新生成新的,即几个 chunk 复用被拆分出去的一个 module。
- minChunks(默认是1): 在分割之前,这个代码块最小应该被引用的次数(译注:保证代码块复用性,默认配置的策略是不需要多次引用也可以被分割)
- chunks(默认是async): initial、async和all。chunks改为all,表示同时对静态加载(initial)和动态加载(async)起作用。
- name(打包的chunks的名字): 字符串或者函数(函数可以根据条件自定义名字)
减少 ES6 转为 ES5 的冗余代码
Babel 转化后的代码想要实现和原来代码一样的功能需要借助一些帮助函数,比如
1 | class Person {} |
会被转换为:
1 | ; |
这里 _classCallCheck 就是一个 helper 函数,如果在很多文件里都声明了类,那么就会产生很多个这样的 helper 函数。
这里的 @babel/runtime 包就声明了所有需要用到的帮助函数,而 @babel/plugin-transform-runtime 的作用就是将所有需要 helper 函数的文件,从 @babel/runtime包引进来:
1 | ; |
这里就没有再编译出 helper 函数 classCallCheck 了,而是直接引用了 @babel/runtime 中的 helpers/classCallCheck。
安装
1 | npm install --save-dev @babel/plugin-transform-runtime @babel/runtime |
使用 在 .babelrc 文件中
1 | { |
参考资料:
- Babel 7.1介绍 transform-runtime polyfill env
- webpack 懒加载
- Vue 路由懒加载
- webpack 缓存
- 一步一步的了解webpack4的splitChunk插件
11. 减少重绘重排
浏览器渲染过程
- 解析HTML生成DOM树。
- 解析CSS生成CSSOM规则树。
- 将DOM树与CSSOM规则树合并在一起生成渲染树。
- 遍历渲染树开始布局,计算每个节点的位置大小信息。
- 将渲染树每个节点绘制到屏幕。

重排
当改变 DOM 元素位置或大小时,会导致浏览器重新生成渲染树,这个过程叫重排。
重绘
当重新生成渲染树后,就要将渲染树每个节点绘制到屏幕,这个过程叫重绘。不是所有的动作都会导致重排,例如改变字体颜色,只会导致重绘。记住,重排会导致重绘,重绘不会导致重排。
重排和重绘这两个操作都是非常昂贵的,因为 JavaScript 引擎线程与 GUI 渲染线程是互斥,它们同时只能一个在工作。
什么操作会导致重排?
- 添加或删除可见的 DOM 元素
- 元素位置改变
- 元素尺寸改变
- 内容改变
- 浏览器窗口尺寸改变
如何减少重排重绘?
- 用 JavaScript 修改样式时,最好不要直接写样式,而是替换 class 来改变样式。
- 如果要对 DOM 元素执行一系列操作,可以将 DOM 元素脱离文档流,修改完成后,再将它带回文档。推荐使用隐藏元素(display:none)或文档碎片(DocumentFragment),都能很好的实现这个方案。
12. 使用事件委托
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术, 使用事件委托可以节省内存。
1 | <ul> |
1 | // good |
13. 注意程序的局部性
一个编写良好的计算机程序常常具有良好的局部性,它们倾向于引用最近引用过的数据项附近的数据项,或者最近引用过的数据项本身,这种倾向性,被称为局部性原理。有良好局部性的程序比局部性差的程序运行得更快。
局部性通常有两种不同的形式:
- 时间局部性: 在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来被多次引用。
- 空间局部性: 在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
时间局部性示例
1 | function sum(arry) { |
在这个例子中,变量sum在每次循环迭代中被引用一次,因此,对于sum来说,具有良好的时间局部性
空间局部性示例
具有良好空间局部性的程序
1 | // 二维数组 |
空间局部性差的程序
1 | // 二维数组 |
看一下上面的两个空间局部性示例,像示例中从每行开始按顺序访问数组每个元素的方式,称为具有步长为1的引用模式。 如果在数组中,每隔k个元素进行访问,就称为步长为k的引用模式。 一般而言,随着步长的增加,空间局部性下降。
这两个例子有什么区别?区别在于第一个示例是按行扫描数组,每扫描完一行再去扫下一行;第二个示例是按列来扫描数组,扫完一行中的一个元素,马上就去扫下一行中的同一列元素。
数组在内存中是按照行顺序来存放的,结果就是逐行扫描数组的示例得到了步长为 1 引用模式,具有良好的空间局部性;而另一个示例步长为 rows,空间局部性极差。
性能测试
运行环境:
- cpu: i7-10510U
- 浏览器: 83.0.4103.61
对一个长度为9000的二维数组(子数组长度也为9000)进行10次空间局部性测试,时间(毫秒)取平均值,结果如下:
1 | function sum2(arry, rows, cols) { |
所用示例为上述两个空间局部性示例
| 步长为1(sum1) | 步长为9000(sum2) |
|---|---|
| 81.5ms | 167.3ms |
从以上测试结果来看,步长为 1 的数组执行时间比步长为 9000 的数组快了一个数量级。
总结:
- 重复引用相同变量的程序具有良好的时间局部性
- 对于具有步长为 k 的引用模式的程序,步长越小,空间局部性越好;而在内存中以大步长跳来跳去的程序空间局部性会很差
参考资料:
14. if-else 对比 switch
当判断条件数量越来越多时,越倾向于使用 switch 而不是 if-else。
1 | if (color == 'blue') { |
像以上这种情况,使用 switch 是最好的。假设 color 的值为 pink,则 if-else 语句要进行 7 次判断,switch 只需要进行一次判断。 从可读性来说,switch 语句也更好。
从使用时机来说,当条件值大于两个的时候,使用 switch 更好。不过 if-else 也有 switch 无法做到的事情,例如有多个判断条件的情况下,无法使用 switch。
15. 查找表
当条件语句特别多时,使用 switch 和 if-else 不是最佳的选择,这时不妨试一下查找表。查找表可以使用数组和对象来构建。
1 | switch (index) { |
可以将这个 switch 语句转换为查找表
1 | const results = [result0,result1,result2,result3,result4,result5,result6,result7,result8,result9,result10,result11]; |
如果条件语句不是数值而是字符串,可以用对象来建立查找表
1 | const map = { |
16. 避免页面卡顿
60fps 与设备刷新率
目前大多数设备的屏幕刷新率为 60 次/秒。因此,如果在页面中有一个动画或渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。 其中每个帧的预算时间仅比 16 毫秒多一点 (1 秒/ 60 = 16.66 毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作需要在 10 毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。 此现象通常称为卡顿,会对用户体验产生负面影响。

假如你用 JavaScript 修改了 DOM,并触发样式修改,经历重排重绘最后画到屏幕上。如果这其中任意一项的执行时间过长,都会导致渲染这一帧的时间过长,平均帧率就会下降。假设这一帧花了 50 ms,那么此时的帧率为 1s / 50ms = 20fps,页面看起来就像卡顿了一样。
对于一些长时间运行的 JavaScript,我们可以使用定时器进行切分,延迟执行。
1 | for (let i = 0, len = arry.length; i < len; i++) { |
假设上面的循环结构由于 process() 复杂度过高或数组元素太多,甚至两者都有,可以尝试一下切分。
1 | const todo = arry.concat(); |
如果有兴趣了解更多,可以查看一下高性能JavaScript第 6 章和高效前端:Web高效编程与优化实践第 3 章。
17. 使用 requestAnimationFrame 来实现视觉变化
从第 16 点我们可以知道,大多数设备屏幕刷新率为 60 次/秒,也就是说每一帧的平均时间为 16.66 毫秒。在使用 JavaScript 实现动画效果的时候,最好的情况就是每次代码都是在帧的开头开始执行。而保证 JavaScript 在帧开始时运行的唯一方式是使用 requestAnimationFrame。
1 | /** |
如果采取 setTimeout 或 setInterval 来实现动画的话,回调函数将在帧中的某个时点运行,可能刚好在末尾,而这可能经常会使我们丢失帧,导致卡顿。

18. 使用 Web Workers
Web Worker 使用其他工作线程从而独立于主线程之外,它可以执行任务而不干扰用户界面。一个 worker 可以将消息发送到创建它的 JavaScript 代码, 通过将消息发送到该代码指定的事件处理程序(反之亦然)。
Web Worker 适用于那些处理纯数据,或者与浏览器 UI 无关的长时间运行脚本。
创建一个新的 worker 很简单,指定一个脚本的 URI 来执行 worker 线程(main.js):
1 | var myWorker = new Worker('worker.js'); |
在 worker 中接收到消息后,我们可以写一个事件处理函数代码作为响应(worker.js):
1 | onmessage = function(e) { |
onmessage处理函数在接收到消息后马上执行,代码中消息本身作为事件的data属性进行使用。这里我们简单的对这2个数字作乘法处理并再次使用postMessage()方法,将结果回传给主线程。
回到主线程,我们再次使用onmessage以响应worker回传的消息:
1 | myWorker.onmessage = function(e) { |
在这里我们获取消息事件的data,并且将它设置为result的textContent,所以用户可以直接看到运算的结果。
不过在worker内,不能直接操作DOM节点,也不能使用window对象的默认方法和属性。然而你可以使用大量window对象之下的东西,包括WebSockets,IndexedDB以及FireFox OS专用的Data Store API等数据存储机制。
参考资料:
19. 使用位操作
JavaScript 中的数字都使用 IEEE-754 标准以 64 位格式存储。但是在位操作中,数字被转换为有符号的 32 位格式。即使需要转换,位操作也比其他数学运算和布尔操作快得多。
取模
由于偶数的最低位为 0,奇数为 1,所以取模运算可以用位操作来代替。
1 | if (value % 2) { |
取整
1 | ~~10.12 // 10 |
位掩码
1 | const a = 1 |
通过定义这些选项,可以用按位与操作来判断 a/b/c 是否在 options 中。
1 | // 选项 b 是否在选项中 |
20. 不要覆盖原生方法
无论你的 JavaScript 代码如何优化,都比不上原生方法。因为原生方法是用低级语言写的(C/C++),并且被编译成机器码,成为浏览器的一部分。当原生方法可用时,尽量使用它们,特别是数学运算和 DOM 操作。
21. 降低 CSS 选择器的复杂性
(1). 浏览器读取选择器,遵循的原则是从选择器的右边到左边读取
看个示例
1 | #block .text p { |
- 查找所有 P 元素。
- 查找结果 1 中的元素是否有类名为 text 的父元素
- 查找结果 2 中的元素是否有 id 为 block 的父元素
(2). CSS 选择器优先级
1 | 内联 > ID选择器 > 类选择器 > 标签选择器 |
根据以上两个信息可以得出结论。
- 选择器越短越好。
- 尽量使用高优先级的选择器,例如 ID 和类选择器。
- 避免使用通配符 *。
最后要说一句,据我查找的资料所得,CSS 选择器没有优化的必要,因为最慢和慢快的选择器性能差别非常小。
22. 使用 flexbox 而不是较早的布局模型
在早期的 CSS 布局方式中我们能对元素实行绝对定位、相对定位或浮动定位。而现在,我们有了新的布局方式 flexbox,它比起早期的布局方式来说有个优势,那就是性能比较好。
下面的截图显示了在 1300 个框上使用浮动的布局开销:

然后我们用 flexbox 来重现这个例子:

现在,对于相同数量的元素和相同的视觉外观,布局的时间要少得多(本例中为分别 3.5 毫秒和 14 毫秒)。
不过 flexbox 兼容性还是有点问题,不是所有浏览器都支持它,所以要谨慎使用。
各浏览器兼容性:
- Chrome 29+
- Firefox 28+
- Internet Explorer 11
- Opera 17+
- Safari 6.1+ (prefixed with -webkit-)
- Android 4.4+
- iOS 7.1+ (prefixed with -webkit-)
但是在可能的情况下,至少应研究布局模型对网站性能的影响,并且采用最大程度减少网页执行开销的模型。
在任何情况下,不管是否选择 Flexbox,都应当在应用的高压力点期间尝试完全避免触发布局!
23. 使用 transform 和 opacity 属性更改来实现动画
在 CSS 中,transforms 和 opacity 这两个属性更改不会触发重排与重绘,它们是可以由合成器(composite)单独处理的属性。

24. 合理使用规则,避免过度优化
性能优化主要分为两类:
- 加载时优化
- 运行时优化
上述 23 条建议中,属于加载时优化的是前面 10 条建议,属于运行时优化的是后面 13 条建议。通常来说,没有必要 23 条性能优化规则都用上,根据网站用户群体来做针对性的调整是最好的,节省精力,节省时间。
在解决问题之前,得先找出问题,否则无从下手。所以在做性能优化之前,最好先调查一下网站的加载性能和运行性能。
检查加载性能
一个网站加载性能如何主要看白屏时间和首屏时间。
- 白屏时间:指从输入网址,到页面开始显示内容的时间。
- 首屏时间:指从输入网址,到页面完全渲染的时间。
将以下脚本放在 </head> 前面就能获取白屏时间。
1 | <script> |
在 window.onload 事件里执行 new Date() - performance.timing.navigationStart 即可获取首屏时间。
检查运行性能
配合 chrome 的开发者工具,我们可以查看网站在运行时的性能。
打开网站,按 F12 选择 performance,点击左上角的灰色圆点,变成红色就代表开始记录了。这时可以模仿用户使用网站,在使用完毕后,点击 stop,然后你就能看到网站运行期间的性能报告。如果有红色的块,代表有掉帧的情况;如果是绿色,则代表 FPS 很好。performance 的具体使用方法请用搜索引擎搜索一下,毕竟篇幅有限。
通过检查加载和运行性能,相信你对网站性能已经有了大概了解。所以这时候要做的事情,就是使用上述 23 条建议尽情地去优化你的网站,加油!
参考资料:
其他参考资料
- 高性能网站建设指南
- Web性能权威指南
- 高性能JavaScript
- 高效前端:Web高效编程与优化实践
如何进行网站性能优化
雅虎 Best Practices for Speeding Up Your Web Site:
content 方面
- 减少 HTTP 请求:合并文件、CSS 精灵、inline Image
- 减少 DNS 查询:DNS 查询完成之前浏览器不能从这个主机下载任何任何文件。方法:DNS 缓存、将资源分布到恰当数量的主机名,平衡并行下载和 DNS 查询
- 避免重定向:多余的中间访问
- 使 Ajax 可缓存
- 非必须组件延迟加载
- 未来所需组件预加载
- 减少 DOM 元素数量
- 将资源放到不同的域下:浏览器同时从一个域下载资源的数目有限,增加域可以提高并行下载量
- 减少 iframe 数量
- 不要 404
Server 方面
- 使用 CDN
- 添加 Expires 或者 Cache-Control 响应头
- 对组件使用 Gzip 压缩
- 配置 ETag
- Flush Buffer Early
- Ajax 使用 GET 进行请求
- 避免空 src 的 img 标签
Cookie 方面
- 减小 cookie 大小
- 引入资源的域名不要包含 cookie
css 方面
- 将样式表放到页面顶部
- 不使用 CSS 表达式
- 使用
<link>不使用@import - 不使用 IE 的 Filter
Javascript 方面
- 将脚本放到页面底部
- 将 javascript 和 css 从外部引入
- 压缩 javascript 和 css
- 删除不需要的脚本
- 减少 DOM 访问
- 合理设计事件监听器
图片方面
- 优化图片:根据实际颜色需要选择色深、压缩
- 优化 css 精灵
- 不要在 HTML 中拉伸图片
- 保证 favicon.ico 小并且可缓存
移动方面
- 保证组件小于 25k
- Pack Components into a Multipart Document
强缓存与协商缓存
浏览器缓存
当浏览器去请求某个文件的时候,服务端就在response header里面对该文件做了缓存配置。缓存的时间、缓存类型都由服务端控制
缓存优点
- 减少不必要的数据传输,节省带宽
- 减少服务器的负担,提升网站性能
- 加快了客户端加载网页的速度,用户体验友好
缓存缺点
资源如果有更改,会导致客户端不及时更新就会造成用户获取信息滞后
缓存流程
浏览器第一次请求时

浏览器后续在进行请求时

从上图可以知道,浏览器缓存包括两种类型,即强缓存(本地缓存)和协商缓存,浏览器在第一次请求发生后,再次请求时
- 浏览器在请求某一资源时,会先获取该资源缓存的header信息,判断是否命中强缓存(
cache-control和expires信息),若命中直接从缓存中获取资源信息,包括缓存header信息;本次请求根本就不会与服务器进行通信。
请求头信息
1 | Accept: xxx |
来自缓存的响应头的信息
1 | Accept-Ranges: bytes |
- 如果没有命中强缓存,浏览器会发送请求到服务器,请求会携带第一次请求返回的有关缓存的header字段信息(
Last-Modified/If-Modified-Since和Etag/If-None-Match),由服务器根据请求中的相关header信息来比对结果是否协商缓存命中;若命中,则服务器返回新的响应header信息更新缓存中的对应header信息,但是并不返回资源内容,它会告知浏览器可以直接从缓存获取;否则返回最新的资源内容。
强缓存与协商缓存的区别,可以用下表来进行描述:
| 获取资源形式 | 状态码 | 发送请求到服务器 | |
|---|---|---|---|
| 强缓存 | 从缓存取 | 200(from cache) | 否,直接从缓存取 |
| 协商缓存 | 从缓存取 | 304(not modified) | 是,正如其名,通过服务器来告知缓存是否可用 |
强缓存相关的header字段
强缓存上面已经介绍了,直接从缓存中获取资源而不经过服务器;与强缓存相关的header字段有两个:
- expires: 这是http1.0时的规范;它的值为一个绝对时间的GMT格式的时间字符串,如Mon, 10 Jun 2015 21:31:12 GMT,如果发送请求的时间在expires之前,那么本地缓存始终有效,否则就会发送请求到服务器来获取资源。
- cache-control:max-age=number: 这是http1.1时出现的header信息,主要是利用该字段的max-age值来进行判断,它是一个相对值;资源第一次的请求时间和Cache-Control设定的有效期,计算出一个资源过期时间,再拿这个过期时间跟当前的请求时间比较,如果请求时间在过期时间之前,就能命中缓存,否则就不行;cache-control除了该字段外,还有下面几个比较常用的设置值:
- no-cache: 不使用本地缓存。需要使用缓存协商,先与服务器确认返回的响应是否被更改,如果之前的响应中存在ETag,那么请求的时候会与服务端验证,如果资源未被更改,则可以避免重新下载。
- no-store: 直接禁止游览器缓存数据,每次用户请求该资源,都会向服务器发送一个请求,每次都会下载完整的资源。
- public: 可以被所有的用户缓存,包括终端用户和CDN等中间代理服务器。
- private: 只能被终端用户的浏览器缓存,不允许CDN等中继缓存服务器对其缓存。
注意:如果cache-control与expires同时存在的话,cache-control的优先级高于expires。
协商缓存相关的header字段
协商缓存都是由服务器来确定缓存资源是否可用的,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问,这主要涉及到下面两组header字段,这两组搭档都是成对出现的,即第一次请求的响应头带上某个字段(Last-Modified或者Etag),则后续请求则会带上对应的请求字段(If-Modified-Since或者If-None-Match),若响应头没有Last-Modified或者Etag字段,则请求头也不会有对应的字段。
1. Last-Modified/If-Modified-Since
二者的值都是GMT格式的时间字符串,具体过程:
浏览器第一次跟服务器请求一个资源,服务器在返回这个资源的同时,在response的header加上
Last-Modified的header,这个header表示这个资源在服务器上的最后修改时间浏览器再次跟服务器请求这个资源时,在request的header上加上
If-Modified-Since的header,这个header的值就是上一次请求时返回的Last-Modified的值服务器再次收到资源请求时,根据浏览器传过来
If-Modified-Since和资源在服务器上的最后修改时间判断资源是否有变化,如果没有变化则返回304 Not Modified,但是不会返回资源内容;如果有变化,就正常返回资源内容。当服务器返回304 Not Modified的响应时,response header中不会再添加Last-Modified的header,因为既然资源没有变化,那么Last-Modified也就不会改变,这是服务器返回304时的response header浏览器收到304的响应后,就会从缓存中加载资源
如果协商缓存没有命中,浏览器直接从服务器加载资源时,
Last-Modified的Header在重新加载的时候会被更新,下次请求时,If-Modified-Since会启用上次返回的Last-Modified值
2. Etag/If-None-Match
这两个值是由服务器生成的每个资源的唯一标识字符串,只要资源有变化就这个值就会改变;其判断过程与Last-Modified/If-Modified-Since类似,与Last-Modified不一样的是,当服务器返回304 Not Modified的响应时,由于ETag重新生成过,response header中还会把这个ETag返回,即使这个ETag跟之前的没有变化。
既生Last-Modified何生Etag
你可能会觉得使用Last-Modified已经足以让浏览器知道本地的缓存副本是否足够新,为什么还需要Etag呢?HTTP1.1中Etag的出现主要是为了解决几个Last-Modified比较难解决的问题:
一些文件也许会周期性的更改,但是他的内容并不改变(仅仅改变的修改时间),这个时候我们并不希望客户端认为这个文件被修改了,而重新GET;
某些文件修改非常频繁,比如在秒以下的时间内进行修改,(比方说1s内修改了N次),If-Modified-Since能检查到的粒度是s级的,这种修改无法判断(或者说UNIX记录MTIME只能精确到秒);
某些服务器不能精确的得到文件的最后修改时间。
这时,利用Etag能够更加准确的控制缓存,因为Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符。
注意: Last-Modified与ETag是可以一起使用的,服务器会优先验证ETag,一致的情况下,才会继续比对Last-Modified,最后才决定是否返回304。
用户的行为对缓存的影响
| 用户操作 | Expires/Cache-Control | Last-Modified/ETag |
|---|---|---|
| 地址栏回车 | 有效 | 有效 |
| 页面链接条状 | 有效 | 有效 |
| 新开窗口 | 有效 | 有效 |
| 前进后退 | 有效 | 有效 |
| F5刷新 | 无效 | 有效 |
| Ctrl + F5强制刷新 | 无效 | 无效 |
强缓存如何重新加载缓存缓存过的资源
使用强缓存时,浏览器不会发送请求到服务端,根据设置的缓存时间浏览器一直从缓存中获取资源,在这期间若资源产生了变化,浏览器就在缓存期内就一直得不到最新的资源,那么如何防止这种事情发生呢?
通过更新页面中引用的资源路径,让浏览器主动放弃缓存,加载新资源。
1 | <link rel="stylesheet" href="a.css?a=1.0" /> |
这样每次文件改变后就会生成新的query值,这样query值不同,也就是页面引用的资源路径不同了,之前缓存过的资源就被浏览器忽略了,因为资源请求的路径变了。
HTTP 各版本特点与区别
HTTP协议到现在为止总共经历了3个版本的演化,第一个HTTP协议诞生于1989年3月。
| 版本 | 功能 | 备注 |
|---|---|---|
| HTTP 0.9 | 仅支持 Get 仅能访问 HTML 格式资源 |
简单单一 |
| HTTP 1.0 | 新增POST,DELETE,PUT,HEADER等方式 增加请求头和响应头概念,指定协议版本号,携带其他元信息(状态码、权限、缓存、内容编码) 扩展传输内容格式(图片、音视频、二进制等都可以传输) |
存活时间短 |
| HTTP 1.1 | 长连接:新增 Connection 字段,可以通过keep-alive保持长连接 管道化:一次连接就形成一次管道,管道内进行多次有序响应。允许向服务端发生多次请求,但是响应按序返回 缓存处理:新增 cache-control 和 etag 首部字段 断点续传 状态码增加 |
当前主流版本号 存在Header 重复问题 |
| HTTP 2.0 | 二进制分帧:数据体和头信息可以都是二进制,统称帧 多路复用与数据流:能同时发送和响应多个请求,通过数据流来传输 头部压缩:对 Header 进行压缩,避免重复浪费 服务器推送:服务器可以向客户端主动发送资源 |
2005发布 |
1、HTTP 0.9
HTTP 0.9是第一个版本的HTTP协议,已过时。它的组成极其简单,只允许客户端发送GET这一种请求,且不支持请求头。由于没有协议头,造成了HTTP 0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。
HTTP 0.9具有典型的无状态性,每个事务独立进行处理,事务结束时就释放这个连接。由此可见,HTTP协议的无状态特点在其第一个版本0.9中已经成型。一次HTTP 0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。
2、HTTP 1.0
HTTP协议的第二个版本,第一个在通讯中指定版本号的HTTP协议版本,至今仍被广泛采用。相对于HTTP 0.9 增加了如下主要特性:
- 请求与响应支持头域
- 响应对象以一个响应状态行开始
- 响应对象不只限于超文本
- 开始支持客户端通过POST方法向Web服务器提交数据,支持GET、HEAD、POST方法
- (短连接)每一个请求建立一个TCP连接,请求完成后立马断开连接。这将会导致2个问题:连接无法复用,队头阻塞(head of line blocking)。连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类请求影响较大。队头阻塞(head of line blocking)
3、HTTP 1.1
HTTP协议的第三个版本是HTTP 1.1,是目前使用最广泛的协议版本 。HTTP 1.1是目前主流的HTTP协议版本,因此这里就多花一些笔墨介绍一下HTTP 1.1的特性。
HTTP 1.1引入了许多关键性能优化:keepalive连接,chunked编码传输,字节范围请求,请求流水线等
Persistent Connection(keepalive连接)
允许HTTP设备在事务处理结束之后将TCP连接保持在打开的状态,以便未来的HTTP请求重用现在的连接,直到客户端或服务器端决定将其关闭为止。在HTTP1.0中使用长连接需要添加请求头 Connection: Keep-Alive,而在HTTP 1.1 所有的连接默认都是长连接,除非特殊声明不支持( HTTP请求报文首部加上Connection: close )。服务器端按照FIFO原则来处理不同的Request。

chunked编码传输
该编码将实体分块传送并逐块标明长度,直到长度为0块表示传输结束,这在实体长度未知时特别有用(比如由数据库动态产生的数据)
字节范围请求
HTTP1.1支持传送内容的一部分。比方说,当客户端已经有内容的一部分,为了节省带宽,可以只向服务器请求一部分。该功能通过在请求消息中引入了range头域来实现,它允许只请求资源的某个部分。在响应消息中Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码206(Partial Content)
断点续传
Header 字段
服务端
Accept-Ranges:表示服务器支持断点续传,并且数据传输以字节为单位
Etag:资源的唯一 tag 后端自定义,验证文件是否修改过。修改过就重新重头传输
Last-Modified:文件上次修改时间
Content-Range:返回数据范围
客户端
If-Range:服务器给的 Etag 值
Range:请求的数据范围
If-Modified-Since: 将服务器响应的 Last-Modified 保存, 下次发送可以携带,后台接受判断文件是否修改,没有可以返回 304状态码,叫客户端使用缓存数据,避免重复发出资源。
流程

注意:断点续传后台返回状态码为 206。
Pipelining(请求流水线)
其他特性
另外,HTTP 1.1还新增了如下特性:
请求消息和响应消息都支持Host头域:在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。因此,Host头的引入就很有必要了。
新增了一批Request method:HTTP1.1增加了OPTIONS, PUT, DELETE, TRACE, CONNECT方法
缓存处理:HTTP/1.1在1.0的基础上加入了一些cache的新特性,引入了实体标签,一般被称为e-tags,新增更为强大的Cache-Control头。
4、HTTP 2.0
HTTP 2.0是下一代HTTP协议。主要特点有:
二进制分帧
HTTP 2.0最大的特点:不会改动HTTP 的语义,HTTP 方法、状态码、URI 及首部字段,等等这些核心概念上一如往常,却能致力于突破上一代标准的性能限制,改进传输性能,实现低延迟和高吞吐量。而之所以叫2.0,是在于新增的二进制分帧层。在二进制分帧层上, HTTP 2.0 会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码 ,其中HTTP1.x的首部信息会被封装到Headers帧,而我们的request body则封装到Data帧里面。

多路复用
HTTP 2.0 通信都在一个连接上完成,这个连接可以承载任意数量的双向数据流。
通过单一的 HTTP2.0连接连续发起多重请求-响应消息,即客户端和服务器可以同时发送多个请求和响应,而不用顺序一一对应。
每个数据流以HTTP消息的形式发送,HTTP消息被分为独立的帧,然后由一或多个帧组成,这些帧可以乱序发送,接收端根据这些帧的标识符号和首部将信息重新组装起来。
默认什么情况下使用同一个连接
- 同一个域名下的资源
- 不同域名但是满足两个条件:1)解析到同一个 IP;2)使用同一个证书
头部压缩
当一个客户端向相同服务器请求许多资源时,像来自同一个网页的图像,将会有大量的请求看上去几乎同样的,这就需要压缩技术对付这种几乎相同的信息。
由于头信息使用文本,没有压缩,请求时候会来回重复传递,造成流量浪费。
头部压缩需要支持 HTTP2的浏览器和服务器之间:
- 维护一份相同的静态字典(包含常见的头部名称,以及常见的头部名称与值的组合)
- 维护一份相同的动态字典,动态添加内容(即实际的 Header 值)
- 支持基于静态哈夫曼码表的哈夫曼编码(uffman Coding)
原理图:

总结: 通过映射表,传递对应编码和值来达到压缩。
随时复位
HTTP1.1一个缺点是当HTTP信息有一定长度大小数据传输时,你不能方便地随时停止它,中断TCP连接的代价是昂贵的。使用HTTP2的RST_STREAM将能方便停止一个信息传输,启动新的信息,在不中断连接的情况下提高带宽利用效率。
服务器端推流
Server Push。客户端请求一个资源X,服务器端判断也许客户端还需要资源Z,在无需事先询问客户端情况下将资源Z推送到客户端,客户端接受到后,可以缓存起来以备后用。
优先权和依赖
每个流都有自己的优先级别,会表明哪个流是最重要的,客户端会指定哪个流是最重要的,有一些依赖参数,这样一个流可以依赖另外一个流。优先级别可以在运行时动态改变,当用户滚动页面时,可以告诉浏览器哪个图像是最重要的,你也可以在一组流中进行优先筛选,能够突然抓住重点流。
队头阻塞以及解决办法
前言
通常我们提到队头阻塞,指的可能是TCP协议中的队头阻塞,但是HTTP1.1中也有一个类似TCP队头阻塞的问题,下面各自介绍一下。
TCP队头阻塞
队头阻塞(head-of-line blocking)发生在一个TCP分节丢失,导致其后续分节不按序到达接收端的时候。该后续分节将被接收端一直保持直到丢失的第一个分节被发送端重传并到达接收端为止。该后续分节的延迟递送确保接收应用进程能够按照发送端的发送顺序接收数据。这种为了达到完全有序而引入的延迟机制,非常有用,但也有不利之处。
假设在单个TCP连接上发送语义独立的消息,比如说服务器可能发送3幅不同的图像供Web浏览器显示。为了营造这几幅图像在用户屏幕上并行显示的效果,服务器先发送第一幅图像的一个断片,再发送第二幅图像的一个断片,然后再发送第三幅图像的一个断片;服务器重复这个过程,直到这3幅图像全部成功地发送到浏览器为止。
要是第一幅图像的某个断片内容的TCP分节丢失了,客户端将保持已到达的不按序的所有数据,直到丢失的分节重传成功。这样不仅延缓了第一幅图像数据的递送,也延缓了第二幅和第三幅图像数据的递送。
HTTP队头阻塞
上面用浏览器请求图片资源举例子,但实际上HTTP自身也有类似TCP队头阻塞的情况。要介绍HTTP队头阻塞,就需要先讲讲HTTP的管道化(pipelining)。
HTTP管道化是什么
HTTP1.1 允许在持久连接上可选的使用请求管道。这是相对于keep-alive连接的又一性能优化。在响应到达之前,可以将多条请求放入队列,当第一条请求发往服务器的时候,第二第三条请求也可以开始发送了,在高延时网络条件下,这样做可以降低网络的环回时间,提高性能。
非管道化与管道化的区别示意图

HTTP管道化产生的背景
在一般情况下,HTTP遵守“请求-响应”的模式,也就是客户端每次发送一个请求到服务端,服务端返回响应。这种模式非常容易理解,但是效率并不是那么高,为了提高速度和效率,人们做了很多尝试:
- 最简单的情况下,服务端一旦返回响应后就会把对应的连接关闭,客户端的多个请求实际上是串行发送的。
- 除此之外,客户端可以选择同时创建多个连接,在多个连接上并行的发送不同请求。但是创建更多连接也带来了更多的消耗,当前大部分浏览器都会限制对同一个域名的连接数。
- 从HTTP1.0开始增加了持久连接的概念(HTTP1.0的Keep-Alive和HTTP1.1的persistent),可以使HTTP能够复用已经创建好的连接。客户端在收到服务端响应后,可以复用上次的连接发送下一个请求,而不用重新建立连接。
- 现代浏览器大多采用并行连接与持久连接共用的方式提高访问速度,对每个域名建立并行地少量持久连接。
- 而在持久连接的基础上,HTTP1.1进一步地支持在持久连接上使用管道化(pipelining)特性。管道化允许客户端在已发送的请求收到服务端的响应之前发送下一个请求,借此来减少等待时间提高吞吐;如果多个请求能在同一个TCP分节发送的话,还能提高网络利用率。但是因为HTTP管道化本身可能会导致队头阻塞的问题,以及一些其他的原因,现代浏览器默认都关闭了管道化。
HTTP管道化的限制
- 管道化要求服务端按照请求发送的顺序返回响应(FIFO),原因很简单,HTTP请求和响应并没有序号标识,无法将乱序的响应与请求关联起来。
- 客户端需要保持未收到响应的请求,当连接意外中断时,需要重新发送这部分请求。
- 只有幂等的请求才能进行管道化,也就是只有GET和HEAD请求才能管道化,否则可能会出现意料之外的结果
HTTP管道化引起的请求队头阻塞
前面提到HTTP管道化要求服务端必须按照请求发送的顺序返回响应,那如果一个响应返回延迟了,那么其后续的响应都会被延迟,直到队头的响应送达。
如何解决队头阻塞
如何解决HTTP队头阻塞
对于HTTP1.1中管道化导致的请求/响应级别的队头阻塞,可以使用HTTP2解决。HTTP2不使用管道化的方式,而是引入了帧、消息和数据流等概念,每个请求/响应被称为消息,每个消息都被拆分成若干个帧进行传输,每个帧都分配一个序号。每个帧在传输是属于一个数据流,而一个连接上可以存在多个流,各个帧在流和连接上独立传输,到达之后在组装成消息,这样就避免了请求/响应阻塞。
当然,即使使用HTTP2,如果HTTP2底层使用的是TCP协议,仍可能出现TCP队头阻塞。
如何解决TCP队头阻塞
TCP中的队头阻塞的产生是由TCP自身的实现机制决定的,无法避免。想要在应用程序当中避免TCP队头阻塞带来的影响,只有舍弃TCP协议。
比如google推出的QUIC协议,在某种程度上可以说避免了TCP中的队头阻塞,因为它根本不使用TCP协议,而是在UDP协议的基础上实现了可靠传输。而UDP是面向数据报的协议,数据报之间不会有阻塞约束。
此外还有一个SCTP(流控制传输协议),它是和TCP、UDP在同一层次的传输协议。SCTP的多流特性也可以尽可能的避免队头阻塞的情况。
总结
从TCP队头阻塞和HTTP队头阻塞的原因我们可以看到,出现队头阻塞的原因有两个:
- 独立的消息数据都在一个链路上传输,也就是有一个“队列”。比如TCP只有一个流,多个HTTP请求共用一个TCP连接
- 队列上传输的数据有严格的顺序约束。比如TCP要求数据严格按照序号顺序,HTTP管道化要求响应严格按照请求顺序返回
所以要避免队头阻塞,就需要从以上两个方面出发,比如quic协议不使用TCP协议而是使用UDP协议,SCTP协议支持一个连接上存在多个数据流等等。
QUIC
QUIC(Quick UDP Internet Connection)是谷歌制定的一种互联网传输层协议,它基于UDP传输层协议,同时兼具TCP、TLS、HTTP/2等协议的可靠性与安全性,可以有效减少连接与传输延迟,更好地应对当前传输层与应用层的挑战。
QUIC的由来:为什么是UDP而非TCP?
UDP和TCP都属于传输层协议。TCP是面向连接的,更强调的是传输的可靠性,通过TCP连接传送的数据,无差错,不丢失,不重复,按序到达,但是因为TCP在传递数据之前会有三次握手来建立连接,所以效率低、占用系统的CPU、内存等硬件资源较高;而UDP的无连接的(即发送数据之前不需要建立连接),只需要知道对方地址即可发送数据,具有较好的实时性,工作效率比TCP高,占用系统资源比TCP少,但是在数据传递时,如果网络质量不好,就会很容易丢包。
我们知道,大部分Web平台的数据传输都基于TCP协议。实际上,TCP在设计之初,网络环境复杂、丢包率高、网速差,所以TCP可以完美解决可靠性的问题。而如今的网络环境和网速都已经取得了巨大的改善,网络传输可靠性已经不再是棘手的问题。另外,TCP还有一个很大的问题是更新非常困难。这是因为:TCP网络协议栈的实现依赖于系统内核更新,一旦系统内核更新,终端设备、中间设备的系统更新都会非常缓慢,迭代需要花费几年甚至十几年的时间,这显然跟不上当今互联网的发展速度。所以现在解法就是,抛弃TCP而使用UDP,来实现低延迟的传输需求。

为了结合两者优点,谷歌公司推出了QUIC,它的升级不依赖于系统内核,只需要Client和Server端更新到指定版本。如此一来,基于UDP的QUIC就能月更甚至周更,很好的解决了TCP部署和更新的困难,更灵活地实现部署和更新。
为什么要用QUIC?
1. 建连延迟低
网民传统TCP三次握手+TLS1~2RTT握手+http数据,基于TCP的HTTPS一次建连至少需要2~3个RTT,而QUIC基于UDP,完整握手只需要1RTT乃至0RTT,可以显著降低延迟。

2. 安全又可靠
QUIC具备TCP、TLS、HTTPS/2等协议的安全、可靠性的特点,通过提供安全功能(如身份验证和加密)来实现加密传输,这些功能由传输协议本身的更高层协议(如TLS)来实现。
3. 改造灵活
QUIC在应用程序层面就能实现不同的拥塞控制算法,不需要操作系统和内核支持,这相比于传统的TCP协议改造灵活性更好。
4. 改进的拥塞控制
QUIC主要实现了TCP的慢启动、拥塞避免、快重传、快恢复。在这些拥塞控制算法的基础上改进,例如单调递增的 Packet Number,解决了重传的二义性,确保RTT准确性,减少重传次数。
5. 无队头阻塞的多路复用
HTTP2实现了多路复用,可以在一条TCP流上并发多个HTTP请求,但基于TCP的HTTP2在传输层却有个问题,TCP无法识别不同的HTTP2流,实际收数据仍是一个队列,当后发的流先收到时,会因前面的流未到达而被阻塞。QUIC一个connection可以复用传输多个stream,每个stream之间都是独立的,一个stream的丢包不会影响到其他stream的接收和处理。

综上所述,QUIC具有众多优点,它融合了UDP协议的速度、性能与TCP的安全与可靠,大大优化了互联网传输体验。
作为提升终端用户访问效率的CDN服务,其节点之间存在大量数据互通,节点之间的网络连接、传输架构等因素都会对CDN服务质量产生影响。而将QUIC应用在CDN系统中,CDN用户开启QUIC功能后,系统将遵循QUIC协议进行用户IP请求处理,既能满足安全传输的需求,也能提升传输效率。
QUIC对客户端的要求
- 如果您使用Chrome浏览器,则只支持QUIC协议Q43版本。当前阿里云CDN的QUIC协议是Q39版本,不支持直接对阿里云CDN发起QUIC请求。
- 如果您使用自研App,则App必须集成支持QUIC协议的网络库,例如:lsquic-client或cronet网络库。
QUIC应用场景
- 图片小文件:明显降低文件下载总耗时,提升效率
- 视频点播:提升首屏秒开率,降低卡顿率,提升用户观看体验
- 动态请求:适用于动态请求,提升访问速度,如网页登录、交易等交互体验提升
- 弱网环境:在丢包和网络延迟严重的情况下仍可提供可用的服务,并优化卡顿率、请求失败率、秒开率、提高连接成功率等传输指标
- 大并发连接:连接可靠性强,支持页面资源数较多、并发连接数较多情况下的访问速率提升
- 加密连接:具备安全、可靠的传输性能
HTTP协议
一面中,如果有笔试,考HTTP协议的可能性较大。
1. 前言
一面要讲的内容:
HTTP协议的主要特点HTTP报文的组成部分HTTP方法get和post的区别HTTP状态码- 什么是持久连接
- 什么是管线化
二面要讲的内容;
- 缓存
CSRF攻击- TSL 协商
2. HTTP协议的主要特点
- 简单快速
- 灵活
- 无连接
- 无状态
通常我们要答出以上四个内容。如果实在记不住,一定要记得后面的两个:无连接、无状态。
我们分别来解释一下。
2.1 简单快速
简单:每个资源(比如图片、页面)都通过 url 来定位。这都是固定的,在
http协议中,处理起来也比较简单,想访问什么资源,直接输入url即可。
2.2 灵活
http协议的头部有一个数据类型,通过http协议,就可以完成不同数据类型的传输。
2.3 无连接
连接一次,就会断开,不会继续保持连接。
2.4 无状态
客户端和服务器端是两种身份。第一次请求结束后,就断开了,第二次请求时,服务器端并没有记住之前的状态,也就是说,服务器端无法区分客户端是否为同一个人、同一个身份。
有的时候,我们访问网站时,网站能记住我们的账号,这个是通过其他的手段(比如
session)做到的,并不是http协议能做到的。
3 HTTP报文的组成部分

在回答此问题时,我们要按照顺序回答:
- 先回答的是,
http报文包括:请求报文和响应报文。 - 再回答的是,每个报文包含什么部分。
- 最后回答,每个部分的内容是什么
3.1 请求报文包括:

- 请求行:包括请求方法、请求的
url、http协议及版本。 - 请求头:一大堆的键值对。
- 空行指的是:当服务器在解析请求头的时候,如果遇到了空行,则表明,后面的内容是请求体
- 请求体:数据部分。
3.2 响应报文包括:

- 状态行:
http协议及版本、状态码及状态描述。 - 响应头
- 空行
- 响应体
4 HTTP方法
包括:
GET:获取资源POST:传输资源put:更新资源DELETE:删除资源HEAD:获得报文首部
HTTP方法有很多,但是上面这五个方法,要求在面试时全部说出来,不要漏掉。
get和post` 比较常见。put和delete在实际应用中用的很少。况且,业务中,一般不删除服务器端的资源。head可能偶尔用的到。
5 get 和 post的区别

- 区别有很多,如果记不住,面试时,至少要任意答出其中的三四条。
- 有一点要强调,get是相对不隐私的,而post是相对隐私的。
我们大概要记住以下几点:
- 浏览器在回退时,
get不会重新请求,但是post会重新请求。【重要】 get请求会被浏览器主动缓存,而post不会。【重要】get请求的参数,会报保留在浏览器的历史记录里,而post不会。做业务时要注意。为了防止CSRF攻击,很多公司把get统一改成了post。get请求在url中传递的参数有大小限制,基本是2kb`,不同的浏览器略有不同。而post没有注意。get的参数是直接暴露在url上的,相对不安全。而post是放在请求体中的。
6 http状态码
http状态码分类:

常见的
http状态码:

部分解释:
206的应用:range指的是请求的范围,客户端只请求某个大文件里的一部分内容。比如说,如果播放视频地址或音频地址的前面一部分,可以用到206。301:重定向(永久)。302:重定向(临时)。304:我这个服务器告诉客户端,你已经有缓存了,不需要从我这里取了。

400和401用的不多,未授权。403指的是请求被拒绝。404指的是资源不存在。
7 持久链接/http长连接
如果你能答出持久链接,这是面试官很想知道的一个点。
- 轮询:
http1.0中,客户端每隔很短的时间,都会对服务器发出请求,查看是否有新的消息,只要轮询速度足够快,例如1秒,就能给人造成交互是实时进行的印象。这种做法是无奈之举,实际上对服务器、客户端双方都造成了大量的性能浪费。 - 长连接:
HTTP1.1中,通过使用Connection:keep-alive进行长连接,。客户端只请求一次,但是服务器会将继续保持连接,当再次请求时,避免了重新建立连接。
注意,
HTTP 1.1默认进行持久连接。在一次TCP连接中可以完成多个HTTP请求,但是对每个请求仍然要单独发 header,Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。
8 长连接中的管线化
如果能答出管线化,则属于加分项。
8.1 管线化的原理
长连接时,默认的请求这样的:
1 | 请求1 --> 响应1 -->请求2 --> 响应2 --> 请求3 --> 响应3 |
管线化就是,我把现在的请求打包,一次性发过去,你也给我一次响应回来。
8.2 管线化的注意事项
面试时,不会深究管线化。如果真要问你,就回答:“我没怎么研究过,准备回去看看~”
9 TLS 协商
Transport Layer Security (TLS) 是一个为计算机网络提供通信安全的加密协议。它广泛应用于大量应用程序,其中之一即浏览网页。网站可以使用 TLS 来保证服务器和网页浏览器之间的所有通信安全。
整个 TLS 握手过程包含以下几个步骤:
- 客户端向服务器发送 『Client hello』 信息,附带着客户端随机值(random_C)和支持的加密算法组合。
- 服务器返回给客户端 『Server hello』信息,附带着服务器随机值(random_S),以及选择一个客户端发送过来加密算法。
- 服务器返回给客户端认证证书及或许要求客户端返回一个类似的证书,认证证书里面携带服务端的公钥信息。
- 服务器返回『Server hello done』信息。
- 如果服务器要求客户端发送一个证书,客户端进行发送。
- 客户端创建一个随机的 Pre-Master 密钥然后使用服务器证书中的公钥来进行加密,向服务器发送加密过的 Pre-Master 密钥。
- 服务器收到 Pre-Master 密钥。服务器和客户端各自生成基于 Pre-Master 密钥的主密钥和会话密钥。两个明文随机数 random_C 和 random_S 与自己计算产生的 pre-master,计算得到协商密钥enc_key=Fuc(random_C, random_S, pre-master)
- 客户端给服务器发送一个 『Change cipher spec』的通知,表明客户端将会开始使用协商密钥和加密算法进行加密通信。
- 客户端也发送了一个 『Client finished』的消息。
- 服务器接收到『Change cipher spec』的通知然后使用协商密钥和加密算法进行加密通信。
- 服务器返回客户端一个 『Server finished』消息。
- 客户端和服务器现在可以通过建立的安全通道来交换程序数据。所有客户端和服务器之间发送的信息都会使用会话密钥进行加密。
每当发生任何验证失败的时候,用户会收到警告。比如服务器使用自签名的证书。
WebRTC的优缺点
WebRTC,即网页即时通信(Web Real-Time Communication),是一个支持网页浏览器进行实时语音对话或视频对话的API。
目前几乎所有主流浏览器都支持了 WebRTC,越来越多的公司正在使用 WebRTC 并且将其加到自己的应用程序中。在浏览器端,依赖于浏览器获取音视频的能力,以及强大的网页上的渲染能力,就能够为高清的通信体验打下基础。同时,相比移动端来说,屏幕比较大,视窗选择也比较灵活。
优点
方便。对于用户来说,在WebRTC出现之前想要进行实时通信就需要安装插件和客户端,但是对于很多用户来说,插件的下载、软件的安装和更新这些操作是复杂而且容易出现问题的,现在WebRTC技术内置于浏览器中,用户不需要使用任何插件或者软件就能通过浏览器来实现实时通信。对于开发者来说,在Google将WebRTC开源之前,浏览器之间实现通信的技术是掌握在大企业手中,这项技术的开发是一个很困难的任务,现在开发者使用简单的HTML标签和JavaScript API就能够实现Web音/视频通信的功能。
免费。虽然WebRTC技术已经较为成熟,其集成了最佳的音/视频引擎,十分先进的codec,但是Google对于这些技术不收取任何费用。
强大的打洞能力。WebRTC技术包含了使用STUN、ICE、TURN、RTP-over-TCP的关键NAT和防火墙穿透技术,并支持代理。
缺点
缺乏服务器方案的设计和部署。
传输质量难以保证。WebRTC的传输设计基于P2P,难以保障传输质量,优化手段也有限,只能做一些端到端的优化,难以应对复杂的互联网环境。比如对跨地区、跨运营商、低带宽、高丢包等场景下的传输质量基本是靠天吃饭,而这恰恰是国内互联网应用的典型场景。
WebRTC比较适合一对一的单聊,虽然功能上可以扩展实现群聊,但是没有针对群聊,特别是超大群聊进行任何优化。
设备端适配,如回声、录音失败等问题层出不穷。这一点在安卓设备上尤为突出。由于安卓设备厂商众多,每个厂商都会在标准的安卓框架上进行定制化,导致很多可用性问题(访问麦克风失败)和质量问题(如回声、啸叫)。
对Native开发支持不够。WebRTC顾名思义,主要面向Web应用,虽然也可以用于Native开发,但是由于涉及到的领域知识(音视频采集、处理、编解码、实时传输等)较多,整个框架设计比较复杂,API粒度也比较细,导致连工程项目的编译都不是一件容易的事。
EventSource和轮询的优缺点
EventSource
简介
EventSource 是服务器推送的一个网络事件接口。一个EventSource实例会对HTTP服务开启一个持久化的连接,以text/event-stream 格式发送事件, 会一直保持开启直到被要求关闭。
一旦连接开启,来自服务端传入的消息会以事件的形式分发至你代码中。如果接收消息中有一个事件字段,触发的事件与事件字段的值相同。如果没有事件字段存在,则将触发通用事件。
与 WebSockets,不同的是,服务端推送是单向的。数据信息被单向从服务端到客户端分发. 当不需要以消息形式将数据从客户端发送到服务器时,这使它们成为绝佳的选择。例如,对于处理社交媒体状态更新,新闻提要或将数据传递到客户端存储机制(如IndexedDB或Web存储)之类的,EventSource无疑是一个有效方案。
EventSource(Server-sent events)简称SSE用于向服务端发送事件,它是基于http协议的单向通讯技术,以text/event-stream格式接受事件,如果不关闭会一直处于连接状态,直到调用EventSource.close()方法才能关闭连接;EvenSource本质上也就是XHR-streaming只不过浏览器给它提供了标准的API封装和协议。由于
EventSource是单向通讯,所以只能用来实现像股票报价、新闻推送、实时天气这些只需要服务器发送消息给客户端场景中。EventSource虽然不支持双向通讯,但是在功能设计上他也有一些优点比如可以自动重连接,event IDs,以及发送随机事件的等功能
EventSource案例浏览器端代码如下所示:
1 | // 实例化 EventSource 参数是服务端监听的路由 |
服务器端
1 | const http = require('http'); |
EventSource规范字段
- event: 事件类型,如果指定了该字段,则在客户端接收到该条消息时,会在当前的EventSource对象上触发一个事件,事件类型就是该字段的字段值,你可以使用addEventListener()方法在当前EventSource对象上监听任意类型的命名事件,如果该条消息没有event字段,则会触发onmessage属性上的事件处理函数。
- data: 消息的数据字段,如果该消息包含多个data字段,则客户端会用换行符把他们连接成一个字符串来处理
- id: 事件ID,会成为当前EventSource对象的内部属性“最后一个事件ID”的属性值;
- retry: 一个整数值,指定了重新连接的时间(单位为毫秒),如果该字段不是整数,则会被忽略。
EventSource属性
- EventSource.onerror: 是一个 EventHandler,当发生错误时被调用,并且在此对象上派发 error 事件。
- EventSource.onmessage: 是一个 EventHandler,当收到一个 message事件,即消息来自源头时被调用。
- EventSource.onopen: 是一个 EventHandler,当收到一个 open 事件,即连接刚打开时被调用。
- EventSource.readyState(只读): 一个 unsigned short 值,代表连接状态。可能值是CONNECTING (0), OPEN (1), 或者 CLOSED (2)。
- EventSource.url(只读): 一个DOMString,代表源头的URL。
EventSource 通讯过程

缺点
- 因为是服务器->客户端的,所以它不能处理客户端请求流
- 因为是明确指定用于传输UTF-8数据的,所以对于传输二进制流是低效率的,即使你转为base64的话,反而增加带宽的负载,得不偿失。
轮询
短轮询(Polling)
是一种简单粗暴,同样也是一种效率低下的实现“实时”通讯方案,这种方案的原理就是定期向服务器发送请求,主动拉取最新的消息队列。
客户端代码:
1 | function Polling() { |

这种轮询方式比较适合服务器信息定期更新的场景,如天气预报股票行情等,每隔一段时间会进行更新,且轮询间隔的服务器更新频率保持一致是比较理想的方式,但很多多时候会因网络或者服务器出现阻塞早场事件间隔不一致。
优点:
- 可以看到实现非常简单,它的兼容性也比较好的只要支持http协议就可以用这种方式实现
缺点:
资源浪费: 比如轮询的间隔小于服务器信息跟新频率,会浪费很多HTTP请求,消耗宝贵的CPU时间和带宽。
容易导致请求轰炸: 例如当服务器负载比较高时,第一个请求还没有处理完,这时第三、第四个请求接踵而来,无用的额外请求对服务器端进行了轰炸。
长轮询(Long Polling)
这是一种优化的轮询方式,称为长轮询,sockjs就是使用的这种轮询方式,长轮询值的是浏览器发送一个请求到服务器,服务器只有在有可用的新数据时才会响应。
客户端代码:
1 | function LongPolling() { |

客户端向服务器发送一个消息获取请求时,服务器会将当前的消息队列返回给客户端,然后关闭连接。当消息队列为空的时,服务器不会立即关闭连接,而是等待指定的时间间隔,如果在这个时间间隔内没有新的消息,则由客户端主动超时关闭连接。
相比Polling,客户端的轮询请求只有在上一个请求连接关闭后才会重新发起。这就解决了Polling的请求轰炸问题。服务器可以控制的请求时序,因为在服务器未响应之前,客户端不会发送额为的请求。
优点:
- 长轮询和短轮询比起来,明显减少了很多不必要的http请求次数,相比之下节约了资源。
缺点:
- 连接挂起也会导致资源的浪费。
EventSource VS 轮询
| 轮询(Polling) | 长轮询(Long-Polling) | EventSource | |
|---|---|---|---|
| 通信协议 | http | http | http |
| 触发方式 | client(客户端) | client(客户端) | client、server(客户端、服务端) |
| 优点 | 兼容性好容错性强,实现简单 | 比短轮询节约服务器资源 | 实现简便,开发成本低 |
| 缺点 | 安全性差,占较多的内存资源与请求数量,容易对服务器造成压力,请求时间间隔容易导致不一致 | 安全性差,占较多的内存资源与请求数,请求时间间隔容易导致不一致 | 只适用高级浏览器,老版本的浏览器不兼容 |
| 延迟 | 非实时,延迟取决于请求间隔 | 非实时,延迟取决于请求间隔 | 非实时,默认3秒延迟,延迟可自定义 |
总结
通过对上面两种对通讯技术比较,可以从不同的角度考虑;
- 兼容性: 短轮询 > 长轮询 > EventSource
- 性能: EvenSource > 长轮询 > 短轮询
- 服务端推送: EventSource > 长连接 (短轮询基本不考虑)
WebSocket 是什么原理?为什么可以实现持久连接?
WebSocket 机制
以下简要介绍一下WebSocket的原理及运行机制。
WebSocket是HTML5下一种新的协议。它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的。它与HTTP一样通过已建立的TCP连接来传输数据,但是它和HTTP最大不同是:
- WebSocket是一种双向通信协议。在建立连接后,WebSocket服务器端和客户端都能主动向对方发送或接收数据,就像Socket一样;
- WebSocket需要像TCP一样,先建立连接,连接成功后才能相互通信。
传统HTTP客户端与服务器请求响应模式如下图所示:

WebSocket模式客户端与服务器请求响应模式如下图:

上图对比可以看出,相对于传统HTTP每次请求-响应都需要客户端与服务端建立连接的模式,WebSocket是类似Socket的TCP长连接通讯模式。一旦WebSocket连接建立后,后续数据都以帧序列的形式传输。在客户端断开WebSocket连接或Server端中断连接前,不需要客户端和服务端重新发起连接请求。在海量并发及客户端与服务器交互负载流量大的情况下,极大的节省了网络带宽资源的消耗,有明显的性能优势,且客户端发送和接受消息是在同一个持久连接上发起,实时性优势明显。
相比HTTP长连接,WebSocket有以下特点:
- 是真正的全双工方式,建立连接后客户端与服务器端是完全平等的,可以互相主动请求。而HTTP长连接基于HTTP,是传统的客户端对服务器发起请求的模式。
- HTTP长连接中,每次数据交换除了真正的数据部分外,服务器和客户端还要大量交换HTTP header,信息交换效率很低。Websocket协议通过第一个request建立了TCP连接之后,之后交换的数据都不需要发送 HTTP header就能交换数据,这显然和原有的HTTP协议有区别所以它需要对服务器和客户端都进行升级才能实现(主流浏览器都已支持HTML5)。此外还有 multiplexing、不同的URL可以复用同一个WebSocket连接等功能。这些都是HTTP长连接不能做到的。
WebSocket协议的原理
与http协议一样,WebSocket协议也需要通过已建立的TCP连接来传输数据。具体实现上是通过http协议建立通道,然后在此基础上用真正的WebSocket协议进行通信,所以WebSocket协议和http协议是有一定的交叉关系的。

下面是WebSocket协议请求头:

其中请求头中重要的字段:
1 | Connection:Upgrade |
- Connection和Upgrade字段告诉服务器,客户端发起的是WebSocket协议请求
- Sec-WebSocket-Extensions表示客户端想要表达的协议级的扩展
- Sec-WebSocket-Key是一个Base64编码值,由浏览器随机生成
- Sec-WebSocket-Version表明客户端所使用的协议版本
而得到的响应头中重要的字段:
1 | Connection:Upgrade |
Connection和Upgrade字段与请求头中的作用相同
Sec-WebSocket-Accept表明服务器接受了客户端的请求
1 | Status Code:101 Switching Protocols |
并且http请求完成后响应的状态码为101,表示切换了协议,说明WebSocket协议通过http协议来建立运输层的TCP连接,之后便与http协议无关了。
WebSocket协议的优缺点
优点:
- WebSocket协议一旦建议后,互相沟通所消耗的请求头是很小的
- 服务器可以向客户端推送消息了
缺点:
- 少部分浏览器不支持,浏览器支持的程度与方式有区别
WebSocket协议的应用场景
- 即时聊天通信
- 多玩家游戏
- 在线协同编辑/编辑
- 实时数据流的拉取与推送
- 体育/游戏实况
- 实时地图位置
一个使用WebSocket应用于视频的业务思路如下:
- 使用心跳维护websocket链路,探测客户端端的网红/主播是否在线
- 设置负载均衡7层的proxy_read_timeout默认为60s
- 设置心跳为50s,即可长期保持Websocket不断开
网络相关
1.1 DNS 预解析
- DNS 解析也是需要时间的,可以通过预解析的方式来预先获得域名所对应的 IP
1 | <link rel="dns-prefetch" href="//yuchengkai.cn"> |
1.2 缓存
- 缓存对于前端性能优化来说是个很重要的点,良好的缓存策略可以降低资源的重复加载提高网页的整体加载速度
- 通常浏览器缓存策略分为两种:强缓存和协商缓存
强缓存
实现强缓存可以通过两种响应头实现:
Expires和Cache-Control。强缓存表示在缓存期间不需要请求,state code为200
1 | Expires: Wed, 22 Oct 2018 08:41:00 GMT |
Expires是HTTP / 1.0的产物,表示资源会在Wed, 22 Oct 2018 08:41:00 GMT后过期,需要再次请求。并且Expires受限于本地时间,如果修改了本地时间,可能会造成缓存失效
1 | Cache-control: max-age=30 |
Cache-Control出现于HTTP / 1.1,优先级高于Expires。该属性表示资源会在30秒后过期,需要再次请求
协商缓存
- 如果缓存过期了,我们就可以使用协商缓存来解决问题。协商缓存需要请求,如果缓存有效会返回 304
- 协商缓存需要客户端和服务端共同实现,和强缓存一样,也有两种实现方式
Last-Modified 和 If-Modified-Since
Last-Modified表示本地文件最后修改日期,If-Modified-Since会将Last-Modified的值发送给服务器,询问服务器在该日期后资源是否有更新,有更新的话就会将新的资源发送回来- 但是如果在本地打开缓存文件,就会造成
Last-Modified被修改,所以在HTTP / 1.1出现了ETag
ETag 和 If-None-Match
ETag类似于文件指纹,If-None-Match会将当前ETag发送给服务器,询问该资源 ETag 是否变动,有变动的话就将新的资源发送回来。并且ETag优先级比Last-Modified高
选择合适的缓存策略
对于大部分的场景都可以使用强缓存配合协商缓存解决,但是在一些特殊的地方可能需要选择特殊的缓存策略
- 对于某些不需要缓存的资源,可以使用
Cache-control: no-store,表示该资源不需要缓存 - 对于频繁变动的资源,可以使用
Cache-Control: no-cache并配合ETag使用,表示该资源已被缓存,但是每次都会发送请求询问资源是否更新。 - 对于代码文件来说,通常使用
Cache-Control: max-age=31536000并配合策略缓存使用,然后对文件进行指纹处理,一旦文件名变动就会立刻下载新的文件
1.3 使用 HTTP / 2.0
- 因为浏览器会有并发请求限制,在 HTTP / 1.1 时代,每个请求都需要建立和断开,消耗了好几个 RTT 时间,并且由于 TCP 慢启动的原因,加载体积大的文件会需要更多的时间
- 在 HTTP / 2.0 中引入了多路复用,能够让多个请求使用同一个 TCP 链接,极大的加快了网页的加载速度。并且还支持 Header 压缩,进一步的减少了请求的数据大小
1.4 预加载
- 在开发中,可能会遇到这样的情况。有些资源不需要马上用到,但是希望尽早获取,这时候就可以使用预加载
- 预加载其实是声明式的
fetch,强制浏览器请求资源,并且不会阻塞onload事件,可以使用以下代码开启预加载
1 | <link rel="preload" href="http://example.com"> |
预加载可以一定程度上降低首屏的加载时间,因为可以将一些不影响首屏但重要的文件延后加载,唯一缺点就是兼容性不好
1.5 预渲染
可以通过预渲染将下载的文件预先在后台渲染,可以使用以下代码开启预渲染
1 | <link rel="prerender" href="http://example.com"> |
- 预渲染虽然可以提高页面的加载速度,但是要确保该页面百分百会被用户在之后打开,否则就白白浪费资源去渲染
优化渲染过程
2.1 懒执行
- 懒执行就是将某些逻辑延迟到使用时再计算。该技术可以用于首屏优化,对于某些耗时逻辑并不需要在首屏就使用的,就可以使用懒执行。懒执行需要唤醒,一般可以通过定时器或者事件的调用来唤醒
2.2 懒加载
- 懒加载就是将不关键的资源延后加载
懒加载的原理就是只加载自定义区域(通常是可视区域,但也可以是即将进入可视区域)内需要加载的东西。对于图片来说,先设置图片标签的 src 属性为一张占位图,将真实的图片资源放入一个自定义属性中,当进入自定义区域时,就将自定义属性替换为 src 属性,这样图片就会去下载资源,实现了图片懒加载
- 懒加载不仅可以用于图片,也可以使用在别的资源上。比如进入可视区域才开始播放视频等
三栏弹性布局的5种方法(绝对定位、圣杯、双飞翼、flex、grid)
需求
用css实现三栏布局,html结构代码如下,顺序不能变(main优先渲染),可以适当加元素,同时要求left宽度200px,right宽度300px,main宽度自适应。
1 | <div class="container"> |

5种具体实现和优缺点比较
1. 绝对定位布局
原始的布局方法
原理:container为相对定位并设置左右padding为left和right的宽度,left\right绝对定位在左右两侧,main不用设置。
优点:兼容好、原理简单
缺点:left和right都为绝对定位,高度不能撑开container
1 |
|
2. 圣杯布局
圣杯布局方法
- 原理:container设置左右padding为left和right的宽度,left\right\main 浮动,left\right相对定位并设置left、right、margin-left来偏移位置,main宽100%。
- 优点:兼容好
- 缺点:原理复制,left/right/main高度自适应情况下3者不能高度一致。
1 |
|
3. 双飞翼布局
圣杯布局改进方法
- 原理:left\right\main 浮动,left\right设置margin-left来偏移位置,main宽100%,main出入content,并设置content的左右边距为left\right宽度
- 优点:兼容好,原理简单
- 缺点:left/right/main高度自适应情况下3者不能高度一致。
1 |
|
4. flex布局
css3新布局方式
- 原理:container设置
display:flex,left设置order:-1排在最前面,main设置flex-grow:1自适应宽度 - 优点:原理简单,代码简洁,left/right/main高度自适应情况下3者能高度一致
- 缺点:兼容性不够好,ie10+,chrome20+,正式使用要加各种前缀(-webkit–ms-)
1 |
|
5. grid布局
css3新布局方式
- 原理:container设置
display:grid和grid-template-columns:200px auto 300px,left设置order: -1排在最前面 - 优点:原理简单,代码简洁,left/right/main高度自适应情况下3者能高度一致
- 缺点:兼容性较差,ie10+,Chrome57+,正式使用要加各种前缀(-webkit–ms-)
1 |
|
浅析CSS里的BFC和IFC的用法
BFC简介
所谓的 Formatting Context(格式化上下文), 它是 W3C CSS2.1 规范中的一个概念。
- 格式化上下文(FC)是页面中的一块渲染区域,并且有一套渲染规则。
- 格式化上下文(FC)决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
Block Formatting Context (BFC,块级格式化上下文),就是一个块级元素的渲染显示规则。通俗一点讲,可以把 BFC 理解为一个封闭的大箱子,容器里面的子元素不会影响到外面的元素,反之也如此。
BFC的布局规则如下:
- 内部的盒子会在垂直方向,一个个地放置;
- BFC是页面上的一个隔离的独立容器;
- 属于同一个BFC的 两个相邻Box的 上下margin会发生重叠;
- 计算BFC的高度时,浮动元素也参与计算;
- 每个元素的左边,与包含的盒子的左边相接触,即使存在浮动也是如此;**(存疑)**
- BFC的区域不会与float重叠。
那么如何触发 BFC 呢?只要元素满足下面任一条件即可触发 BFC 特性:
- body 根元素;
- 浮动元素:float 不为none的属性值;
- 绝对定位元素:position (absolute、fixed);
- display为: inline-block、table-cells、flex;
- overflow 除了visible以外的值 (hidden、auto、scroll)。
BFC的特性及应用
同一个 BFC下外边距 会发生折叠
1 |
|
效果如下所示:

根据BFC规则的第3条:
盒子垂直方向的距离由margin决定,
属于 同一个BFC的 + 两个相邻Box的 + 上下margin 会发生重叠。
上文的例子 之所以发生外边距折叠,是因为他们 同属于 body这个根元素, 所以我们需要让 它们 不属于同一个BFC,就能避免外边距折叠:
1 |
|
效果如下所示:

BFC可以包含浮动的元素(清除浮动)
正常情况下,浮动的元素会脱离普通文档流,所以下面的代码里:
1 |
|
外层的div会无法包含 内部浮动的div。
效果如下所示:

但如果我们 触发外部容器的BFC,根据BFC规范中的第4条:计算BFC的高度时,浮动元素也参与计算,那么外部div容器就可以包裹着浮动元素,所以只要把代码修改如下:
1 |
|
效果如下所示:

BFC可以阻止元素被浮动元素覆盖
正常情况下,浮动的元素会脱离普通文档流,会覆盖着普通文档流的元素上。所以下面的代码里:
1 |
|
效果如下所示:

之所以是这样,是因为上文的 规则5: 每个元素的左边,与包含的盒子的左边相接触,即使存在浮动也是如此;
所以要想改变效果,使其互补干扰,就得利用规则6 :BFC的区域不会与float重叠,让 <div class=”main”> 也能触发BFC的性质。
将代码改成下列所示:
1 |
|
效果如下所示:

通过这种方法,就能 用来实现 两列的自适应布局。
简要介绍IFC
框会从包含块的顶部开始,一个接一个地水平摆放。
摆放这些框时,它们在水平方向的 内外边距+边框 所占用的空间都会被考虑;
在垂直方向上,这些框可能会以不同形式来对齐;
水平的margin、padding、border有效,垂直无效,不能指定宽高。行框的宽度是 由包含块和存在的浮动来决定;
行框的高度 由行高来决定。
题目:谈一谈你对CSS盒模型的认识
专业的面试,一定会问
CSS盒模型。对于这个题目,我们要回答一下几个方面:
- 基本概念:
content、padding、margin - 标准盒模型、
IE盒模型的区别。不要漏说了IE盒模型,通过这个问题,可以筛选一部分人 CSS如何设置这两种模型(即:如何设置某个盒子为其中一个模型)?如果回答了上面的第二条,还会继续追问这一条。JS如何设置、获取盒模型对应的宽和高?这一步,已经有很多人答不上来了。- 实例题:根据盒模型解释边距重叠。
前四个方面是逐渐递增,第五个方面,却鲜有人知。
BFC(边距重叠解决方案)或IFC。
如果能回答第五条,就会引出第六条。
BFC是面试频率较高的。
总结:以上几点,从上到下,知识点逐渐递增,知识面从理论、CSS、JS,又回到CSS理论
接下来,我们把上面的六条,依次讲解。
标准盒模型和IE盒子模型
标准盒子模型:

IE盒子模型:

上图显示:
在
CSS盒子模型 (Box Model) 规定了元素处理元素的几种方式:
width和height:内容的宽度、高度(不是盒子的宽度、高度)。padding:内边距。border:边框。margin:外边距。
CSS盒模型和IE盒模型的区别:
在标准盒子模型中,width 和 height 指的是内容区域的宽度和高度。增加内边距、边框和外边距不会影响内容区域的尺寸,但是会增加元素框的总尺寸。
IE盒子模型中,width 和 height 指的是内容区域+border+padding的宽度和高度。
CSS如何设置这两种模型
代码如下:
1 | /* 设置当前盒子为 标准盒模型(默认) */ |
备注:盒子默认为标准盒模型。
JS如何设置、获取盒模型对应的宽和高
方式一:通过
DOM节点的style样式获取
1 | element.style.width/height; |
缺点:通过这种方式,只能获取行内样式,不能获取
内嵌的样式和外链的样式。
这种方式有局限性,但应该了解。
方式二(通用型)
1 | window.getComputedStyle(element).width/height; |
方式二能兼容
Chrome、火狐。是通用型方式。
方式三(IE独有的)
1 | element.currentStyle.width/height; |
和方式二相同,但这种方式只有IE独有。获取到的即时运行完之后的宽高(三种css样式都可以获取)。
方式四
1 | element.getBoundingClientRect().width/height; |
此
api的作用是:获取一个元素的绝对位置。绝对位置是视窗viewport左上角的绝对位置。此api可以拿到四个属性:left、top、width、height。
总结:
上面的四种方式,要求能说出来区别,以及哪个的通用型更强。
margin塌陷/margin重叠
标准文档流中,竖直方向的margin不叠加,只取较大的值作为margin(水平方向的margin是可以叠加的,即水平方向没有塌陷现象)。
PS:如果不在标准流,比如盒子都浮动了,那么两个盒子之间是没有
margin重叠的现象的。
我们来看几个例子。
兄弟元素之间
如下图所示:

子元素和父元素之间
1 |
|
上面的代码中,儿子的
height是100px,magin-top是10px。注意,此时父亲的height是100,而不是110。因为儿子和父亲在竖直方向上,共一个margin。
儿子这个盒子:

父亲这个盒子:

上方代码中,如果我们给父亲设置一个属性:
overflow: hidden,就可以避免这个问题,此时父亲的高度是110px,这个用到的就是BFC(下一段讲解)。
善于使用父亲的padding,而不是儿子的margin
其实,这一小段讲的内容与上一小段相同,都是讲父子之间的margin重叠。
我们来看一个奇怪的现象。现在有下面这样一个结构:(div中放一个p)
1 | <div> |
上面的结构中,我们尝试通过给儿子
p一个margin-top:50px;的属性,让其与父亲保持50px的上边距。结果却看到了下面的奇怪的现象:

此时我们给父亲
div加一个border属性,就正常了:

如果父亲没有
border,那么儿子的margin实际上踹的是“流”,踹的是这“行”。所以,父亲整体也掉下来了。
margin这个属性,本质上描述的是兄弟和兄弟之间的距离; 最好不要用这个marign表达父子之间的距离。
所以,如果要表达父子之间的距离,我们一定要善于使用父亲的padding,而不是儿子的`margin。
BFC(边距重叠解决方案)
BFC(Block Formatting Context):块级格式化上下文。你可以把它理解成一个独立的区域。
另外还有个概念叫IFC。不过,BFC问得更多。
BFC 的原理/BFC的布局规则【非常重要】
BFC的原理,其实也就是BFC的渲染规则(能说出以下四点就够了)。包括:
- BFC 内部的子元素,在垂直方向,边距会发生重叠。
- BFC在页面中是独立的容器,外面的元素不会影响里面的元素,反之亦然。(稍后看
举例1) - BFC区域不与旁边的
float box区域重叠。(可以用来清除浮动带来的影响)。(稍后看举例2) - 计算
BFC的高度时,浮动的子元素也参与计算。(稍后看举例3)
如何生成BFC
有以下几种方法:
- 方法1:
overflow: 不为visible,可以让属性是hidden、auto。【最常用】 - 方法2:浮动中:
float的属性值不为none。意思是,只要设置了浮动,当前元素就创建了BFC。 - 方法3:定位中:只要
posiiton的值不是 static或者是relative即可,可以是absolute或fixed,也就生成了一个BFC。 - 方法4:
display为inline-block,table-cell,table-caption,flex,inline-flex
BFC 的应用
举例1:解决 margin 重叠
当父元素和子元素发生
margin重叠时,解决办法:给子元素或父元素创建BFC。
比如说,针对下面这样一个 div 结构:
1 | <div class="father"> |
上面的
div结构中,如果父元素和子元素发生margin重叠,我们可以给子元素创建一个BFC,就解决了:
1 | <div class="father"> |
因为第二条:BFC区域是一个独立的区域,不会影响外面的元素。
举例2:BFC区域不与float区域重叠:
针对下面这样一个div结构;
1 |
|
效果如下:

上图中,由于右侧标准流里的元素,比左侧浮动的元素要高,导致右侧有一部分会跑到左边的下面去。
如果要解决这个问题,可以将右侧的元素创建BFC,因为第三条:BFC区域不与float box区域重叠。解决办法如下:(将right区域添加overflow属性)
1 | <div class="right" style="overflow: hidden"> |

上图表明,解决之后,father-layout的背景色显现出来了,说明问题解决了。
举例3:清除浮动
现在有下面这样的结构:
1 |
|
效果如下:

上面的代码中,儿子浮动了,但由于父亲没有设置高度,导致看不到父亲的背景色(此时父亲的高度为0)。正所谓有高度的盒子,才能关住浮动。
如果想要清除浮动带来的影响,方法一是给父亲设置高度,然后采用隔墙法。方法二是 BFC:给父亲增加
overflow=hidden属性即可, 增加之后,效果如下:

为什么父元素成为BFC之后,就有了高度呢?这就回到了第四条:计算BFC的高度时,浮动元素也参与计算。意思是,在计算BFC的高度时,子元素的float box也会参与计算
DOM事件的总结
知识点主要包括以下几个方面:
- 基本概念:
DOM事件的级别
面试不会直接问你,DOM有几个级别。但会在题目中体现:“请用
DOM2….”。
DOM事件模型、DOM事件流
面试官如果问你“DOM事件模型”,你不一定知道怎么回事。其实说的就是捕获和冒泡。
DOM事件流,指的是事件传递的三个阶段。
- 描述
DOM事件捕获的具体流程
讲的是事件的传递顺序。参数为
false(默认)、参数为true,各自代表事件在什么阶段触发。
能回答出来的人,寥寥无几。也许有些人可以说出一大半,但是一字不落的人,极少。
Event对象的常见应用(Event的常用api方法)
DOM事件的知识点,一方面包括事件的流程;另一方面就是:怎么去注册事件,也就是监听用户的交互行为。第三点:在响应时,Event对象是非常重要的。
自定义事件(非常重要)
一般人可以讲出事件和注册事件,但是如果让你讲自定义事件,能知道的人,就更少了。
DOM事件的级别
DOM事件的级别,准确来说,是DOM标准定义的级别。包括:
DOM0的写法:
1 | element.onclick = function () { |
上面的代码是在
js中的写法;如果要在html中写,写法是:在onclick属性中,加js语句。
DOM2的写法:
1 | element.addEventListener('click', function () { |
【重要】上面的第三参数中,true表示事件在捕获阶段触发,false表示事件在冒泡阶段触发(默认)。如果不写,则默认为false。
DOM3的写法:
1 | element.addEventListener('keyup', function () { |
DOM3中,增加了很多事件类型,比如鼠标事件、键盘事件等。
PS:为何事件没有
DOM1的写法呢?因为,DOM1标准制定的时候,没有涉及与事件相关的内容。
总结:关于“DOM事件的级别”,能回答出以上内容即可,不会出题目让你做。
DOM事件模型
DOM事件模型讲的就是捕获和冒泡,一般人都能回答出来。
- 捕获:从上往下。
- 冒泡:从下(目标元素)往上。
DOM事件流
DOM事件流讲的就是:浏览器在于当前页面做交互时,这个事件是怎么传递到页面上的。
完整的事件流,分三个阶段:
- 捕获:从
window对象传到 目标元素。 - 目标阶段:事件通过捕获,到达目标元素,这个阶段就是目标阶段。
- 冒泡:从目标元素传到
Window对象。


描述DOM事件捕获的具体流程
很少有人能说完整。
捕获的流程

说明:捕获阶段,事件依次传递的顺序是:window –> document –> html–> body –> 父元素、子元素、目标元素。
- PS1:第一个接收到事件的对象是 window(有人会说
body,有人会说html,这都是错误的)。 - PS2:
JS中涉及到DOM对象时,有两个对象最常用:window、doucument。它们俩也是最先获取到事件的。
代码如下:
1 | window.addEventListener("click", function () { |
补充一个知识点:
在
js中:
- 如果想获取
body节点,方法是:document.body; - 但是,如果想获取
html节点,方法是document.documentElement。
冒泡的流程
与捕获的流程相反
Event对象的常见 api 方法
用户做的是什么操作(比如,是敲键盘了,还是点击鼠标了),这些事件基本都是通过
Event对象拿到的。这些都比较简单,我们就不讲了。我们来看看下面这几个方法:
方法一
1 | event.preventDefault(); |
- 解释:阻止默认事件。
- 比如,已知
<a>标签绑定了click事件,此时,如果给<a>设置了这个方法,就阻止了链接的默认跳转。
方法二:阻止冒泡
这个在业务中很常见。
有的时候,业务中不需要事件进行冒泡。比如说,业务这样要求:单击子元素做事件
A,单击父元素做事件B,如果不阻止冒泡的话,出现的问题是:单击子元素时,子元素和父元素都会做事件A。这个时候,就要用到阻止冒泡了。
w3c的方法:(火狐、谷歌、IE11)
1 | event.stopPropagation(); |
IE10以下则是:
1 | event.cancelBubble = true; |
兼容代码如下:
1 | box3.onclick = function (event) { |
上方代码中,我们对
box3进行了阻止冒泡,产生的效果是:事件不会继续传递到father、grandfather、body了。
方法三:设置事件优先级
1 | event.stopImmediatePropagation(); |
这个方法比较长,一般人没听说过。解释如下:
比如说,我用
addEventListener给某按钮同时注册了事件A、事件B。此时,如果我单击按钮,就会依次执行事件A和事件B。现在要求:单击按钮时,只执行事件A,不执行事件B。该怎么做呢?这是时候,就可以用到stopImmediatePropagation方法了。做法是:在事件A的响应函数中加入这句话。
大家要记住
event有这个方法。
属性4、属性5(事件委托中用到)
1 |
|
上面这两个属性,在事件委托中经常用到。
总结:上面这几项,非常重要,但是容易弄混淆。
自定义事件
自定义事件的代码如下:
1 | var myEvent = new Event('clickTest'); |
上面这个事件是定义完了之后,就直接自动触发了。在正常的业务中,这个事件一般是和别的事件结合用的。比如延时器设置按钮的动作:
1 | var myEvent = new Event('clickTest'); |
浅析CSS的性能优化:transform与position区别、硬件加速工作原理及注意事项、强制使用GPU渲染的友好CSS属性
在网上看到一个这样的问题: transform与position:absolute 有什么区别?查阅资料后发现这道题目其实不简单,涉及到重排、重绘、硬件加速等网页优化的知识。
问题背景
过去几年,我们常常会听说硬件加速给移动端带来了巨大的体验提升,但是即使对于很多经验丰富的开发者来说,恐怕对其背后的工作原理也是模棱两可,更不要合理地将其运用到网页的动画效果中了。
1. position + top/left 的效果
下面让我们来看一个动画效果,在该动画中包含了几个堆叠在一起的球并让它们沿相同路径移动。最简单的方式就是实时调整它们的 left 和 top 属性,使用 css 动画实现。
1 |
|
在运行的时候,即使是在电脑浏览器上也会隐约觉得动画的运行并不流畅,动画有些停顿的感觉,更不要提在移动端达到 60fps 的流畅效果了。这是因为top和left的改变会触发浏览器的 reflow 和 repaint ,整个动画过程都在不断触发浏览器的重新渲染,这个过程是很影响性能的。
2. transform 的效果
为了解决这个问题,我们使用 transform 中的 translate() 来替换 top 和 left ,重写一下这个动画效果。
1 |
|
这时候会发现整个动画效果流畅了很多,在动画移动的过程中也没有发生repaint和reflow。
那么,为什么 transform 没有触发 repaint 呢?原因就是:transform 动画由GPU控制,支持硬件加速,并不需要软件方面的渲染。
硬件加速工作原理
浏览器接收到页面文档后,会将文档中的标记语言解析为DOM树,DOM树和CSS结合后形成浏览器构建页面的渲染树,渲染树中包含了大量的渲染元素,每一个渲染元素会被分到一个图层中,每个图层又会被加载到GPU形成渲染纹理,而图层在GPU中 transform 是不会触发 repaint 的,这一点非常类似3D绘图功能,最终这些使用transform的图层都会使用独立的合成器进程进行处理。
在我们的示例中,CSS transform 创建了一个新的复合图层,可以被GPU直接用来执行 transform 操作。在chrome开发者工具中开启“show layer borders”选项后,每个复合图层就会显示一条黄色的边界。示例中的球就处于一个独立的复合图层,移动时的变化也是独立的。
此时,你也许会问:浏览器什么时候会创建一个独立的复合图层呢?事实上一般是在以下几种情况下:
- 3D 或者 CSS transform
- video或canvas标签
- CSS filters
- 元素覆盖时,比如使用了 z-index 属性
等一下,上面的示例使用的是 2D transform 而不是 3D transform 啊?这个说法没错,所以在timeline中我们可以看到:动画开始和结束的时候发生了两次 repaint 操作。

3D 和 2D transform 的区别就在于,浏览器在页面渲染前为3D动画创建独立的复合图层,而在运行期间为2D动画创建。
动画开始时,生成新的复合图层并加载为GPU的纹理用于初始化 repaint,然后由GPU的复合器操纵整个动画的执行,最后当动画结束时,再次执行 repaint 操作删除复合图层。
使用 GPU 渲染元素
能触发GPU渲染的属性
并不是所有的CSS属性都能触发GPU的硬件加速,实际上只有少数属性可以,比如下面的这些:
- transform
- opacity
- filter
强制使用GPU渲染
为了避免 2D transform 动画在开始和结束时发生的 repaint 操作,我们可以硬编码一些样式来解决这个问题:
1 | .exam1 { |
这段代码的作用就是让浏览器执行 3D transform,浏览器通过该样式创建了一个独立图层,图层中的动画则有GPU进行预处理并且触发了硬件加速。
使用硬件加速需要注意的事项
使用硬件加速并不是十全十美的事情,比如:
- 内存。如果GPU加载了大量的纹理,那么很容易就会发生内存问题,这一点在移动端浏览器上尤为明显,所以,一定要牢记不要让页面的每个元素都使用硬件加速。
- 使用GPU渲染会影响字体的抗锯齿效果。这是因为GPU和CPU具有不同的渲染机制,即使最终硬件加速停止了,文本还是会在动画期间显示得很模糊。
will-change
浏览器还提出了一个 will-change 属性,该属性允许开发者告知浏览器哪一个属性即将发生变化,从而为浏览器对该属性进行优化提供了时间。下面是一个使用 will-change 的示例
1 | .exam3 { |
缺点在于其兼容性不大好。
总结
- transform 会使用 GPU 硬件加速,性能更好;position + top/left 会触发大量的重绘和回流,性能影响较大。
- 硬件加速的工作原理是创建一个新的复合图层,然后使用合成线程进行渲染。
- 3D 动画 与 2D 动画的区别;2D动画会在动画开始和动画结束时触发2次重新渲染。
- 使用GPU可以优化动画效果,但是不要滥用,会有内存问题。
- 理解强制触发硬件加速的 transform 技巧,使用对GPU友好的CSS属性。
五、渲染机制
浏览器的渲染机制一般分为以下几个步骤
- 处理
HTML并构建DOM树。 - 处理
CSS构建CSSOM树。 - 将
DOM与CSSOM合并成一个渲染树。 - 根据渲染树来布局,计算每个节点的位置。
- 调用
GPU绘制,合成图层,显示在屏幕上
- 在构建 CSSOM 树时,会阻塞渲染,直至 CSSOM 树构建完成。并且构建 CSSOM 树是一个十分消耗性能的过程,所以应该尽量保证层级扁平,减少过度层叠,越是具体的 CSS 选择器,执行速度越慢
- 当 HTML 解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件。并且 CSS 也会影响 JS 的执行,只有当解析完样式表才会执行 JS,所以也可以认为这种情况下,CSS 也会暂停构建 DOM
5.1 图层
一般来说,可以把普通文档流看成一个图层。特定的属性可以生成一个新的图层。不同的图层渲染互不影响,所以对于某些频繁需要渲染的建议单独生成一个新图层,提高性能。但也不能生成过多的图层,会引起反作用
通过以下几个常用属性可以生成新图层
- 3D 变换:
translate3d、translateZ will-changevideo、iframe标签- 通过动画实现的
opacity动画转换 position: fixed
5.2 重绘(Repaint)和回流(Reflow)
- 重绘是当节点需要更改外观而不会影响布局的,比如改变 color 就叫称为重绘
- 回流是布局或者几何属性需要改变就称为回流
回流必定会发生重绘,重绘不一定会引发回流。回流所需的成本比重绘高的多,改变深层次的节点很可能导致父节点的一系列回流
所以以下几个动作可能会导致性能问题:
- 改变 window 大小
- 改变字体
- 添加或删除样式
- 文字改变
- 定位或者浮动
- 盒模型
很多人不知道的是,重绘和回流其实和 Event loop 有关
- 当 Event loop 执行完
Microtasks后,会判断document是否需要更新。因为浏览器是60Hz的刷新率,每16ms才会更新一次。 - 然后判断是否有
resize或者scroll,有的话会去触发事件,所以resize和scroll事件也是至少16ms才会触发一次,并且自带节流功能。 - 判断是否触发了
media query - 更新动画并且发送事件
- 判断是否有全屏操作事件
- 执行
requestAnimationFrame回调 - 执行
IntersectionObserver回调,该方法用于判断元素是否可见,可以用于懒加载上,但是兼容性不好 - 更新界面
- 以上就是一帧中可能会做的事情。如果在一帧中有空闲时间,就会去执行
requestIdleCallback回调
减少重绘和回流
- 使用
translate替代top - 使用
visibility替换display: none,因为前者只会引起重绘,后者会引发回流(改变了布局) - 不要使用
table布局,可能很小的一个小改动会造成整个 table 的重新布局 - 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使用
requestAnimationFrame CSS选择符从右往左匹配查找,避免DOM深度过深- 将频繁运行的动画变为图层,图层能够阻止该节点回流影响别的元素。比如对于
video标签,浏览器会自动将该节点变为图层
深入解析你不知道的 EventLoop 和浏览器渲染、帧动画、空闲回调
前言
关于 Event Loop 的文章很多,但是有很多只是在讲「宏任务」、「微任务」,我先提出几个问题:
- 每一轮 Event Loop 都会伴随着渲染吗?
- requestAnimationFrame 在哪个阶段执行,在渲染前还是后?在 microTask 的前还是后?
- requestIdleCallback 在哪个阶段执行?如何去执行?在渲染前还是后?在 microTask 的前还是后?
- resize、scroll 这些事件是何时去派发的。
这些问题并不是刻意想刁难你,如果你不知道这些,那你可能并不能在遇到一个动画需求的时候合理的选择 requestAnimationFrame,你可能在做一些需求的时候想到了 requestIdleCallback,但是你不知道它运行的时机,只是胆战心惊的去用它,祈祷不要出线上 bug。
这也是本文想要从规范解读入手,深挖底层的动机之一。本文会酌情从规范中排除掉一些比较晦涩难懂,或者和主流程不太相关的概念。更详细的版本也可以直接去读这个规范,不过比较费时费力。
事件循环
我们先依据HTML 官方规范从浏览器的事件循环讲起,因为剩下的 API 都在这个循环中进行,它是浏览器调度任务的基础。
定义
为了协调事件,用户交互,脚本,渲染,网络任务等,浏览器必须使用本节中描述的事件循环。
流程
从任务队列中取出一个宏任务并执行。
检查微任务队列,执行并清空微任务队列,如果在微任务的执行中又加入了新的微任务,也会在这一步一起执行。
进入更新渲染阶段,判断是否需要渲染,这里有一个 rendering opportunity 的概念,也就是说不一定每一轮 event loop 都会对应一次浏览器渲染,要根据屏幕刷新率、页面性能、页面是否在后台运行来共同决定,通常来说这个渲染间隔是固定的。(所以多个 task 很可能在一次渲染之间执行)
浏览器会尽可能的保持帧率稳定,例如页面性能无法维持 60fps(每 16.66ms 渲染一次)的话,那么浏览器就会选择 30fps 的更新速率,而不是偶尔丢帧。
如果浏览器上下文不可见,那么页面会降低到 4fps 左右甚至更低。
如果满足以下条件,也会跳过渲染:
- 浏览器判断更新渲染不会带来视觉上的改变。
- map of animation frame callbacks 为空,也就是帧动画回调为空,可以通过 requestAnimationFrame 来请求帧动画。
如果上述的判断决定本轮不需要渲染,那么下面的几步也不会继续运行:
This step enables the user agent to prevent the steps below from running for other reasons, for example, to ensure certain tasks are executed immediately after each other, with only microtask checkpoints interleaved (and without, e.g., animation frame callbacks interleaved). Concretely, a user agent might wish to coalesce timer callbacks together, with no intermediate rendering updates. 有时候浏览器希望两次「定时器任务」是合并的,他们之间只会穿插着 microTask的执行,而不会穿插屏幕渲染相关的流程(比如requestAnimationFrame,下面会写一个例子)。对于需要渲染的文档,如果窗口的大小发生了变化,执行监听的
resize方法。对于需要渲染的文档,如果页面发生了滚动,执行
scroll方法。对于需要渲染的文档,执行帧动画回调,也就是
requestAnimationFrame的回调。(后文会详解)对于需要渲染的文档,执行
IntersectionObserver的回调。对于需要渲染的文档,重新渲染绘制用户界面。
判断
task队列和microTask队列是否都为空,如果是的话,则进行Idle空闲周期的算法,判断是否要执行requestIdleCallback的回调函数。(后文会详解)
对于 resize 和 scroll 来说,并不是到了这一步才去执行滚动和缩放,那岂不是要延迟很多?浏览器当然会立刻帮你滚动视图,根据CSSOM 规范所讲,浏览器会保存一个 pending scroll event targets,等到事件循环中的 scroll 这一步,去派发一个事件到对应的目标上,驱动它去执行监听的回调函数而已。resize 也是同理。
可以在这个流程中仔细看一下「宏任务」、「微任务」、「渲染」之间的关系。
多任务队列
多任务队列
task 队列并不是我们想象中的那样只有一个,根据规范里的描述:
An event loop has one or more task queues. For example, a user agent could have one task queue for mouse and key events (to which the user interaction task source is associated), and another to which all other task sources are associated. Then, using the freedom granted in the initial step of the event loop processing model, it could give keyboard and mouse events preference over other tasks three-quarters of the time, keeping the interface responsive but not starving other task queues. Note that in this setup, the processing model still enforces that the user agent would never process events from any one task source out of order.
事件循环中可能会有一个或多个任务队列,这些队列分别为了处理:
- 鼠标和键盘事件
- 其他的一些 Task
览器会在保持任务顺序的前提下,可能分配四分之三的优先权给鼠标和键盘事件,保证用户的输入得到最高优先级的响应,而剩下的优先级交给其他 Task,并且保证不会“饿死”它们。
这个规范也导致 Vue 2.0.0-rc.7 这个版本 nextTick 采用了从微任务 MutationObserver 更换成宏任务 postMessage 而导致了一个 Issue。
目前由于一些“未知”的原因,jsfiddle 的案例打不开了。简单描述一下就是采用了 task 实现的 nextTick,在用户持续滚动的情况下 nextTick 任务被延后了很久才去执行,导致动画跟不上滚动了。
迫于无奈,尤大还是改回了 microTask 去实现 nextTick,当然目前来说 promise.then 微任务已经比较稳定了,并且 Chrome 也已经实现了 queueMicroTask 这个官方 API。不久的未来,我们想要调用微任务队列的话,也可以节省掉实例化 Promise 在开销了。
从这个 Issue 的例子中我们可以看出,稍微去深入了解一下规范还是比较有好处的,以免在遇到这种比较复杂的 Bug 的时候一脸懵逼。
requestAnimationFrame
在解读规范的过程中,我们发现 requestAnimationFrame 的回调有两个特征:
- 在重新渲染前调用。
- 很可能在宏任务之后不调用。
我们来分析一下,为什么要在重新渲染前去调用?因为 rAF 是官方推荐的用来做一些流畅动画所应该使用的 API,做动画不可避免的会去更改 DOM,而如果在渲染之后再去更改 DOM,那就只能等到下一轮渲染机会的时候才能去绘制出来了,这显然是不合理的。
rAF在浏览器决定渲染之前给你最后一个机会去改变 DOM 属性,然后很快在接下来的绘制中帮你呈现出来,所以这是做流畅动画的不二选择。下面我用一个 setTimeout的例子来对比。
闪烁动画
假设我们现在想要快速的让屏幕上闪烁 红、蓝两种颜色,保证用户可以观察到,如果我们用 setTimeout 来写,并且带着我们长期的误解「宏任务之间一定会伴随着浏览器绘制」,那么你会得到一个预料之外的结果。
1 | setTimeout(() => { |

以看出这个结果是非常不可控的,如果这两个 Task 之间正好遇到了浏览器认定的渲染机会,那么它会重绘,否则就不会。由于这俩宏任务的间隔周期太短了,所以很大概率是不会的。
如果你把延时调整到 17ms 那么重绘的概率会大很多,毕竟这个是一般情况下 60fps 的一个指标。但是也会出现很多不绘制的情况,所以并不稳定。
如果你依赖这个 API 来做动画,那么就很可能会造成「掉帧」。
接下来我们换成 rAF 试试?我们用一个递归函数来模拟 10 次颜色变化的动画。
1 | let i = 10; |
这里由于颜色变化太快,gif 录制软件没办法截出这么高帧率的颜色变换,所以各位可以放到浏览器中自己执行一下试试,我这边直接抛结论,浏览器会非常规律的把这 10 组也就是 20 次颜色变化绘制出来,可以看下 performance 面板记录的表现:

定时器合并
在第一节解读规范的时候,第 4 点中提到了,定时器宏任务可能会直接跳过渲染。
按照一些常规的理解来说,宏任务之间理应穿插渲染,而定时器任务就是一个典型的宏任务,看一下以下的代码:
1 | setTimeout(() => { |
从直觉上来看,顺序是不是应该是:
1 | mic1 |
呢?也就是每一个宏任务之后都紧跟着一次渲染。
实际上不会,浏览器会合并这两个定时器任务:
1 | mic1 |
requestIdleCallback
草案解读
我们都知道 requestIdleCallback 是浏览器提供给我们的空闲调度算法,关于它的简介可以看 MDN 文档,意图是让我们把一些计算量较大但是又没那么紧急的任务放到空闲时间去执行。不要去影响浏览器中优先级较高的任务,比如动画绘制、用户输入等等。
React 的时间分片渲染就想要用到这个 API,不过目前浏览器支持的不给力,他们是自己去用 postMessage 实现了一套。
渲染有序进行
首先看一张图,很精确的描述了这个 API 的意图:

当然,这种有序的 浏览器 -> 用户 -> 浏览器 -> 用户 的调度基于一个前提,就是我们要把任务切分成比较小的片,不能说浏览器把空闲时间让给你了,你去执行一个耗时 10s 的任务,那肯定也会把浏览器给阻塞住的。这就要求我们去读取 rIC 提供给你的 deadline 里的时间,去动态的安排我们切分的小任务。浏览器信任了你,你也不能辜负它呀。
渲染长期空闲

还有一种情况,也有可能在几帧的时间内浏览器都是空闲的,并没有发生任何影响视图的操作,它也就不需要去绘制页面:
这种情况下为什么还是会有 50ms 的 deadline 呢?是因为浏览器为了提前应对一些可能会突发的用户交互操作,比如用户输入文字。如果给的时间太长了,你的任务把主线程卡住了,那么用户的交互就得不到回应了。50ms 可以确保用户在无感知的延迟下得到回应。
MDN 文档中的幕后任务协作调度 API 介绍的比较清楚,来根据里面的概念做个小实验:
屏幕中间有个红色的方块,把 MDN 文档中requestAnimationFrame的范例部分的动画代码直接复制过来。
草案中还提到:
当浏览器判断这个页面对用户不可见时,这个回调执行的频率可能被降低到 10 秒执行一次,甚至更低。这点在解读 EventLoop 中也有提及。
如果浏览器的工作比较繁忙的时候,不能保证它会提供空闲时间去执行 rIC 的回调,而且可能会长期的推迟下去。所以如果你需要保证你的任务在一定时间内一定要执行掉,那么你可以给 rIC 传入第二个参数 timeout。
这会强制浏览器不管多忙,都在超过这个时间之后去执行 rIC 的回调函数。所以要谨慎使用,因为它会打断浏览器本身优先级更高的工作。最长期限为 50 毫秒,是根据研究得出的,研究表明,人们通常认为 100 毫秒内对用户输入的响应是瞬时的。 将闲置截止期限设置为 50ms 意味着即使在闲置任务开始后立即发生用户输入,浏览器仍然有剩余的 50ms 可以在其中响应用户输入而不会产生用户可察觉的滞后。
每次调用 timeRemaining() 函数判断是否有剩余时间的时候,如果浏览器判断此时有优先级更高的任务,那么会动态的把这个值设置为 0,否则就是用预先设置好的 deadline - now 去计算。
这个 timeRemaining() 的计算非常动态,会根据很多因素去决定,所以不要指望这个时间是稳定的。
动画例子
滚动
如果我鼠标不做任何动作和交互,直接在控制台通过 rIC 去打印这次空闲任务的剩余时间,一般都稳定维持在 49.xx ms,因为此时浏览器没有什么优先级更高的任务要去处理。
1 | requestIdleCallback((deadline) => console.log(deadline.timeRemaining())) |

而如果我不停的滚动浏览器,不断的触发浏览器的重新绘制的话,这个时间就变的非常不稳定了。

通过这个例子,你可以更加有体感的感受到什么样叫做「繁忙」,什么样叫做「空闲」。
动画
这个动画的例子很简单,就是利用rAF在每帧渲染前的回调中把方块的位置向右移动 10px。
1 |
|
注意在最后我加了一个 requestIdleCallback 的函数,回调里会 alert(‘rIC’),来看一下演示效果:

alert 在最开始的时候就执行了,为什么会这样呢一下,想一下「空闲」的概念,我们每一帧仅仅是把 left 的值移动了一下,做了这一个简单的渲染,没有占满空闲时间,所以可能在最开始的时候,浏览器就找到机会去调用 rIC 的回调函数了。
我们简单的修改一下 step 函数,在里面加一个很重的任务,1000 次循环打印。
1 |
|
再来看一下它的表现:

其实和我们预期的一样,由于浏览器的每一帧都”太忙了”,导致它真的就无视我们的 rIC 函数了。
如果给 rIC 函数加一个 timeout 呢:
1 |
|
效果如下:

浏览器会在大概 500ms 的时候,不管有多忙,都去强制执行 rIC 函数,这个机制可以防止我们的空闲任务被“饿死”。
总结
通过本文的学习过程,我自己也打破了很多对于 Event Loop 以及 rAF、rIC 函数的固有错误认知,通过本文我们可以整理出以下的几个关键点。
- 事件循环不一定每轮都伴随着重新渲染,但是如果有微任务,一定会伴随着微任务执行。
- 决定浏览器视图是否渲染的因素很多,浏览器是非常聪明的。
- requestAnimationFrame在重新渲染屏幕之前执行,非常适合用来做动画。
- requestIdleCallback在渲染屏幕之后执行,并且是否有空执行要看浏览器的调度,如果你一定要它在某个时间内执行,请使用 timeout参数。
- resize和scroll事件其实自带节流,它只在 Event Loop 的渲染阶段去派发事件到 EventTarget 上。
canvas
Canvas API 提供了一个通过JavaScript 和 HTML的<canvas>元素来绘制图形的方式。它可以用于动画、游戏画面、数据可视化、图片编辑以及实时视频处理等方面。
Canvas API主要聚焦于2D图形。而同样使用<canvas>元素的 WebGL API 则用于绘制硬件加速的2D和3D图形。
标签
1 | <canvas width="600" height="400" id="canvas"></canvas> |
不给宽高的话默认是300+150
怎么用
1 | // 拿到canvas |
相关的api及用法
1 |
|
效果如下所示:

画矩形
1 | // 直接传入 x, y, width, height, 就可以绘制一个矩形 |
1 | // 直接创建一个填充的矩形 |
圆形绘制
1 | // x轴是0度开始 |
画飞镖转盘
1 | for (var i = 0; i < 10; i++) { |
效果图如下所示:

线性渐变
1 | // 1. 需要创建出一个渐变对象 |
效果图如下所示:

径向渐变
1 | // 1. 创建渐变对象 |
效果图如下所示:

径向渐变画球
1 | //1. 创建一个径向渐变 |
效果图如下所示:

径向渐变画彩虹
1 | //实现彩虹,给里面的圆一个半径80是关键 |
效果图如下所示:

阴影效果
1 | //和css3相比, 阴影只能设一个, 不能设内阴影 |
效果图如下所示:

绘制文字api
1 | //绘制文字 |
效果图如下所示:

文字对齐方式
1 | //默认在left |
效果图如下所示:

垂直方向
1 | //默认是top |
效果图如下所示:

图片的绘制
3参模式: 将img从x, y的地方开始绘制, 图片有多大,就绘制多大,超出canvas的部分就不显示了
1 | //context.drawImage(img, x, y) |
5参模式(缩放模式), 就是将图片显示在画布上的某一块区域(x, y, w, h),如果这个区域的宽高和图片不一至,会被压缩或放大
1 | var image = new Image(); |
图片绘制的9参模式, 就是把原图(img)中的某一块(imagex,imagey,imagew,imageh)截取出来, 显示在画布的某个区域(canvasx, canvasy, canvasw, canvash)
1 | //理解关键: |
WebWorker和postMessage
概述
JavaScript 语言采用的是单线程模型,也就是说,所有任务只能在一个线程上完成,一次只能做一件事。前面的任务没做完,后面的任务只能等着。随着电脑计算能力的增强,尤其是多核 CPU 的出现,单线程带来很大的不便,无法充分发挥计算机的计算能力。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。
Worker 线程一旦新建成功,就会始终运行,不会被主线程上的活动(比如用户点击按钮、提交表单)打断。这样有利于随时响应主线程的通信。但是,这也造成了 Worker 比较耗费资源,不应该过度使用,而且一旦使用完毕,就应该关闭。
Web Worker 有以下几个使用注意点。
(1)同源限制
分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
(2)DOM 限制
Worker 线程所在的全局对象,与主线程不一样,无法读取主线程所在网页的 DOM 对象,也无法使用document、window、parent这些对象。但是,Worker 线程可以navigator对象和location对象。
(3)通信联系
Worker 线程和主线程不在同一个上下文环境,它们不能直接通信,必须通过消息完成。(postMessage)
(4)脚本限制
Worker 线程不能执行alert()方法和confirm()方法,但可以使用 XMLHttpRequest 对象发出 AJAX 请求。
(5)文件限制
Worker 线程无法读取本地文件,即不能打开本机的文件系统(file://),它所加载的脚本,必须来自网络。
基本用法
主线程
主线程采用new命令,调用Worker()构造函数,新建一个 Worker 线程。
1 | var worker = new Worker('work.js'); |
Worker()构造函数的参数是一个脚本文件,该文件就是 Worker 线程所要执行的任务。由于 Worker 不能读取本地文件,所以这个脚本必须来自网络。如果下载没有成功(比如404错误),Worker 就会默默地失败。
然后,主线程调用worker.postMessage()方法,向 Worker 发消息。
1 | worker.postMessage('Hello World'); |
接着,主线程通过worker.onmessage指定监听函数,接收子线程发回来的消息。
1 | worker.onmessage = function (event) { |
上面代码中,事件对象的data属性可以获取 Worker 发来的数据。
Worker 完成任务以后,主线程就可以把它关掉。
1 | worker.terminate(); |
Worker 线程
Worker 线程内部需要有一个监听函数,监听message事件。
1 | self.addEventListener('message', function (e) { |
上面代码中,self代表子线程自身,即子线程的全局对象。因此,等同于下面两种写法。
1 | // 写法一 |
除了使用self.addEventListener()指定监听函数,也可以使用self.onmessage指定。监听函数的参数是一个事件对象,它的data属性包含主线程发来的数据。self.postMessage()方法用来向主线程发送消息。
根据主线程发来的数据,Worker 线程可以调用不同的方法,下面是一个例子。
1 | self.addEventListener('message', function (e) { |
上面代码中,self.close()用于在 Worker 内部关闭自身。
Worker 加载脚本
Worker 内部如果要加载其他脚本,有一个专门的方法importScripts()。
1 | importScripts('script1.js'); |
该方法可以同时加载多个脚本。
1 | importScripts('script1.js', 'script2.js'); |
Worker 错误处理
主线程可以监听 Worker 是否发生错误。如果发生错误,Worker 会触发主线程的error事件。
1 | worker.onerror(function (event) { |
Worker 内部也可以监听error事件。
关闭 Worker
使用完毕,为了节省系统资源,必须关闭 Worker。
1 | // 主线程 |
数据通信
前面说过,主线程与 Worker 之间的通信内容,可以是文本,也可以是对象。需要注意的是,这种通信是拷贝关系,即是传值而不是传址,Worker 对通信内容的修改,不会影响到主线程。事实上,浏览器内部的运行机制是,先将通信内容串行化,然后把串行化后的字符串发给 Worker,后者再将它还原。
主线程与 Worker 之间也可以交换二进制数据,比如 File、Blob、ArrayBuffer 等类型,也可以在线程之间发送。下面是一个例子。
1 | // 主线程 |
但是,拷贝方式发送二进制数据,会造成性能问题。比如,主线程向 Worker 发送一个 500MB 文件,默认情况下浏览器会生成一个原文件的拷贝。为了解决这个问题,JavaScript 允许主线程把二进制数据直接转移给子线程,但是一旦转移,主线程就无法再使用这些二进制数据了,这是为了防止出现多个线程同时修改数据的麻烦局面。这种转移数据的方法,叫做Transferable Objects。这使得主线程可以快速把数据交给 Worker,对于影像处理、声音处理、3D 运算等就非常方便了,不会产生性能负担。
如果要直接转移数据的控制权,就要使用下面的写法。
1 | // Transferable Objects 格式 |
同页面的 Web Worker
通常情况下,Worker 载入的是一个单独的 JavaScript 脚本文件,但是也可以载入与主线程在同一个网页的代码。
1 |
|
上面是一段嵌入网页的脚本,注意必须指定<script>标签的type属性是一个浏览器不认识的值,上例是app/worker。
然后,读取这一段嵌入页面的脚本,用 Worker 来处理。
1 | var blob = new Blob([document.querySelector('#worker').textContent]); |
上面代码中,先将嵌入网页的脚本代码,转成一个二进制对象,然后为这个二进制对象生成 URL,再让 Worker 加载这个 URL。这样就做到了,主线程和 Worker 的代码都在同一个网页上面。
Worker 线程完成轮询
有时,浏览器需要轮询服务器状态,以便第一时间得知状态改变。这个工作可以放在 Worker 里面。
1 | function createWorker(f) { |
上面代码中,Worker 每秒钟轮询一次数据,然后跟缓存做比较。如果不一致,就说明服务端有了新的变化,因此就要通知主线程。
Worker 新建 Worker
Worker 线程内部还能再新建 Worker 线程(目前只有 Firefox 浏览器支持)。下面的例子是将一个计算密集的任务,分配到10个 Worker。
主线程代码如下。
1 | var worker = new Worker('worker.js'); |
Worker 线程代码如下。
1 | // worker.js |
上面代码中,Worker 线程内部新建了10个 Worker 线程,并且依次向这10个 Worker 发送消息,告知了计算的起点和终点。计算任务脚本的代码如下。
1 | // core.js |
API
主线程
浏览器原生提供Worker()构造函数,用来供主线程生成 Worker 线程。
1 | var myWorker = new Worker(jsUrl, options); |
Worker()构造函数,可以接受两个参数。第一个参数是脚本的网址(必须遵守同源政策),该参数是必需的,且只能加载 JS 脚本,否则会报错。第二个参数是配置对象,该对象可选。它的一个作用就是指定 Worker 的名称,用来区分多个 Worker 线程。
1 | // 主线程 |
Worker()构造函数返回一个 Worker 线程对象,用来供主线程操作 Worker。Worker 线程对象的属性和方法如下。
- Worker.onerror:指定 error 事件的监听函数。
- Worker.onmessage:指定 message 事件的监听函数,发送过来的数据在Event.data属性中。
- Worker.onmessageerror:指定 messageerror 事件的监听函数。发送的数据无法序列化成字符串时,会触发这个事件。
- Worker.postMessage():向 Worker 线程发送消息。
- Worker.terminate():立即终止 Worker 线程。
Worker 线程
Web Worker 有自己的全局对象,不是主线程的window,而是一个专门为 Worker 定制的全局对象。因此定义在window上面的对象和方法不是全部都可以使用。
Worker 线程有一些自己的全局属性和方法。
- self.name: Worker 的名字。该属性只读,由构造函数指定。
- self.onmessage:指定message事件的监听函数。
- self.onmessageerror:指定 messageerror 事件的监听函数。发送的数据无法序列化成字符串时,会触发这个事件。
- self.close():关闭 Worker 线程。
- self.postMessage():向产生这个 Worker 线程发送消息。
- self.importScripts():加载 JS 脚本。
四、Service Worker
Service workers 本质上充当Web应用程序与浏览器之间的代理服务器,也可以在网络可用时作为浏览器和网络间的代理。它们旨在(除其他之外)使得能够创建有效的离线体验,拦截网络请求并基于网络是否可用以及更新的资源是否驻留在服务器上来采取适当的动作。他们还允许访问推送通知和后台同步API
目前该技术通常用来做缓存文件,提高首屏速度
1 | // index.js |
打开页面,可以在开发者工具中的 Application 看到 Service Worker 已经启动了
在 Cache 中也可以发现我们所需的文件已被缓存
当我们重新刷新页面可以发现我们缓存的数据是从 Service Worker 中读取的
OffscreenCanvas 离屏Canvas — 使用Web Worker提高你的Canvas运行速度
OffscreenCanvas提供了一个可以脱离屏幕渲染的canvas对象。
有了离屏Canvas,你可以不用在你的主线程中绘制图像了!
Canvas 是一个非常受欢迎的表现方式,同时也是WebGL的入口。它能绘制图形,图片,展示动画,甚至是处理视频内容。它经常被用来在富媒体web应用中创建炫酷的用户界面或者是制作在线(web)游戏。
它是非常灵活的,这意味着绘制在Canvas的内容可以被编程。JavaScript就提供了Canvas的系列API。这些给了Canvas非常好的灵活度。
但同时,在一些现代化的web站点,脚本解析运行是实现流畅用户反馈的最大的问题之一。因为Canvas计算和渲染和用户操作响应都发生在同一个线程中,在动画中(有时候很耗时)的计算操作将会导致App卡顿,降低用户体验。
幸运的是, OffscreenCanvas 离屏Canvas可以非常棒的解决这个麻烦!
到目前为止,Canvas的绘制功能都与<canvas>标签绑定在一起,这意味着Canvas API和DOM是耦合的。而OffscreenCanvas,正如它的名字一样,通过将Canvas移出屏幕来解耦了DOM和Canvas API。
由于这种解耦,OffscreenCanvas的渲染与DOM完全分离了开来,并且比普通Canvas速度提升了一些,而这只是因为两者(Canvas和DOM)之间没有同步。但更重要的是,将两者分离后,Canvas将可以在Web Worker中使用,即使在Web Worker中没有DOM。这给Canvas提供了更多的可能性。
兼容性
这是一个实验中的功能
此功能某些浏览器尚在开发中,请参考浏览器兼容性表格以得到在不同浏览器中适合使用的前缀。由于该功能对应的标准文档可能被重新修订,所以在未来版本的浏览器中该功能的语法和行为可能随之改变。
支持浏览器如下图所示:

在Worker中使用OffscreenCanvas
它在窗口环境和web worker环境均有效。
Workers 是一个Web版的线程——它允许你在幕后运行你的代码。将你的一部分代码放到Worker中可以给你的主线程更多的空闲时间,这可以提高你的用户体验度。就像其没有DOM一样,直到现在,在Worker中都没有Canvas API。
而OffscreenCanvas并不依赖DOM,所以在Worker中Canvas API可以被某种方法来代替。下面是我在Worker中用OffscreenCanvas来计算渐变颜色的:
1 | // file: worker.js |
不要阻塞主线程
当我们将大量的计算移到Worker中运行时,可以释放主线程上的资源,这很有意思。我们可以使用transferControlToOffscreen 方法将常规的Canvas映射到OffscreenCanvas实例上。之后所有应用于OffscreenCanvas的操作将自动呈现在在源Canvas上。
1 |
|
OffscreenCanvas 是可转移的,除了将其指定为传递信息中的字段之一以外,还需要将其作为postMessage(传递信息给Worker的方法)中的第二个参数传递出去,以便可以在Worker线程的context(上下文)中使用它。
1 | // worker.js |
效果如下所示:

任务繁忙的主线程也不会影响在Worker上运行的动画。所以即使主线程非常繁忙,你也可以通过此功能来避免掉帧并保证流畅的动画
WebRTC的YUV媒体流数据的离屏渲染
从 WebRTC 中拿到的是 YUV 的原始视频流,将原始的 YUV 视频帧直接转发过来,通过第三方库直接在 Cavans 上渲染。
可以使用yuv-canvas和yuv-buffer第三方库来渲染YUV的原始视频流。
主进程render.js
1 | ; |
渲染Worker的代码如下所示:
1 | // render worker |
总结
如果你对图像绘画使用得非常多,OffscreenCanvas可以有效的提高你APP的性能。它使得Worker可以处理canvas的渲染绘制,让你的APP更好地利用了多核系统。
OffscreenCanvas在Chrome 69中已经不需要开启flag(实验性功能)就可以使用了。它也正在被 Firefox 实现。由于其API与普通canvas元素非常相似,所以你可以轻松地对其进行特征检测并循序渐进地使用它,而不会破坏现有的APP或库的运行逻辑。OffscreenCanvas在任何涉及到图形计算以及动画表现且与DOM关系并不密切(即依赖DOM API不多)的情况下,它都具有性能优势。
常见排序算法的时间复杂度,空间复杂度

前端需要注意哪些 SEO
- 合理的 title、description、keywords:搜索对着三项的权重逐个减小,title 值强调重点即可,重要关键词出现不要超过 2 次,而且要靠前,不同页面 title 要有所不同;description 把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面 description 有所不同;keywords 列举出重要关键词即可
- 语义化的 HTML 代码,符合 W3C 规范:语义化代码让搜索引擎容易理解网页
- 重要内容 HTML 代码放在最前:搜索引擎抓取 HTML 顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用 js 输出:爬虫不会执行 js 获取内容
- 少用 iframe:搜索引擎不会抓取 iframe 中的内容
- 非装饰性图片必须加 alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标
web 开发中会话跟踪的方法有哪些
- cookie
- session
- url 重写
- 隐藏 input
- ip 地址
<img>的title和alt有什么区别
title是global attributes之一,用于为元素提供附加的 advisory information。通常当鼠标滑动到元素上的时候显示。alt是<img>的特有属性,是图片内容的等价描述,用于图片无法加载时显示、读屏器阅读图片。可提图片高可访问性,除了纯装饰图片外都必须设置有意义的值,搜索引擎会重点分析。
doctype 是什么,举例常见 doctype 及特点
<!doctype>声明必须处于 HTML 文档的头部,在<html>标签之前,HTML5 中不区分大小写<!doctype>声明不是一个 HTML 标签,是一个用于告诉浏览器当前 HTML 版本的指令- 现代浏览器的 html 布局引擎通过检查 doctype 决定使用兼容模式还是标准模式对文档进行渲染,一些浏览器有一个接近标准模型。
- 在 HTML4.01 中
<!doctype>声明指向一个 DTD,由于 HTML4.01 基于 SGML,所以 DTD 指定了标记规则以保证浏览器正确渲染内容 - HTML5 不基于 SGML,所以不用指定 DTD
常见 dotype:
- HTML4.01 strict:不允许使用表现性、废弃元素(如 font)以及 frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> - HTML4.01 Transitional:允许使用表现性、废弃元素(如 font),不允许使用 frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> - HTML4.01 Frameset:允许表现性元素,废气元素以及 frameset。声明:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Frameset//EN" "http://www.w3.org/TR/html4/frameset.dtd"> - XHTML1.0 Strict:不使用允许表现性、废弃元素以及 frameset。文档必须是结构良好的 XML 文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> - XHTML1.0 Transitional:允许使用表现性、废弃元素,不允许 frameset,文档必须是结构良好的 XMl 文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> - XHTML 1.0 Frameset:允许使用表现性、废弃元素以及 frameset,文档必须是结构良好的 XML 文档。声明:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd"> - HTML 5:
<!doctype html>
HTML 全局属性(global attribute)有哪些
参考资料:MDN: html global attribute或者W3C HTML global-attributes
accesskey:设置快捷键,提供快速访问元素如aaa在 windows 下的 firefox 中按alt + shift + a可激活元素class:为元素设置类标识,多个类名用空格分开,CSS 和 javascript 可通过 class 属性获取元素contenteditable: 指定元素内容是否可编辑contextmenu: 自定义鼠标右键弹出菜单内容data-*: 为元素增加自定义属性dir: 设置元素文本方向draggable: 设置元素是否可拖拽dropzone: 设置元素拖放类型: copy, move, linkhidden: 表示一个元素是否与文档。样式上会导致元素不显示,但是不能用这个属性实现样式效果id: 元素 id,文档内唯一lang: 元素内容的的语言spellcheck: 是否启动拼写和语法检查style: 行内 css 样式tabindex: 设置元素可以获得焦点,通过 tab 可以导航title: 元素相关的建议信息translate: 元素和子孙节点内容是否需要本地化
什么是 web 语义化,有什么好处
web 语义化是指通过 HTML 标记表示页面包含的信息,包含了 HTML 标签的语义化和 css 命名的语义化。
HTML 标签的语义化是指:通过使用包含语义的标签(如 h1-h6)恰当地表示文档结构
css 命名的语义化是指:为 html 标签添加有意义的 class,id 补充未表达的语义,如Microformat通过添加符合规则的 class 描述信息
为什么需要语义化:
- 去掉样式后页面呈现清晰的结构
- 盲人使用读屏器更好地阅读
- 搜索引擎更好地理解页面,有利于收录
- 便于团队项目的可持续运作及维护
HTTP method
- 一台服务器要与 HTTP1.1 兼容,只要为资源实现GET和HEAD方法即可
- GET是最常用的方法,通常用于请求服务器发送某个资源。
- HEAD与 GET 类似,但服务器在响应中只返回首部,不返回实体的主体部分
- PUT让服务器用请求的主体部分来创建一个由所请求的 URL 命名的新文档,或者,如果那个 URL 已经存在的话,就用干这个主体替代它
- POST起初是用来向服务器输入数据的。实际上,通常会用它来支持 HTML 的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到要去的地方。
- TRACE会在目的服务器端发起一个环回诊断,最后一站的服务器会弹回一个 TRACE 响应并在响应主体中携带它收到的原始请求报文。TRACE 方法主要用于诊断,用于验证请求是否如愿穿过了请求/响应链。
- OPTIONS方法请求 web 服务器告知其支持的各种功能。可以查询服务器支持哪些方法或者对某些特殊资源支持哪些方法。
- DELETE请求服务器删除请求 URL 指定的资源
从浏览器地址栏输入 url 到显示页面的步骤(以 HTTP 为例)
- 在浏览器地址栏输入 URL
- 浏览器查看缓存,如果请求资源在缓存中并且判断缓存是否过期,跳转到转码步骤
- 如果资源未缓存,发起新请求
- 如果已缓存,检验判断缓存是否过期,缓存未过期直接提供给客户端,否则与服务器进行验证。
- 检验缓存是否过期通常有两个 HTTP 头进行控制
Expires和Cache-Control:- HTTP1.0 提供 Expires,值为一个绝对时间表示缓存过期日期
- HTTP1.1 增加了 Cache-Control: max-age=,值为以秒为单位的最大过期时间
- 浏览器解析 URL获取协议,主机,端口,path
- 浏览器组装一个 HTTP(GET)请求报文
- 浏览器获取主机 ip 地址,过程如下:
- 浏览器缓存
- 本机缓存
- hosts 文件
- 路由器缓存
- ISP DNS 缓存
- DNS 递归查询(可能存在负载均衡导致每次 IP 不一样)
- 打开一个 socket 与目标 IP 地址,端口建立 TCP 链接,三次握手如下:
- 客户端发送一个 TCP 的SYN=1,Seq=X的包到服务器端口
- 服务器发回SYN=1, ACK=X+1, Seq=Y的响应包
- 客户端发送ACK=Y+1, Seq=Z
- TCP 链接建立后发送 HTTP 请求
- 服务器接受请求并解析,将请求转发到服务程序,如虚拟主机使用 HTTP Host 头部判断请求的服务程序
- 服务器检查HTTP 请求头是否包含缓存验证信息如果验证缓存未过期,返回304等对应状态码
- 处理程序读取完整请求并准备 HTTP 响应,可能需要查询数据库等操作
- 服务器将响应报文通过 TCP 连接发送回浏览器
- 浏览器接收 HTTP 响应,然后根据情况选择关闭 TCP 连接或者保留重用,关闭 TCP 连接的四次握手如下:
- 主动方发送Fin=1, Ack=Z, Seq= X报文
- 被动方发送ACK=X+1, Seq=Z报文
- 被动方发送Fin=1, ACK=X, Seq=Y报文
- 主动方发送ACK=Y+1, Seq=X报文
- 浏览器检查响应状态吗:是否为 1XX,3XX, 4XX, 5XX,这些情况处理与 2XX 不同
- 如果资源可缓存,进行缓存协商
- 对响应进行解码(例如 gzip 压缩)
- 根据资源类型决定如何处理(假设资源为 HTML 文档)
- 解析 HTML 文档,构件 DOM 树,下载资源,构造 CSSOM 树,执行 js 脚本,这些操作没有严格的先后顺序,以下分别解释
- 构建 DOM 树:
- Tokenizing:根据 HTML 规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据 HTML 标记关系将对象组成 DOM 树
- 解析过程中遇到图片、样式表、js 文件,启动下载
- 构建CSSOM 树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建 CSSOM 树
- 根据 DOM 树和 CSSOM 树构建渲染树:
- 从 DOM 树的根节点遍历所有可见节点,不可见节点包括:1)
script,meta这样本身不可见的标签。2)被 css 隐藏的节点,如display: none - 对每一个可见节点,找到恰当的 CSSOM 规则并应用
- 发布可视节点的内容和计算样式
- 从 DOM 树的根节点遍历所有可见节点,不可见节点包括:1)
- js 解析如下:
- 浏览器创建 Document 对象并解析 HTML,将解析到的元素和文本节点添加到文档中,此时document.readystate 为 loading
- HTML 解析器遇到没有 async 和 defer 的 script 时,将他们添加到文档中,然后执行行内或外部脚本。这些脚本会同步执行,并且在脚本下载和执行时解析器会暂停。这样就可以用 document.write()把文本插入到输入流中。同步脚本经常简单定义函数和注册事件处理程序,他们可以遍历和操作 script 和他们之前的文档内容
- 当解析器遇到设置了async属性的 script 时,开始下载脚本并继续解析文档。脚本会在它下载完成后尽快执行,但是解析器不会停下来等它下载。异步脚本**禁止使用 document.write()**,它们可以访问自己 script 和之前的文档元素
- 当文档完成解析,document.readState 变成 interactive
- 所有defer脚本会按照在文档出现的顺序执行,延迟脚本能访问完整文档树,禁止使用 document.write()
- 浏览器在 Document 对象上触发 DOMContentLoaded 事件
- 此时文档完全解析完成,浏览器可能还在等待如图片等内容加载,等这些内容完成载入并且所有异步脚本完成载入和执行,document.readState 变为 complete,window 触发 load 事件
- 显示页面(HTML 解析过程中会逐步显示页面)

HTTP request 报文结构是怎样的
rfc2616中进行了定义:
- 首行是Request-Line包括:请求方法,请求 URI,协议版本,CRLF
- 首行之后是若干行请求头,包括general-header,request-header或者entity-header,每个一行以 CRLF 结束
- 请求头和消息实体之间有一个CRLF 分隔
- 根据实际请求需要可能包含一个消息实体
一个请求报文例子如下:
1 | GET /Protocols/rfc2616/rfc2616-sec5.html HTTP/1.1 |
HTTP response 报文结构是怎样的
rfc2616中进行了定义:
- 首行是状态行包括:HTTP 版本,状态码,状态描述,后面跟一个 CRLF
- 首行之后是若干行响应头,包括:通用头部,响应头部,实体头部
- 响应头部和响应实体之间用一个 CRLF 空行分隔
- 最后是一个可能的消息实体
响应报文例子如下:
1 | HTTP/1.1 200 OK |
HTTP 状态码及其含义
参考RFC 2616
- 1XX:信息状态码
- 100 Continue:客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应
- 101 Switching Protocols:服务器理解了客户端切换协议的请求,并将通过 Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应后,服务器将会切换到 Upgrade 消息头中定义的那些协议。
- 2XX:成功状态码
- 200 OK:请求成功,请求所希望的响应头或数据体将随此响应返回
- 201 Created:请求成功并且服务器创建了新的资源
- 202 Accepted:服务器已接受请求,但尚未处理
- 203 Non-Authoritative Information:表示文档被正常的返回,但是由于正在使用的是文档副本所以某些响应头信息可能不正确。(HTTP 1.1新)
- 204 No Content:没有新文档,浏览器应该继续显示原来的文档。
- 205 Reset Content:没有新的内容,但浏览器应该重置它所显示的内容。用来强制浏览器清除表单输入内容(HTTP 1.1新)
- 206 Partial Content:请求成功,返回范围请求的部分资源
- 3XX:重定向
- 300 Multiple Choices:客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location响应头中指明
- 301 Moved Permanently:请求的资源已永久移动到新位置
- 302 Found:临时性重定向
- 303 See Other:类似于301/302,不同之处在于,如果原来的请求是POST,Location头指定的重定向目标文档应该通过GET提取(HTTP 1.1新)
- 304 Not Modified:自从上次请求后,请求的资源未修改过
- 305 Use Proxy:客户请求的文档应该通过Location头所指明的代理服务器提取(HTTP 1.1新)
- 306 (unused):未使用
- 307 Temporary Redirect:和302 (Found)相同。许多浏览器会错误地响应302应答进行重定向,即使原来的请求是POST,即使它实际上只能在POST请求的应答是303时才能重定向。由于这个原因,HTTP 1.1新增了307,以便更加清除地区分几个状态代码:当出现303应答时,浏览器可以跟随重定向的GET和POST请求;如果是307应答,则浏览器只能跟随对GET请求的重定向。(HTTP 1.1新)
- 4XX:客户端错误
400 Bad Request:服务器无法理解请求的格式,客户端不应当尝试再次使用相同的内容发起请求
401 Unauthorized:求未授权
402 Payment Required:
403 Forbidden:禁止访问
404 Not Found:找不到与 URI 相匹配的资源
405 Method Not Allowed:请求方法(GET、POST、HEAD、DELETE、PUT、TRACE等)对指定的资源不适用。(HTTP 1.1新)
406 Not Acceptable:指定的资源已经找到,但它的MIME类型和客户在Accpet头中所指定的不兼容(HTTP 1.1新)
407 Proxy Authentication Required:类似于401,表示客户必须先经过代理服务器的授权。(HTTP 1.1新)
408 Request Timeout:在服务器许可的等待时间内,客户一直没有发出任何请求。客户可以在以后重复同一请求。(HTTP 1.1新)
409 Conflict:通常和PUT请求有关。由于请求和资源的当前状态相冲突,因此请求不能成功。(HTTP 1.1新)
410 Gone:所请求的文档已经不再可用,而且服务器不知道应该重定向到哪一个地址。它和404的不同在于,返回407表示文档永久地离开了指定的位置,而 404表示由于未知的原因文档不可用。(HTTP 1.1新)
411 Length Required:服务器不能处理请求,除非客户发送一个Content-Length头。(HTTP 1.1新)
412 Precondition Failed:请求头中指定的一些前提条件失败(HTTP 1.1新)
413 Request Entity Too Large:目标文档的大小超过服务器当前愿意处理的大小。如果服务器认为自己能够稍后再处理该请求,则应该提供一个Retry-After头(HTTP 1.1新)
414 Request-URI Too Long:URI太长(HTTP 1.1新)
415 Unsupported Media Type:请求所带的附件的格式类型服务器不知道如何处理。(HTTP 1.1新)
416 Requested Range Not Satisfiable:服务器不能满足客户在请求中指定的Range头。(HTTP 1.1新)
417 Expectation Failed:如果服务器得到一个带有100-continue值的Expect请求头信息,这是指客户端正在询问是否可以在后面的请求中发送附件。在这种情况下,服务器也会用该状态(417)告诉浏览器服务器不接收该附件或用100 (SC_CONTINUE)状态告诉客户端可以继续发送附件。(HTTP 1.1新)
- 5XX: 服务器错误
- 500 Internal Server Error:服务器端错误
- 501 Not Implemented:服务器不支持实现请求所需要的功能。例如,客户发出了一个服务器不支持的PUT请求
- 502 Bad Gateway:服务器作为网关或者代理时,为了完成请求访问下一个服务器,但该服务器返回了非法的应答。
- 503 Service Unavailable:服务器由于维护或者负载过重未能应答。例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个 Retry-After头。
- 504 Gateway Timeout:由作为代理或网关的服务器使用,表示不能及时地从远程服务器获得应答。(HTTP 1.1新)
- 505 HTTP Version Not Supported:服务器不支持请求中所指明的HTTP版本。(HTTP 1.1新
什么是渐进增强
渐进增强是指在 web 设计时强调可访问性、语义化 HTML 标签、外部样式表和脚本。保证所有人都能访问页面的基本内容和功能同时为高级浏览器和高带宽用户提供更好的用户体验。核心原则如下:
- 所有浏览器都必须能访问基本内容
- 所有浏览器都必须能使用基本功能
- 所有内容都包含在语义化标签中
- 通过外部 CSS 提供增强的布局
- 通过非侵入式、外部 javascript 提供增强功能
- end-user web browser preferences are respected
CSS 选择器有哪些
* 通用选择器:选择所有元素,不参与计算优先级,兼容性 IE6+- **
#X id 选择器**:选择 id 值为 X 的元素,兼容性:IE6+ - **
.X 类选择器**: 选择 class 包含 X 的元素,兼容性:IE6+ - **
X Y 后代选择器**: 选择满足 X 选择器的后代节点中满足 Y 选择器的元素,兼容性:IE6+ - **
X 元素选择器**: 选择标所有签为 X 的元素,兼容性:IE6+ - **
:link,:visited,:focus,:hover,:active 链接状态**: 选择特定状态的链接元素,顺序 LoVe HAte,兼容性: IE4+ X + Y 直接兄弟选择器:在X 之后第一个兄弟节点中选择满足 Y 选择器的元素,兼容性: IE7+- **
X > Y 子选择器**: 选择 X 的子元素中满足 Y 选择器的元素,兼容性: IE7+ X ~ Y 兄弟: 选择X 之后所有兄弟节点中满足 Y 选择器的元素,兼容性: IE7+- **
[attr]**:选择所有设置了 attr 属性的元素,兼容性 IE7+ - **
[attr=value]**:选择属性值刚好为 value 的元素 - **
[attr~=value]**:选择属性值为空白符分隔,其中一个的值刚好是 value 的元素 - **
[attr|=value]**:选择属性值刚好为 value 或者 value-开头的元素 - **
[attr^=value]**:选择属性值以 value 开头的元素 - **
[attr$=value]**:选择属性值以 value 结尾的元素 - **
[attr*=value]**:选择属性值中包含 value 的元素 - **
[:checked]**:选择单选框,复选框,下拉框中选中状态下的元素,兼容性:IE9+ - **
X:after, X::after**:after 伪元素,选择元素虚拟子元素(元素的最后一个子元素),CSS3 中::表示伪元素。兼容性:after 为 IE8+,::after 为 IE9+ - **
:hover**:鼠标移入状态的元素,兼容性 a 标签 IE4+, 所有元素 IE7+ :not(selector):选择不符合 selector 的元素。不参与计算优先级,兼容性:IE9+- **
::first-letter**:伪元素,选择块元素第一行的第一个字母,兼容性 IE5.5+ - **
::first-line**:伪元素,选择块元素的第一行,兼容性 IE5.5+ - **
:nth-child(an + b)**:伪类,选择前面有 an + b - 1 个兄弟节点的元素,其中 n
>= 0, 兼容性 IE9+ - **
:nth-last-child(an + b)**:伪类,选择后面有 an + b - 1 个兄弟节点的元素
其中 n >= 0,兼容性 IE9+ X:nth-of-type(an+b):伪类,X 为选择器,解析得到元素标签,选择前面有 an + b - 1 个相同标签兄弟节点的元素。兼容性 IE9+X:nth-last-of-type(an+b):伪类,X 为选择器,解析得到元素标签,选择后面有 an+b-1 个相同标签兄弟节点的元素。兼容性 IE9+- **
X:first-child**:伪类,选择满足 X 选择器的元素,且这个元素是其父节点的第一个子元素。兼容性 IE7+ - **
X:last-child**:伪类,选择满足 X 选择器的元素,且这个元素是其父节点的最后一个子元素。兼容性 IE9+ - **
X:only-child**:伪类,选择满足 X 选择器的元素,且这个元素是其父元素的唯一子元素。兼容性 IE9+ X:only-of-type:伪类,选择 X 选择的元素,解析得到元素标签,如果该元素没有相同类型的兄弟节点时选中它。兼容性 IE9+X:first-of-type:伪类,选择 X 选择的元素,解析得到元素标签,如果该元素
是此此类型元素的第一个兄弟。选中它。兼容性 IE9+
css sprite 是什么,有什么优缺点
概念:将多个小图片拼接到一个图片中。通过 background-position 和元素尺寸调节需要显示的背景图案。
优点:
- 减少 HTTP 请求数,极大地提高页面加载速度
- 增加图片信息重复度,提高压缩比,减少图片大小
- 更换风格方便,只需在一张或几张图片上修改颜色或样式即可实现
缺点:
- 图片合并麻烦
- 维护麻烦,修改一个图片可能需要重新布局整个图片,样式
display: none;与visibility: hidden;的区别
联系:它们都能让元素不可见
区别:
- display:none;会让元素完全从渲染树中消失,渲染的时候不占据任何空间;visibility: hidden;不会让元素从渲染树消失,渲染时元素继续占据空间,只是内容不可见。
- display: none;是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示;visibility: hidden;是继承属性,子孙节点由于继承了 hidden 而消失,通过设置 visibility: visible,可以让子孙节点显示。
- 修改常规流中元素的 display 通常会造成文档重排。修改 visibility 属性只会造成本元素的重绘。
- 读屏器不会读取 display: none;元素内容;会读取 visibility: hidden;元素内容。
css hack 原理及常用 hack
原理:利用不同浏览器对 CSS 的支持和解析结果不一样编写针对特定浏览器样式。常见的 hack 有 1)属性 hack。2)选择器 hack。3)IE 条件注释
- IE 条件注释:适用于[IE5, IE9]常见格式如下
1 | <!--[if IE 6]> |
- 选择器 hack:不同浏览器对选择器的支持不一样
1 | /***** Selector Hacks ******/ |
- 属性 hack:不同浏览器解析 bug 或方法
1 | /* IE6 */ |
specified value,computed value,used value 计算方法
specified value: 计算方法如下:
- 如果样式表设置了一个值,使用这个值
- 如果没有设值,且这个属性是继承属性,从父元素继承
- 如果没有设值,并且不是继承属性,则使用 css 规范指定的初始值
computed value: 以 specified value 根据规范定义的行为进行计算,通常将相对值计算为绝对值,例如 em 根据 font-size 进行计算。一些使用百分数并且需要布局来决定最终值的属性,如 width,margin。百分数就直接作为 computed value。line-height 的无单位值也直接作为 computed value。这些值将在计算 used value 时得到绝对值。computed value 的主要作用是用于继承
used value:属性计算后的最终值,对于大多数属性可以通过 window.getComputedStyle 获得,尺寸值单位为像素。以下属性依赖于布局,
- background-position
- bottom, left, right, top
- height, width
- margin-bottom, margin-left, margin-right, margin-top
- min-height, min-width
- padding-bottom, padding-left, padding-right, padding-top
- text-indent
link与@import的区别
link是 HTML 方式,@import是 CSS 方式link最大限度支持并行下载,@import过多嵌套导致串行下载,出现FOUClink可以通过rel="alternate stylesheet"指定候选样式- 浏览器对
link支持早于@import,可以使用@import对老浏览器隐藏样式 @import必须在样式规则之前,可以在 css 文件中引用其他文件- 总体来说:**link 优于@import**
display: block;和display: inline;的区别
block元素特点:
- 处于常规流中时,如果
width没有设置,会自动填充满父容器 - 可以应用
margin/padding - 在没有设置高度的情况下会扩展高度以包含常规流中的子元素
- 处于常规流中时布局时在前后元素位置之间(独占一个水平空间)
- 忽略
vertical-align
inline元素特点
- 水平方向上根据
direction依次布局 - 不会在元素前后进行换行
- 受
white-space控制 margin/padding在竖直方向上无效,水平方向上有效width/height属性对非替换行内元素无效,宽度由元素内容决定- 非替换行内元素的行框高由
line-height确定,替换行内元素的行框高由height,margin,padding,border决定 - 浮动或绝对定位时会转换为
block vertical-align属性生效
PNG,GIF,JPG 的区别及如何选
参考资料: 选择正确的图片格式
GIF:
- 8 位像素,256 色
- 无损压缩
- 支持简单动画
- 支持 boolean 透明
- 适合简单动画
JPEG:
- 颜色限于 256
- 有损压缩
- 可控制压缩质量
- 不支持透明
- 适合照片
PNG:
- 有 PNG8 和 truecolor PNG
- PNG8 类似 GIF 颜色上限为 256,文件小,支持 alpha 透明度,无动画
- 适合图标、背景、按钮
CSS 有哪些继承属性
- 关于文字排版的属性如:
- line-height
- color
- visibility
- cursor
IE6 浏览器有哪些常见的 bug,缺陷或者与标准不一致的地方,如何解决
- IE6 不支持 min-height,解决办法使用 css hack:
1 | .target { |
ol内li的序号全为 1,不递增。解决方法:为 li 设置样式display: list-item;未定位父元素
overflow: auto;,包含position: relative;子元素,子元素高于父元素时会溢出。解决办法:1)子元素去掉position: relative;; 2)不能为子元素去掉定位时,父元素position: relative;
1 | <style type="text/css"> |
- IE6 只支持
a标签的:hover伪类,解决方法:使用 js 为元素监听 mouseenter,mouseleave 事件,添加类实现效果:
1 | <style type="text/css"> |
- IE5-8 不支持
opacity,解决办法:
1 | .opacity { |
- IE6 在设置
height小于font-size时高度值为font-size,解决办法:font-size: 0; - IE6 不支持 PNG 透明背景,解决办法: IE6 下使用 gif 图片
- IE6-7 不支持
display: inline-block解决办法:设置 inline 并触发 hasLayout
1 | display: inline-block; |
- IE6 下浮动元素在浮动方向上与父元素边界接触元素的外边距会加倍。解决办法:
1)使用 padding 控制间距。
2)浮动元素display: inline;这样解决问题且无任何副作用:css 标准规定浮动元素 display:inline 会自动调整为 block - 通过为块级元素设置宽度和左右 margin 为 auto 时,IE6 不能实现水平居中,解决方法:为父元素设置
text-align: center;
容器包含若干浮动元素时如何清理(包含)浮动
- 容器元素闭合标签前添加额外元素并设置
clear: both - 父元素触发块级格式化上下文(见块级可视化上下文部分)
- 设置容器元素伪元素进行清理推荐的清理浮动方法
1 | /** |
什么是 FOUC?如何避免
Flash Of Unstyled Content:用户定义样式表加载之前浏览器使用默认样式显示文档,用户样式加载渲染之后再从新显示文档,造成页面闪烁。解决方法:把样式表放到文档的head
如何创建块级格式化上下文(block formatting context),BFC 有什么用
创建规则:
- 根元素
- 浮动元素(
float不是none) - 绝对定位元素(
position取值为absolute或fixed) display取值为inline-block,table-cell,table-caption,flex,inline-flex之一的元素overflow不是visible的元素
作用:
- 可以包含浮动元素
- 不被浮动元素覆盖
- 阻止父子元素的 margin 折叠
display,float,position 的关系
- 如果
display为 none,那么 position 和 float 都不起作用,这种情况下元素不产生框 - 否则,如果 position 值为 absolute 或者 fixed,框就是绝对定位的,float 的计算值为 none,display 根据下面的表格进行调整。
- 否则,如果 float 不是 none,框是浮动的,display 根据下表进行调整
- 否则,如果元素是根元素,display 根据下表进行调整
- 其他情况下 display 的值为指定值
总结起来:绝对定位、浮动、根元素都需要调整display

五外边距折叠(collapsing margins)
毗邻的两个或多个margin会合并成一个 margin,叫做外边距折叠。规则如下:
- 两个或多个毗邻的普通流中的块元素垂直方向上的 margin 会折叠
- 浮动元素/inline-block 元素/绝对定位元素的 margin 不会和垂直方向上的其他元素的 margin 折叠
- 创建了块级格式化上下文的元素,不会和它的子元素发生 margin 折叠
- 元素自身的 margin-bottom 和 margin-top 相邻时也会折叠
如何确定一个元素的包含块(containing block)
根元素的包含块叫做初始包含块,在连续媒体中他的尺寸与 viewport 相同并且 anchored at the canvas origin;对于 paged media,它的尺寸等于 page area。初始包含块的 direction 属性与根元素相同。
position为relative或者static的元素,它的包含块由最近的块级(display为block,list-item,table)祖先元素的内容框组成如果元素
position为fixed。对于连续媒体,它的包含块为 viewport;对于 paged media,包含块为 page area如果元素
position为absolute,它的包含块由祖先元素中最近一个position为relative,absolute或者fixed的元素产生,规则如下:- 如果祖先元素为行内元素,the containing block is the bounding box around the padding boxes of the first and the last inline boxes generated for that element.
- 其他情况下包含块由祖先节点的padding edge组成
如果找不到定位的祖先元素,包含块为初始包含块
stacking context,布局规则
z 轴上的默认层叠顺序如下(从下到上):
- 根元素的边界和背景
- 常规流中的元素按照 html 中顺序
- 浮动块
- positioned 元素按照 html 中出现顺序
如何创建 stacking context:
- 根元素
- z-index 不为 auto 的定位元素
- a flex item with a z-index value other than ‘auto’
- opacity 小于 1 的元素
- 在移动端 webkit 和 chrome22+,z-index 为 auto,position: fixed 也将创建新的 stacking context
如何水平居中一个元素
- 如果需要居中的元素为常规流中 inline 元素,为父元素设置
text-align: center;即可实现 - 如果需要居中的元素为常规流中 block 元素,1)为元素设置宽度,2)设置左右 margin 为 auto。3)IE6 下需在父元素上设置
text-align: center;,再给子元素恢复需要的值
1 | <body> |
- 如果需要居中的元素为浮动元素,1)为元素设置宽度,2)
position: relative;,3)浮动方向偏移量(left 或者 right)设置为 50%,4)浮动方向上的 margin 设置为元素宽度一半乘以-1
1 | <body> |
- 如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)偏移量设置为 50%,3)偏移方向外边距设置为元素宽度一半乘以-1
1 | <body> |
- 如果需要居中的元素为绝对定位元素,1)为元素设置宽度,2)设置左右偏移量都为 0,3)设置左右外边距都为 auto
1 | <body> |
如何竖直居中一个元素
参考资料:6 Methods For Vertical Centering With CSS。 盘点 8 种 CSS 实现垂直居中
- 需要居中元素为单行文本,为包含文本的元素设置大于
font-size的line-height:
1 | <p class="text">center text</p> |
DOM 元素 e 的 e.getAttribute(propName)和 e.propName 有什么区别和联系
- e.getAttribute(),是标准 DOM 操作文档元素属性的方法,具有通用性可在任意文档上使用,返回元素在源文件中设置的属性
- e.propName 通常是在 HTML 文档中访问特定元素的特性,浏览器解析元素后生成对应对象(如 a 标签生成 HTMLAnchorElement),这些对象的特性会根据特定规则结合属性设置得到,对于没有对应特性的属性,只能使用 getAttribute 进行访问
- e.getAttribute()返回值是源文件中设置的值,类型是字符串或者 null(有的实现返回””)
- e.propName 返回值可能是字符串、布尔值、对象、undefined 等
- 大部分 attribute 与 property 是一一对应关系,修改其中一个会影响另一个,如 id,title 等属性
- 一些布尔属性
<input hidden/>的检测设置需要 hasAttribute 和 removeAttribute 来完成,或者设置对应 property - 像
<a href="../index.html">link</a>中 href 属性,转换成 property 的时候需要通过转换得到完整 URL - 一些 attribute 和 property 不是一一对应如:form 控件中
<input value="hello"/>对应的是 defaultValue,修改或设置 value property 修改的是控件当前值,setAttribute 修改 value 属性不会改变 value property
XMLHttpRequest 通用属性和方法
readyState:表示请求状态的整数,取值:
- UNSENT(0):对象已创建
- OPENED(1):open()成功调用,在这个状态下,可以为 xhr 设置请求头,或者使用 send()发送请求
- HEADERS_RECEIVED(2):所有重定向已经自动完成访问,并且最终响应的 HTTP 头已经收到
- LOADING(3):响应体正在接收
- DONE(4):数据传输完成或者传输产生错误
onreadystatechange:readyState 改变时调用的函数status:服务器返回的 HTTP 状态码(如,200, 404)statusText:服务器返回的 HTTP 状态信息(如,OK,No Content)responseText:作为字符串形式的来自服务器的完整响应responseXML: Document 对象,表示服务器的响应解析成的 XML 文档abort():取消异步 HTTP 请求getAllResponseHeaders(): 返回一个字符串,包含响应中服务器发送的全部 HTTP 报头。每个报头都是一个用冒号分隔开的名/值对,并且使用一个回车/换行来分隔报头行getResponseHeader(headerName):返回 headName 对应的报头值open(method, url, asynchronous [, user, password]):初始化准备发送到服务器上的请求。method 是 HTTP 方法,不区分大小写;url 是请求发送的相对或绝对 URL;asynchronous 表示请求是否异步;user 和 password 提供身份验证setRequestHeader(name, value):设置 HTTP 报头send(body):对服务器请求进行初始化。参数 body 包含请求的主体部分,对于 POST 请求为键值对字符串;对于 GET 请求,为 null
offsetWidth/offsetHeight,clientWidth/clientHeight 与 scrollWidth/scrollHeight 的区别
- offsetWidth/offsetHeight 返回值包含content + padding + border,效果与 e.getBoundingClientRect()相同
- clientWidth/clientHeight 返回值只包含content + padding,如果有滚动条,也不包含滚动条
- scrollWidth/scrollHeight 返回值包含content + padding + 溢出内容的尺寸
Measuring Element Dimension and Location with CSSOM in Windows Internet Explorer 9

focus/blur 与 focusin/focusout 的区别与联系
- focus/blur 不冒泡,focusin/focusout 冒泡
- focus/blur 兼容性好,focusin/focusout 在除 FireFox 外的浏览器下都保持良好兼容性,如需使用事件托管,可考虑在 FireFox 下使用事件捕获 elem.addEventListener(‘focus’, handler, true)
- 可获得焦点的元素:
- window
- 链接被点击或键盘操作
- 表单空间被点击或键盘操作
- 设置
tabindex属性的元素被点击或键盘操作
mouseover/mouseout 与 mouseenter/mouseleave 的区别与联系
- mouseover/mouseout 是标准事件,所有浏览器都支持;mouseenter/mouseleave 是 IE5.5 引入的特有事件后来被 DOM3 标准采纳,现代标准浏览器也支持
- mouseover/mouseout 是冒泡事件;mouseenter/mouseleave不冒泡。需要为多个元素监听鼠标移入/出事件时,推荐 mouseover/mouseout 托管,提高性能
- 标准事件模型中 event.target 表示正在发生移入/移出的元素,event.relatedTarget表示对应移入/移出的目标元素;在老 IE 中 event.srcElement 表示正在发生移入/移出的元素,event.toElement表示移出的目标元素,event.fromElement表示移入时的来源元素
例子:鼠标从 div#target 元素移出时进行处理,判断逻辑如下:
1 | <div id="target"><span>test</span></div> |
javascript 跨域通信
同源:两个文档同源需满足
- 协议相同
- 域名相同
- 端口相同
跨域通信:js 进行 DOM 操作、通信时如果目标与当前窗口不满足同源条件,浏览器为了安全会阻止跨域操作。跨域通信通常有以下方法
- 如果是 log 之类的简单单项通信,新建
<img>,<script>,<link>,<iframe>元素,通过 src,href 属性设置为目标 url。实现跨域请求 - 如果请求json 数据,使用
<script>进行 jsonp 请求 - 现代浏览器中多窗口通信使用 HTML5 规范的 targetWindow.postMessage(data, origin);其中 data 是需要发送的对象,origin 是目标窗口的 origin。window.addEventListener(‘message’, handler, false);handler 的 event.data 是 postMessage 发送来的数据,event.origin 是发送窗口的 origin,event.source 是发送消息的窗口引用
- 内部服务器代理请求跨域 url,然后返回数据
- 跨域请求数据,现代浏览器可使用 HTML5 规范的 CORS 功能,只要目标服务器返回 HTTP 头部**
Access-Control-Allow-Origin: ***即可像普通 ajax 一样访问跨域资源
javascript 有哪几种数据类型
六种基本数据类型
- undefined
- null
- string
- boolean
- number
- symbol(ES6)
一种引用类型
- Object
什么闭包,闭包有什么用
闭包是在某个作用域内定义的函数,它可以访问这个作用域内的所有变量。闭包作用域链通常包括三个部分:
- 函数本身作用域。
- 闭包定义时的作用域。
- 全局作用域。
闭包常见用途:
- 创建特权方法用于访问控制
- 事件处理程序及回调
javascript 有哪几种方法定义函数
重要参考资料:MDN:Functions_and_function_scope
应用程序存储和离线 web 应用
HTML5 新增应用程序缓存,允许 web 应用将应用程序自身保存到用户浏览器中,用户离线状态也能访问。
- 为 html 元素设置 manifest 属性:
<html manifest="myapp.appcache" >,其中后缀名只是一个约定,真正识别方式是通过text/cache-manifest作为 MIME 类型。所以需要配置服务器保证设置正确 - manifest 文件首行为
CACHE MANIFEST,其余就是要缓存的 URL 列表,每个一行,相对路径都相对于 manifest 文件的 url。注释以#开头 - url 分为三种类型:
CACHE:为默认类型,列举的所有的文件都会被缓存。NETWORK:开头的区域列举的文件,总是从线上获取,表示资源从不缓存。
头信息支持通配符”*”,表示任何未明确列举的资源,都将通过网络加载。FALLBACK:开头的区域中的内容,提供了获取不到缓存资源时的备选资源路径。
该区域中的内容,每一行包含两个URL(第一个URL是一个前缀,任何匹配的资源都不被缓存,第二个URL表示需要被缓存的资源,如果从网络中载入第一个 URL 失败的话,就会用第二个 URL 指定的缓存资源来替代)
以下是一个文件例子:
1 | CACHE MANIFEST |
sessionStorage,localStorage,cookie 区别
- 都会在浏览器端保存,有大小限制,同源限制
- cookie 会在请求时发送到服务器,作为会话标识,服务器可修改 cookie;web storage 不会发送到服务器
- cookie 有 path 概念,子路径可以访问父路径 cookie,父路径不能访问子路径 cookie
- 有效期:cookie 在设置的有效期内有效,默认为浏览器关闭;sessionStorage 在窗口关闭前有效,localStorage 长期有效,直到用户删除
- 共享:sessionStorage 不能共享,localStorage 在同源文档之间共享,cookie 在同源且符合 path 规则的文档之间共享
- localStorage 的修改会促发其他文档窗口的 update 事件
- cookie 有 secure 属性要求 HTTPS 传输
- 浏览器不能保存超过 300 个 cookie,单个服务器不能超过 20 个,每个 cookie 不能超过 4k。web storage 大小支持能达到 5M
客户端存储 localStorage 和 sessionStorage
- localStorage 有效期为永久,sessionStorage 有效期为顶层窗口关闭前
- 同源文档可以读取并修改 localStorage 数据,sessionStorage 只允许同一个窗口下的文档访问,如通过 iframe 引入的同源文档。
- Storage 对象通常被当做普通 javascript 对象使用:通过设置属性来存取字符串值,也可以通过setItem(key, value)设置,getItem(key)读取,removeItem(key)删除,clear()删除所有数据,length 表示已存储的数据项数目,key(index)返回对应索引的 key
1 | localStorage.setItem('x', 1); // storge x->1 |
cookie 及其操作
- cookie 是 web 浏览器存储的少量数据,最早设计为服务器端使用,作为 HTTP 协议的扩展实现。cookie 数据会自动在浏览器和服务器之间传输。
- 通过读写 cookie 检测是否支持
- cookie 属性有名,值,max-age,path, domain,secure;
- cookie 默认有效期为浏览器会话,一旦用户关闭浏览器,数据就丢失,通过设置max-age=seconds属性告诉浏览器 cookie 有效期
- cookie 作用域通过文档源和文档路径来确定,通过path和domain进行配置,web 页面同目录或子目录文档都可访问
- 通过 cookie 保存数据的方法为:为 document.cookie 设置一个符合目标的字符串如下
- 读取 document.cookie 获得’; ‘分隔的字符串,key=value,解析得到结果
1 | document.cookie = 'name=qiu; max-age=9999; path=/; domain=domain; secure'; |
cookieUtil.js:自己写的 cookie 操作工具
javascript 有哪些方法定义对象
- 对象字面量:
var obj = {}; - 构造函数:
var obj = new Object(); - Object.create():
var obj = Object.create(Object.prototype);
===运算符判断相等的流程是怎样的
- 如果两个值不是相同类型,它们不相等
- 如果两个值都是 null 或者都是 undefined,它们相等
- 如果两个值都是布尔类型 true 或者都是 false,它们相等
- 如果其中有一个是NaN,它们不相等
- 如果都是数值型并且数值相等,他们相等, -0 等于 0
- 如果他们都是字符串并且在相同位置包含相同的 16 位值,他它们相等;如果在长度或者内容上不等,它们不相等;两个字符串显示结果相同但是编码不同==和===都认为他们不相等
- 如果他们指向相同对象、数组、函数,它们相等;如果指向不同对象,他们不相等
==运算符判断相等的流程是怎样的
- 如果两个值类型相同,按照===比较方法进行比较
- 如果类型不同,使用如下规则进行比较
- 如果其中一个值是 null,另一个是 undefined,它们相等
- 如果一个值是数字另一个是字符串,将字符串转换为数字进行比较
- 如果有布尔类型,将true 转换为 1,false 转换为 0,然后用==规则继续比较
- 如果一个值是对象,另一个是数字或字符串,将对象转换为原始值然后用==规则继续比较
- 其他所有情况都认为不相等
对象到字符串的转换步骤
- 如果对象有 toString()方法,javascript 调用它。如果返回一个原始值(primitive value 如:string number boolean),将这个值转换为字符串作为结果
- 如果对象没有 toString()方法或者返回值不是原始值,javascript 寻找对象的 valueOf()方法,如果存在就调用它,返回结果是原始值则转为字符串作为结果
- 否则,javascript 不能从 toString()或者 valueOf()获得一个原始值,此时 throws a TypeError
对象到数字的转换步骤
- 如果对象有valueOf()方法并且返回元素值,javascript将返回值转换为数字作为结果
- 否则,如果对象有toString()并且返回原始值,javascript将返回结果转换为数字作为结果
- 否则,throws a TypeError
<,>,<=,>=的比较规则
所有比较运算符都支持任意类型,但是比较只支持数字和字符串,所以需要执行必要的转换然后进行比较,转换规则如下:
- 如果操作数是对象,转换为原始值:如果 valueOf 方法返回原始值,则使用这个值,否则使用 toString 方法的结果,如果转换失败则报错
- 经过必要的对象到原始值的转换后,如果两个操作数都是字符串,按照字母顺序进行比较(他们的 16 位 unicode 值的大小)
- 否则,如果有一个操作数不是字符串,将两个操作数转换为数字进行比较
+运算符工作流程
- 如果有操作数是对象,转换为原始值
- 此时如果有一个操作数是字符串,其他的操作数都转换为字符串并执行连接
- 否则:所有操作数都转换为数字并执行加法
函数内部 arguments 变量有哪些特性,有哪些属性,如何将它转换为数组
- arguments 所有函数中都包含的一个局部变量,是一个类数组对象,对应函数调用时的实参。如果函数定义同名参数会在调用时覆盖默认对象
- arguments[index]分别对应函数调用时的实参,并且通过 arguments 修改实参时会同时修改实参
- arguments.length 为实参的个数(Function.length 表示形参长度)
- arguments.callee 为当前正在执行的函数本身,使用这个属性进行递归调用时需注意 this 的变化
- arguments.caller 为调用当前函数的函数(已被遗弃)
- 转换为数组:
var args = Array.prototype.slice.call(arguments, 0);
介绍chrome 浏览器的几个版本
1)Chrome 浏览器提供 4 种发布版本,即稳定版(Stable)、测试版(Beta)、开发者版(Dev)和金丝雀版(Canary)。
虽然 Chrome 这几个版本名称各不相同,但都沿用了相同的版本号,只是更新早晚的区别。就好比 iOS 等系统,Beta 版可以率先更新到 iOS 12 并进行测试,不断改进稳定后,正式版才升级到 12 版本。
Chrome 也是如此,更新最快的 Canary 会领先正式版 1-2 个版本。
1. Canary(金丝雀) 版
只限用于测试,Canary 是 Chrome 的未来版本,是功能、代码最先进的Chrome 版本,一方面软件本身没有足够时间测试,另一方面网页也不一定支持这些全新的功能,因此极不稳定。好在,谷歌将其设定为可独立安装、与其他版本的 Chrome 程序共存,因此适合进阶用户安装备用,尝鲜最新功能。这种不稳定性使得 Canary 版目前并不适合日常使用。
Chrome Canary 是更新速度最快的 Chrome 版本,几乎每天更新。它相当于支持自动更新、并添加了谷歌自家服务与商业闭源插件(Flash 等)的 Chromium,更加强大好用。
2. 开发者版(Dev)
Chrome Dev 最初是以 Chromium 为基础、更新最快的 Chrome,后来则被 Canary 取代。Dev 版每周更新一次,虽然仍不太稳定,但已经可以勉强满足日常使用,适合 Web 开发者用来测试新功能和网页。
让 IT 人员使用开发者版,开发者可以通过开发者版测试自己公司的应用,确保这些应用能与Chrome 最新的 API 更改及功能更改兼容。注意:开发者版并非百分之百稳定,但开发者可以提前 9 至 12 周体验即将添加到 Chrome 稳定版的功能。
3. 测试版(Beta)
Chrome Beta 以 Dev 为基础,每月更新一次。它是正式发布前的最后测试版本,所有功能都已在前面几个版本中得到测试并改进,因此已经十分稳定,普通用户也可以用来日常使用
让 5% 的用户使用测试版,测试版用户可以提前 4-6 周体验即将在 Chrome 稳定版中推出的功能。测试版用户可以发现特定版本可能存在的问题,让您可以先解决问题,然后再向所有用户推出该版本。
4. 稳定版(Stable)
最后的 Chrome Stable 就是我们熟知的正式版,它以 Beta 为基础,几个月更新一次。由于所有的功能都已经过数个月反复测试,是稳定性最高的 Chrome 版本。
让大多数用户使用稳定版,稳定版是已进行充分测试的版本,稳定版每 2-3 周会进行一次小幅更新,并且每 6 周会进行一次重大更新。
所以要定期下载开发者版,体验Chrome 最新的 API和新功能 ,发现自己的应用跟新API和新功能的是否有兼容问题,找到开发亮点。
2)对于Chrome的历史版本测试
可以使用Docker Selenium 做分布式自动化测试,部署多个重点关注的版本,进行自动化测试,对比差异。
说一下 Http 缓存策略,有什么区别,分别解决了什么问题
1)浏览器缓存策略
浏览器每次发起请求时,先在本地缓存中查找结果以及缓存标识,根据缓存标识来判断是否使用本地缓存。如果缓存有效,则使
用本地缓存;否则,则向服务器发起请求并携带缓存标识。根据是否需向服务器发起HTTP请求,将缓存过程划分为两个部分:
强制缓存和协商缓存,强缓优先于协商缓存。
强缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
协商缓存,让客户端与服务器之间能实现缓存文件是否更新的验证、提升缓存的复用率,将缓存信息中的Etag和Last-Modified
通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
HTTP缓存都是从第二次请求开始的:
第一次请求资源时,服务器返回资源,并在response header中回传资源的缓存策略;
第二次请求时,浏览器判断这些请求参数,击中强缓存就直接200,否则就把请求参数加到request header头中传给服务器,看是否击中协商缓存,击中则返回304,否则服务器会返回新的资源。这是缓存运作的一个整体流程图:

2)强缓存
- 强缓存命中则直接读取浏览器本地的资源,在network中显示的是from memory或者from disk
- 控制强制缓存的字段有:Cache-Control(http1.1)和Expires(http1.0)
- Cache-control是一个相对时间,用以表达自上次请求正确的资源之后的多少秒的时间段内缓存有效。
- Expires是一个绝对时间。用以表达在这个时间点之前发起请求可以直接从浏览器中读取数据,而无需发起请求
- Cache-Control的优先级比Expires的优先级高。前者的出现是为了解决Expires在浏览器时间被手动更改导致缓存判断错误的问题。
- 如果同时存在则使用Cache-control。
3)强缓存(expires)
该字段是服务器响应消息头字段,告诉浏览器在过期时间之前可以直接从浏览器缓存中存取数据。
Expires 是 HTTP 1.0 的字段,表示缓存到期时间,是一个绝对的时间 (当前时间+缓存时间)。在响应消息头中,设置这个字段之后,就可以告诉浏览器,在未过期之前不需要再次请求。
由于是绝对时间,用户可能会将客户端本地的时间进行修改,而导致浏览器判断缓存失效,重新请求该资源。此外,即使不考虑修改,时差或者误差等因素也可能造成客户端与服务端的时间不一致,致使缓存失效。
优势特点
- HTTP 1.0 产物,可以在HTTP 1.0和1.1中使用,简单易用。
- 以时刻标识失效时间。
劣势问题
- 时间是由服务器发送的(UTC),如果服务器时间和客户端时间存在不一致,可能会出现问题。
- 存在版本问题,到期之前的修改客户端是不可知的。
4)强缓存(cache-control)
已知Expires的缺点之后,在HTTP/1.1中,增加了一个字段Cache-control,该字段表示资源缓存的最大有效时间,在该时间内,客户端不需要向服务器发送请求。
这两者的区别就是前者是绝对时间,而后者是相对时间。下面列举一些 Cache-control 字段常用的值:(完整的列表可以查看MDN)
max-age:即最大有效时间。must-revalidate:如果超过了 max-age 的时间,浏览器必须向服务器发送请求,验证资源是否还有效。no-cache:不使用强缓存,需要与服务器验证缓存是否新鲜。no-store: 真正意义上的“不要缓存”。所有内容都不走缓存,包括强制和对比。public:所有的内容都可以被缓存 (包括客户端和代理服务器, 如 CDN)private:所有的内容只有客户端才可以缓存,代理服务器不能缓存。默认值。
Cache-control 的优先级高于 Expires,为了兼容 HTTP/1.0 和 HTTP/1.1,实际项目中两个字段都可以设置。
该字段可以在请求头或者响应头设置,可组合使用多种指令:
- 可缓存性:
- public:浏览器和缓存服务器都可以缓存页面信息
- private:default,代理服务器不可缓存,只能被单个用户缓存
- no-cache:浏览器器和服务器都不应该缓存页面信息,但仍可缓存,只是在缓存前需要向服务器确认资源是否被更改。可配合private,过期时间设置为过去时间。
- only-if-cache:客户端只接受已缓存的响应
- 到期:
- max-age=:缓存存储的最大周期,超过这个周期被认为过期。
- s-maxage=:设置共享缓存,比如can。会覆盖max-age和expires。
- max-stale[=]:客户端愿意接收一个已经过期的资源
- min-fresh=:客户端希望在指定的时间内获取最新的响应
- stale-while-revalidate=:客户端愿意接收陈旧的响应,并且在后台一部检查新的响应。时间代表客户端愿意接收陈旧响应的时间长度。
- stale-if-error=:如新的检测失败,客户端则愿意接收陈旧的响应,时间代表等待时间。
- 重新验证和重新加载
- must-revalidate:如页面过期,则去服务器进行获取。
- proxy-revalidate:用于共享缓存。
- immutable:响应正文不随时间改变。
- 其他
- no-store:绝对禁止缓存
- no-transform:不得对资源进行转换和转变。例如,不得对图像格式进行转换。
- 可缓存性:
优势特点
- HTTP 1.1 产物,以时间间隔标识失效时间,解决了Expires服务器和客户端相对时间的问题。
- 比Expires多了很多选项设置。
劣势问题
- 存在版本问题,到期之前的修改客户端是不可知的。
5)协商缓存
- 协商缓存的状态码由服务器决策返回200或者304
- 当浏览器的强缓存失效的时候或者请求头中设置了不走强缓存,并且在请求头中设置了If-Modified-Since 或者 If-None-Match 的时候,会将这两个属性值到服务端去验证是否命中协商缓存,如果命中了协商缓存,会返回 304 状态,加载浏览器缓存,并且响应头会设置 Last-Modified 或者 ETag 属性。
- 对比缓存在请求数上和没有缓存是一致的,但如果是 304 的话,返回的仅仅是一个状态码而已,并没有实际的文件内容,因此 在响应体体积上的节省是它的优化点。
- 协商缓存有 2 组字段(不是两个),控制协商缓存的字段有:Last-Modified/If-Modified-since(http1.0)和Etag/If-None-match(http1.1)
- Last-Modified/If-Modified-since表示的是服务器的资源最后一次修改的时间;Etag/If-None-match表示的是服务器资源的唯一标
识,只要资源变化,Etag就会重新生成。 - Etag/If-None-match的优先级比Last-Modified/If-Modified-since高。
协商缓存(Last-Modified/If-Modified-since)
服务器通过
Last-Modified字段告知客户端,资源最后一次被修改的时间,例如Last-Modified: Mon, 10 Nov 2018 09:10:11 GMT浏览器将这个值和内容一起记录在缓存数据库中。
下一次请求相同资源时时,浏览器从自己的缓存中找出“不确定是否过期的”缓存。因此在请求头中将上次的
Last-Modified的值写入到请求头的If-Modified-Since字段服务器会将
If-Modified-Since的值与Last-Modified字段进行对比。如果相等,则表示未修改,响应 304;反之,则表示修改了,响应 200 状态码,并返回数据。优势特点
- 不存在版本问题,每次请求都会去服务器进行校验。服务器对比最后修改时间如果相同则返回304,不同返回200以及资源内容。
劣势问题
- 只要资源修改,无论内容是否发生实质性的变化,都会将该资源返回客户端。例如周期性重写,这种情况下该资源包含的数据实际上一样的。
- 以时刻作为标识,无法识别一秒内进行多次修改的情况。 如果资源更新的速度是秒以下单位,那么该缓存是不能被使用的,因为它的时间单位最低是秒。
- 某些服务器不能精确的得到文件的最后修改时间。
- 如果文件是通过服务器动态生成的,那么该方法的更新时间永远是生成的时间,尽管文件可能没有变化,所以起不到缓存的作用。
协商缓存(Etag/If-None-match)
为了解决上述问题,出现了一组新的字段
Etag和If-None-MatchEtag存储的是文件的特殊标识(一般都是 hash 生成的),服务器存储着文件的Etag字段。之后的流程和Last-Modified一致,只是Last-Modified字段和它所表示的更新时间改变成了Etag字段和它所表示的文件 hash,把If-Modified-Since变成了If-None-Match。服务器同样进行比较,命中返回 304, 不命中返回新资源和 200。浏览器在发起请求时,服务器返回在Response header中返回请求资源的唯一标识。在下一次请求时,会将上一次返回的Etag值赋值给If-No-Matched并添加在Request Header中。服务器将浏览器传来的if-no-matched跟自己的本地的资源的ETag做对比,如果匹配,则返回304通知浏览器读取本地缓存,否则返回200和更新后的资源。
Etag 的优先级高于 Last-Modified。
优势特点
- 可以更加精确的判断资源是否被修改,可以识别一秒内多次修改的情况。
- 不存在版本问题,每次请求都回去服务器进行校验。
劣势问题
- 计算ETag值需要性能损耗。
- 分布式服务器存储的情况下,计算ETag的算法如果不一样,会导致浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时现ETag不匹配的情况。
介绍防抖节流原理、区别以及应用,并用JavaScript进行实现
1)防抖
原理:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。
适用场景:
- 按钮提交场景:防止多次提交按钮,只执行最后提交的一次
- 搜索框联想场景:防止联想发送请求,只发送最后一次输入
简易版实现
1 | /** |
- 立即执行版实现
有时希望立刻执行函数,然后等到停止触发 n 秒后,才可以重新触发执行。
1 | // 有时希望立刻执行函数,然后等到停止触发 n 秒后,才可以重新触发执行。 |
- 返回值版实现
func函数可能会有返回值,所以需要返回函数结果,但是当 immediate 为 false 的时候,因为使用了 setTimeout ,我们将 func.apply(context, args) 的返回值赋给变量,最后再 return 的时候,值将会一直是 undefined,所以只在 immediate 为 true 的时候返回函数的执行结果。
1 | function debounce(func, wait, immediate) { |
2)节流
原理:规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
适用场景
- 拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动
- 缩放场景:监控浏览器resize
简易版实现
1 | /** |
- 使用时间戳实现
使用时间戳,当触发事件的时候,我们取出当前的时间戳,然后减去之前的时间戳(最一开始值设为 0 ),如果大于设置的时间周期,就执行函数,然后更新时间戳为当前的时间戳,如果小于,就不执行。
1 | function throttle(func, wait) { |
- 使用定时器实现
当触发事件的时候,我们设置一个定时器,再触发事件的时候,如果定时器存在,就不执行,直到定时器执行,然后执行函数,清空定时器,这样就可以设置下个定时器。
1 | function throttle(func, wait) { |
前端安全、中间人攻击
1)XSS:跨站脚本攻击
就是攻击者想尽一切办法将可以执行的代码注入到网页中。
存储型(server端)
场景:见于带有用户保存数据的网站功能,如论坛发帖、商品评论、用户私信等。
攻击步骤:
- 攻击者将恶意代码提交到目标网站的数据库中
- 用户打开目标网站时,服务端将恶意代码从数据库中取出来,拼接在HTML中返回给浏览器
- 用户浏览器在收到响应后解析执行,混在其中的恶意代码也同时被执行
- 恶意代码窃取用户数据,并发送到指定攻击者的网站,或者冒充用户行为,调用目标网站的接口,执行恶意操作
反射型(Server端)
与存储型的区别在于,存储型的恶意代码存储在数据库中,反射型的恶意代码在URL上
场景:通过 URL 传递参数的功能,如网站搜索、跳转等。
攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- 用户打开带有恶意代码的 URL 时,网站服务端将恶意代码从 URL 中取出,拼接在 HTML 中返回给浏览器。
- 用户浏览器接收到响应后解析执行,混在其中的恶意代码也被执行。
- 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
Dom 型(浏览器端)
DOM 型 XSS 攻击中,取出和执行恶意代码由浏览器端完成,属于前端 JavaScript 自身的安全漏洞,而其他两种 XSS 都属于服务端的安全漏洞。
- 场景:通过 URL 传递参数的功能,如网站搜索、跳转等。
- 攻击步骤:
- 攻击者构造出特殊的 URL,其中包含恶意代码。
- 用户打开带有恶意代码的 URL。
- 用户浏览器接收到响应后解析执行,前端 JavaScript 取出 URL 中的恶意代码并执行。
- 恶意代码窃取用户数据并发送到攻击者的网站,或者冒充用户的行为,调用目标网站接口执行攻击者指定的操作。
预防方案
防止攻击者提交恶意代码,防止浏览器执行恶意代码。
- 对数据进行严格的输出编码:如HTML元素的编码,JS编码,CSS编码,URL编码等等
- 避免拼接 HTML;Vue/React 技术栈,避免使用 v-html / dangerouslySetInnerHTML
- CSP HTTP Header,即 Content-Security-Policy、X-XSS-Protection
- 增加攻击难度,配置CSP(本质是建立白名单,由浏览器进行拦截)
Content-Security-Policy: default-src 'self'- 所有内容均来自站点的同一个源(不包括其子域名)Content-Security-Policy: default-src 'self' *.trusted.com- 允许内容来自信任的域名及其子域名 (域名不必须与CSP设置所在的域名相同)Content-Security-Policy: default-src https://yideng.com- 该服务器仅允许通过HTTPS方式并仅从yideng.com域名来访问文档
- 输入验证:比如一些常见的数字、URL、电话号码、邮箱地址等等做校验判断
- 开启浏览器XSS防御:Http Only cookie,禁止 JavaScript 读取某些敏感 Cookie,攻击者完成 XSS 注入后也无法窃取此 Cookie。
- 验证码
CSRF:跨站请求伪造
攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
攻击流程举例
- 受害者登录 a.com,并保留了登录凭证(Cookie)
- 攻击者引诱受害者访问了b.com
- b.com 向 a.com 发送了一个请求:a.com/act=xx浏览器会默认携带a.com的Cookie
- a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求
- a.com以受害者的名义执行了act=xx
- 攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让a.com执行了自己定义的操作
攻击类型
- GET型:如在页面的某个 img 中发起一个 get 请求
- POST型:通过自动提交表单到恶意网站
- 链接型:需要诱导用户点击链接
预防方案
CSRF通常从第三方网站发起,被攻击的网站无法防止攻击发生,只能通过增强自己网站针对CSRF的防护能力来提升安全性。
- 同源检测:通过Header中的Origin Header 、Referer Header 确定,但不同浏览器可能会有不一样的实现,不能完全保证
- CSRF Token 校验:将CSRF Token输出到页面中(通常保存在Session中),页面提交的请求携带这个Token,服务器验证Token是否正确
- 双重cookie验证:
- 流程:
- 步骤1:在用户访问网站页面时,向请求域名注入一个Cookie,内容为随机字符串(例如csrfcookie=v8g9e4ksfhw)
- 步骤2:在前端向后端发起请求时,取出Cookie,并添加到URL的参数中(接上例POST https://www.a.com/comment?csrfcookie=v8g9e4ksfhw)
- 步骤3:后端接口验证Cookie中的字段与URL参数中的字段是否一致,不一致则拒绝。
- 优点:
- 无需使用Session,适用面更广,易于实施。
- Token储存于客户端中,不会给服务器带来压力。
- 相对于Token,实施成本更低,可以在前后端统一拦截校验,而不需要一个个接口和页面添加。
- 缺点:
- Cookie中增加了额外的字段。
- 如果有其他漏洞(例如XSS),攻击者可以注入Cookie,那么该防御方式失效。
- 难以做到子域名的隔离。
- 为了确保Cookie传输安全,采用这种防御方式的最好确保用整站HTTPS的方式,如果还没切HTTPS的使用这种方式也会有风险。
- Samesite Cookie属性:Google起草了一份草案来改进HTTP协议,那就是为Set-Cookie响应头新增Samesite属性,它用来标明这个 Cookie是个“同站 Cookie”,同站Cookie只能作为第一方Cookie,不能作为第三方Cookie,Samesite 有两个属性值,Strict 为任何情况下都不可以作为第三方 Cookie ,Lax 为可以作为第三方 Cookie , 但必须是Get请求
3)iframe 安全
说明
- 嵌入第三方 iframe 会有很多不可控的问题,同时当第三方 iframe 出现问题或是被劫持之后,也会诱发安全性问题
- 点击劫持
- 攻击者将目标网站通过 iframe 嵌套的方式嵌入自己的网页中,并将 iframe 设置为透明,诱导用户点击。
- 禁止自己的 iframe 中的链接外部网站的JS
预防方案
- 为 iframe 设置 sandbox 属性,通过它可以对iframe的行为进行各种限制,充分实现“最小权限“原则
- 服务端设置 X-Frame-Options Header头,拒绝页面被嵌套,X-Frame-Options 是HTTP 响应头中用来告诉浏览器一个页面是否可以嵌入 <iframe> 中
- eg.X-Frame-Options: SAMEORIGIN
- SAMEORIGIN: iframe 页面的地址只能为同源域名下的页面
- ALLOW-FROM: 可以嵌套在指定来源的 iframe 里
- DENY: 当前页面不能被嵌套在 iframe 里
- 设置 CSP 即 Content-Security-Policy 请求头
- 减少对 iframe 的使用
4)错误的内容推断
说明
文件上传类型校验失败后,导致恶意的JS文件上传后,浏览器 Content-Type Header 的默认解析为可执行的 JS 文件
预防方案
设置 X-Content-Type-Options 头
5)第三方依赖包
减少对第三方依赖包的使用,如之前 npm 的包如:event-stream 被爆出恶意攻击数字货币;
6)HTTPS
描述
黑客可以利用SSL Stripping这种攻击手段,强制让HTTPS降级回HTTP,从而继续进行中间人攻击。
预防方案
解决这个安全问题的办法是使用HSTS(HTTP Strict Transport Security),它通过下面这个HTTP Header以及一个预加载的清单,来告知浏览器在和网站进行通信的时候强制性的使用HTTPS,而不是通过明文的HTTP进行通信:
1 | Strict-Transport-Security: max-age=<seconds>; includeSubDomains; preload |
这里的“强制性”表现为浏览器无论在何种情况下都直接向服务器端发起HTTPS请求,而不再像以往那样从HTTP跳转到HTTPS。另外,当遇到证书或者链接不安全的时候,则首先警告用户,并且不再让用户选择是否继续进行不安全的通信。
7)本地存储数据
避免重要的用户信息存在浏览器缓存中
8)静态资源完整性校验
描述
使用 内容分发网络 (CDNs) 在多个站点之间共享脚本和样式表等文件可以提高站点性能并节省带宽。然而,使用CDN也存在风险,如果攻击者获得对 CDN 的控制权,则可以将任意恶意内容注入到 CDN 上的文件中 (或完全替换掉文件),因此可能潜在地攻击所有从该 CDN 获取文件的站点。
预防方案
将使用 base64 编码过后的文件哈希值写入你所引用的 <script> 或 标签的 integrity 属性值中即可启用子资源完整性能。
9)网络劫持
描述
- DNS劫持(涉嫌违法):修改运行商的 DNS 记录,重定向到其他网站。DNS 劫持是违法的行为,目前 DNS 劫持已被监管,现在很少见 DNS 劫持
- HTTP劫持:前提有 HTTP 请求。因 HTTP 是明文传输,运营商便可借机修改 HTTP 响应内容(如加广告)。
预防方案
全站 HTTPS
10)中间人攻击
中间人攻击(Man-in-the-middle attack, MITM),指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方直接对话,但事实上整个会话都被攻击者窃听、篡改甚至完全控制。没有进行严格的证书校验是中间人攻击着手点。目前大多数加密协议都提供了一些特殊认证方法以阻止中间人攻击。如 SSL (安全套接字层)协议可以验证参与通讯的用户的证书是否有权威、受信任的数字证书认证机构颁发,并且能执行双向身份认证。攻击场景如用户在一个未加密的 WiFi下访问网站。在中间人攻击中,攻击者可以拦截通讯双方的通话并插入新的内容。
场景
- 在一个未加密的Wi-Fi 无线接入点的接受范围内的中间人攻击者,可以将自己作为一个中间人插入这个网络
- Fiddler / Charles (花瓶)代理工具
- 12306 之前的自己证书
过程
- 客户端发送请求到服务端,请求被中间人截获
- 服务器向客户端发送公钥
- 中间人截获公钥,保留在自己手上。然后自己生成一个【伪造的】公钥,发给客户端
- 客户端收到伪造的公钥后,生成加密hash值发给服务器
- 中间人获得加密hash值,用自己的私钥解密获得真秘钥,同时生成假的加密hash值,发给服务器
- 服务器用私钥解密获得假密钥,然后加密数据传输给客户端
使用抓包工具fiddle来进行举例说明
- 首先通过一些途径在客户端安装证书
- 然后客户端发送连接请求,fiddle在中间截取请求,并返回自己伪造的证书
- 客户端已经安装了攻击者的根证书,所以验证通过
- 客户端就会正常和fiddle进行通信,把fiddle当作正确的服务器
- 同时fiddle会跟原有的服务器进行通信,获取数据以及加密的密钥,去解密密钥
常见攻击方式
- 嗅探:嗅探是一种用来捕获流进和流出的网络数据包的技术,就好像是监听电话一样。比如:抓包工具
- 数据包注入:在这种,攻击者会将恶意数据包注入到常规数据中的,因为这些恶意数据包是在正常的数据包里面的,用户和系统都很难发现这个内容。
- 会话劫持:当我们进行一个网站的登录的时候到退出登录这个时候,会产生一个会话,这个会话是攻击者用来攻击的首要目标,因为这个会话,包含了用户大量的数据和私密信息。
- SSL剥离:HTTPS是通过SSL/TLS进行加密过的,在SSL剥离攻击中,会使SSL/TLS连接断开,让受保护的HTTPS,变成不受保护的HTTP(这对于网站非常致命)
- DNS欺骗:攻击者往往通过入侵到DNS服务器,或者篡改用户本地hosts文件,然后去劫持用户发送的请求,然后转发到攻击者想要转发到的服务器
- ARP欺骗: ARP(address resolution protocol)地址解析协议,攻击者利用APR的漏洞,用当前局域网之间的一台服务器,来冒充客户端想要请求的服务端,向客户端发送自己的MAC地址,客户端无从得到真正的主机的MAC地址,所以,他会把这个地址当作真正的主机来进行通信,将MAC存入ARP缓存表。
- 代理服务器
预防方案
- 用可信的第三方CA厂商
- 不下载未知来源的证书,不要去下载一些不安全的文件
- 确认你访问的URL是HTTPS的,确保网站使用了SSL,确保禁用一些不安全的SSL,只开启:TLS1.1,TLS1.2
- 不要使用公用网络发送一些敏感的信息
- 不要去点击一些不安全的连接或者恶意链接或邮件信息
11)sql 注入
描述
就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗数据库服务器执行恶意的SQL命令,从而达到和服务器
进行直接的交互
预防方案
- 后台进行输入验证,对敏感字符过滤。
- 使用参数化查询,能避免拼接SQL,就不要拼接SQL语句。
12)前端数据安全
描述
反爬虫。如猫眼电影、天眼查等等,以数据内容为核心资产的企业
预防方案
- font-face拼接方式:猫眼电影、天眼查
- background 拼接:美团
- 伪元素隐藏:汽车之家
- 元素定位覆盖式:去哪儿
- iframe 异步加载:网易云音乐
13)其他建议
- 定期请第三方机构做安全性测试,漏洞扫描
- 使用第三方开源库做上线前的安全测试,可以考虑融合到CI中
- code review 保证代码质量
- 默认项目中设置对应的 Header 请求头,如 X-XSS-Protection、 X-Content-Type-Options 、X-Frame-Options Header、Content-Security-Policy 等等
- 对第三方包和库做检测:NSP(Node Security Platform),Snyk
对闭包的看法,为什么要用闭包?说一下闭包原理以及应用场景
1)什么是闭包
函数执行后返回结果是一个内部函数,并被外部变量所引用,如果内部函数持有被执行函数作用域的变量,即形成了闭包。
可以在内部函数访问到外部函数作用域。使用闭包,一可以读取函数中的变量,二可以将函数中的变量存储在内存中,保护变量不被污染。而正因闭包会把函数中的变量值存储在内存中,会对内存有消耗,所以不能滥用闭包,否则会影响网页性能,造成内存泄漏。当不需要使用闭包时,要及时释放内存,可将内层函数对象的变量赋值为null。
2)闭包原理
函数执行分成两个阶段(预编译阶段和执行阶段)。
在预编译阶段,如果发现内部函数使用了外部函数的变量,则会在内存中创建一个“闭包”对象并保存对应变量值,如果已存在“闭包”,则只需要增加对应属性值即可。
执行完后,函数执行上下文会被销毁,函数对“闭包”对象的引用也会被销毁,但其内部函数还持用该“闭包”的引用,所以内部函数可以继续使用“外部函数”中的变量
利用了函数作用域链的特性,一个函数内部定义的函数会将包含外部函数的活动对象添加到它的作用域链中,函数执行完毕,其执行作用域链销毁,但因内部函数的作用域链仍然在引用这个活动对象,所以其活动对象不会被销毁,直到内部函数被销毁后才被销毁。
3)优点
- 可以从内部函数访问外部函数的作用域中的变量,且访问到的变量长期驻扎在内存中,可供之后使用
- 避免变量污染全局
- 把变量存到独立的作用域,作为私有成员存在
4)缺点
- 对内存消耗有负面影响。因内部函数保存了对外部变量的引用,导致无法被垃圾回收,增大内存使用量,所以使用不当会导致内存泄漏
- 对处理速度具有负面影响。闭包的层级决定了引用的外部变量在查找时经过的作用域链长度
- 可能获取到意外的值(captured value)
5)应用场景
应用场景一
典型应用是模块封装,在各模块规范出现之前,都是用这样的方式防止变量污染全局。
1 | var Yideng = (function () { |
应用场景二
在循环中创建闭包,防止取到意外的值。
如下代码,无论哪个元素触发事件,都会弹出 3。因为函数执行后引用的 i 是同一个,而 i 在循环结束后就是 3
1 | for (var i = 0; i < 3; i++) { |
CSS 伪类与伪元素区别
1)伪类(pseudo-classes)
- 其核⼼就是⽤来选择DOM树之外的信息,不能够被普通选择器选择的⽂档之外的元素,⽤来添加⼀些选择器的特殊效果。
- ⽐如:hover :active :visited :link :first-child :focus :lang等
- 由于状态的变化是⾮静态的,所以元素达到⼀个特定状态时,它可能得到⼀个伪类的样式;当状态改变时,它⼜会失去这个样式。
- 由此可以看出,它的功能和class有些类似,但它是基于⽂档之外的抽象,所以叫 伪类。
2)伪元素(Pseudo-elements)
- DOM树没有定义的虚拟元素
- 核⼼就是需要创建通常不存在于⽂档中的元素。
- ⽐如::before ::after 表示选择元素内容的之前内容或之后内容。
- 伪元素控制的内容和元素是没有差别的,但是它本身只是基于元素的抽象,并不存在于⽂档中,所以称为伪元素。⽤于将特殊的效果添加到某些选择器
3)伪类与伪元素的区别
表示⽅法
- CSS2 中伪类、伪元素都是以单冒号:表示,
- CSS2.1 后规定伪类⽤单冒号表示,伪元素⽤双冒号::表示,
- 浏览器同样接受 CSS2 时代已经存在的伪元素(:before, :after, :first-line, :first-letter 等)的单冒号写法。
- CSS2 之后所有新增的伪元素(如::selection),应该采⽤双冒号的写法。
- CSS3中,伪类与伪元素在语法上也有所区别,伪元素修改为以::开头。浏览器对以:开头的伪元素也继续⽀持,但建议规范书写为::开头
定义不同
- 伪类即假的类,可以添加类来达到效果
- 伪元素即假元素,需要通过添加元素才能达到效果
总结
- 伪类和伪元素都是⽤来表示⽂档树以外的”元素”。
- 伪类和伪元素分别⽤单冒号:和双冒号::来表示。
- 伪类和伪元素的区别,关键点在于如果没有伪元素(或伪类),
- 是否需要添加元素才能达到效果,如果是则是伪元素,反之则是伪类。
4)相同之处
- 伪类和伪元素都不出现在源⽂件和DOM树中。也就是说在html源⽂件中是看不到伪类和伪元素的。
5)不同之处
- 伪类其实就是基于普通DOM元素⽽产⽣的不同状态,他是DOM元素的某⼀特征。
- 伪元素能够创建在DOM树中不存在的抽象对象,⽽且这些抽象对象是能够访问到的。
有一堆整数,请把他们分成三份,确保每一份和尽量相等(11,42,23,4,5,6, 4, 5, 6, 11, 23, 42, 56, 78, 90)
1 | function f1(arr, count) { |
实现 lodash 的_.get
在 js 中经常会出现嵌套调用这种情况,如 a.b.c.d.e,但是这么写很容易抛出异常。你需要这么写 a && a.b && a.b.c && a.b.c.d && a.b.c.d.e,但是显得有些啰嗦与冗长了。特别是在 graphql 中,这种嵌套调用更是难以避免。
这时就需要一个 get 函数,使用 get(a, ‘b.c.d.e’) 简单清晰,并且容错性提高了很多。
1)代码实现
1 | function get(source, path, defaultValue = undefined) { |
实现 add(1)(2)(3)
考点:函数柯里化
函数柯里化概念: 柯里化(Currying)是把接受多个参数的函数转变为接受一个单一参数的函数,并且返回接受余下的参数且返回结果的新函数的技术。
1)粗暴版
1 | function add (a) { |
2)柯里化解决方案
参数长度固定
1 | const curry = (fn) =>(judge = (...args) => args.length === fn.length ? fn(...args) : (...arg) => judge(...args, ...arg)); |
参数长度不固定
1 | function add (...args) { |
类数组和数组的区别,dom 的类数组如何转换成数组
1)定义
- 数组是一个特殊对象,与常规对象的区别:
- 当由新元素添加到列表中时,自动更新length属性
- 设置length属性,可以截断数组
- 从Array.protoype中继承了方法
- 属性为’Array’
- 类数组是一个拥有length属性,并且他属性为非负整数的普通对象,类数组不能直接调用数组方法
2)区别
本质:类数组是简单对象,它的原型关系与数组不同。
1 | // 原型关系和原始值转换 |
3)类数组转换为数组
转换方法
- 使用 Array.from()
- 使用 Array.prototype.slice.call()
- 使用 Array.prototype.forEach() 进行属性遍历并组成新的数组
转换须知
- 转换后的数组长度由 length 属性决定。索引不连续时转换结果是连续的,会自动补位。
- 代码示例
1
2
3
4
5
6
7
8
9let al1 = {
length: 4,
0: 0,
1: 1,
3: 3,
4: 4,
5: 5,
};
console.log(Array.from(al1)) // [0, 1, undefined, 3]- 仅考虑 0或正整数的索引
1
2
3
4
5
6
7
8
9// 代码示例
let al2 = {
length: 4,
'-1': -1,
'0': 0,
a: 'a',
1: 1
};
console.log(Array.from(al2)); // [0, 1, undefined, undefined]- 使用slice转换产生稀疏数组
1
2
3
4
5
6
7
8
9// 代码示例
let al2 = {
length: 4,
'-1': -1,
'0': 0,
a: 'a',
1: 1
};
console.log(Array.prototype.slice.call(al2)); //[0, 1, empty × 2]
4)使用数组方法操作类数组注意地方
1 | let arrayLike2 = { |
webpack 打包优化的四种方法(多进程打包,多进程压缩,资源 CDN,动态 polyfill)
打包分析
1. 速度分析
我们的目的是优化打包速度,那肯定需要一个速度分析插件,此时 speed-measure-webpack-plugin 就派上用场了。它的作用如下:
- 分析整个打包总耗时
- 每个 plugin 和 loader 的耗时情况
安装插件
1 | npm install --save-dev speed-measure-webpack-plugin |
使用插件
修改配置webpack.config.js文件
1 | // 导入速度分析插件 |
运行打包命令之后,可以看到,打包总耗时为 15.48 secs
效果如下所示:

2. 体积分析
分析完打包速度之后,接着我们来分析打包之后每个文件以及每个模块对应的体积大小。使用到的插件为 webpack-bundle-analyzer,构建完成后会在 8888 端口展示大小。
安装插件
1 | npm install --save-dev webpack-bundle-analyzer |
使用插件
修改配置webpack.config.js文件
1 | // 导入速度分析插件 |
构建之后可以看到,其中黄色块 chunk-vendors 文件占比最大,为 1.34MB
效果如下所示:

打包优化
1. 多进程多实例构建,资源并行解析
多进程构建的方案比较知名的有以下三个:
- thread-loader (推荐使用这个)
- parallel-webpack
- HappyPack
这里以 thread-loader 为例配置多进程多实例构建
安装 loader
1 | npm install --save-dev thread-loader |
使用 loader
修改配置webpack.config.js文件
1 | const path = require("path"); |
2. 公用代码提取,使用 CDN 加载
以vue.js构建的项目为例,里面很多的第三方库只要不升级对应的版本其内容是不变的,我们可以将这些内用文件不通过webpack打包到模块里面,而是使用CDN加载,例如对于vue,vuex,vue-router,axios,echarts,swiper等第三方库我们可以利用webpack的externals参数来配置,这里我们设定只需要在生产环境中才需要使用。
这里需要使用 html-webpack-plugin 和 webpack-cdn-plugin 两个插件
安装插件
1 | npm install --save-dev html-webpack-plugin, webpack-cdn-plugin |
使用插件
修改配置webpack.config.js文件
1 | const path = require("path"); |
最终生成的inde.html文件如下所示:
1 |
|
3. 多进程多实例并行压缩
并行压缩主流有以下三种方案
- 使用 parallel-uglify-plugin 插件
- uglifyjs-webpack-plugin 开启 parallel 参数
- terser-webpack-plugin 开启 parallel 参数 (推荐使用这个,支持 ES6 语法压缩)
安装插件
1 | npm install --save-dev terser-webpack-plugin |
使用插件
修改配置webpack.config.js文件
1 | const path = require("path"); |
4. 使用 polyfill 动态服务
Polyfill 可以为旧浏览器提供和标准 API 一样的功能。比如你想要 IE 浏览器实现 Promise 和 fetch 功能,你需要手动引入 es6-promise、whatwg-fetch。而通过 Polyfill.io,你只需要引入一个 JS 文件。
Polyfill.io 通过分析请求头信息中的 UserAgent 实现自动加载浏览器所需的 polyfills。 Polyfill.io 有一份默认功能列表,包括了最常见的 polyfills:document.querySelector、Element.classList、ES5 新增的 Array 方法、Date.now、ES6 中的 Object.assign、Promise 等。
动态 polyfill 指的是根据不同的浏览器,动态载入需要的 polyfill。 Polyfill.io 通过尝试使用 polyfill 重新创建缺少的功能,可以更轻松地支持不同的浏览器,并且可以大幅度的减少构建体积。
Polyfill Service 原理
识别 User Agent,下发不同的 Polyfill

使用方法:
在 index.html 中引入如下 script 标签
1 |
|
webpack 做过哪些优化,开发效率方面、打包策略方面等等
1)优化 Webpack 的构建速度
- 使用高版本的 Webpack (使用webpack4)
- 多线程/多实例构建:HappyPack(不维护了)、thread-loader
- 缩小打包作用域:
- exclude/include (确定 loader 规则范围)
- resolve.modules 指明第三方模块的绝对路径 (减少不必要的查找)
- resolve.extensions 尽可能减少后缀尝试的可能性
- noParse 对完全不需要解析的库进行忽略 (不去解析但仍会打包到 bundle 中,注意被忽略掉的文件里不应该包含 import、require、define 等模块化语句)
- IgnorePlugin (完全排除模块)
- 合理使用alias
- 充分利用缓存提升二次构建速度:
- babel-loader 开启缓存
- terser-webpack-plugin 开启缓存
- 使用 cache-loader 或者 hard-source-webpack-plugin
注意:thread-loader 和 cache-loader 兩個要一起使用的話,請先放 cache-loader 接著是 thread-loader 最後才是 heavy-loader
- DLL:
- 使用 DllPlugin 进行分包,使用 DllReferencePlugin(索引链接) 对 manifest.json 引用,让一些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间。
2)使用webpack4-优化原因
- V8带来的优化(for of替代forEach、Map和Set替代Object、includes替代indexOf)
- 默认使用更快的md4 hash算法
- webpacks AST可以直接从loader传递给AST,减少解析时间
- 使用字符串方法替代正则表达式
noParse
- 不去解析某个库内部的依赖关系
- 比如jquery 这个库是独立的, 则不去解析这个库内部依赖的其他的东西
- 在独立库的时候可以使用
1 | module.exports = { |
IgnorePlugin
- 忽略掉某些内容 不去解析依赖库内部引用的某些内容
- 从moment中引用 ./locol 则忽略掉
- 如果要用local的话 则必须在项目中必须手动引入 import ‘moment/locale/zh-cn’
1 | module.exports = { |
dllPlugin
- 不会多次打包, 优化打包时间
- 先把依赖的不变的库打包
- 生成 manifest.json文件
- 然后在webpack.config中引入
- webpack.DllPlugin Webpack.DllReferencePlugin
happypack -> thread-loader
- 大项目的时候开启多线程打包
- 影响前端发布速度的有两个方面,一个是构建,一个就是压缩,把这两个东西优化起来,可以减少很多发布的时间。
thread-loader
thread-loader 会将您的 loader 放置在一个 worker 池里面运行,以达到多线程构建。
把这个 loader 放置在其他 loader 之前(如下图 example 的位置), 放置在这个 loader 之后的 loader 就会在一个单独的 worker 池(worker pool)中运行。
1 | // webpack.config.js |
每个 worker 都是一个单独的有 600ms 限制的 node.js 进程。同时跨进程的数据交换也会被限制。请在高开销的loader中使用,否则效果不佳
压缩加速——开启多线程压缩
- 不推荐使用 webpack-paralle-uglify-plugin,项目基本处于没人维护的阶段,issue 没人处理,pr没人合并。
Webpack 4.0以前:uglifyjs-webpack-plugin,parallel参数
1 | module.exports = { |
- 推荐使用 terser-webpack-plugin
1 | module.exports = { |
2)优化 Webpack 的打包体积
- 压缩代码
- webpack-paralle-uglify-plugin
- uglifyjs-webpack-plugin 开启 parallel 参数 (不支持ES6)
- terser-webpack-plugin 开启 parallel 参数
- 多进程并行压缩
- 通过 mini-css-extract-plugin 提取 Chunk 中的 CSS 代码到单独文件,通过optimize-css-assets-webpack-plugin插件 开启 cssnano 压缩 CSS。
- 提取页面公共资源
- 使用 html-webpack-externals-plugin,将基础包通过 CDN 引入,不打入 bundle 中
- 使用 SplitChunksPlugin 进行(公共脚本、基础包、页面公共文件)分离(Webpack4内置) ,替代了 CommonsChunkPlugin 插件
- 基础包分离:将一些基础库放到cdn,比如vue,webpack 配置 external是的vue不打入bundle
- Tree shaking
- purgecss-webpack-plugin 和 mini-css-extract-plugin配合使用(建议)
- 打包过程中检测工程中没有引用过的模块并进行标记,在资源压缩时将它们从最终的bundle中去掉(只能对ES6 Modlue生效) 开发中尽可能使用ES6 Module的模块,提高tree shaking效率
- 禁用 babel-loader 的模块依赖解析,否则 Webpack 接收到的就都是转换过的 CommonJS 形式的模块,无法进行 tree-shaking
- 使用 PurifyCSS(不在维护) 或者 uncss 去除无用 CSS 代码
- Scope hosting
- 构建后的代码会存在大量闭包,造成体积增大,运行代码时创建的函数作用域变多,内存开销变大。Scope hosting 将所有模块的代码按照引用顺序放在一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突
- 必须是ES6的语法,因为有很多第三方库仍采用 CommonJS 语法,为了充分发挥 Scope hosting 的作用,需要配置 mainFields 对第三方模块优先采用 jsnext:main 中指向的ES6模块化语法
- 图片压缩
- 使用基于 Node 库的 imagemin (很多定制选项、可以处理多种图片格式)
- 配置 image-webpack-loader
- 动态Polyfill
- 建议采用 polyfill-service 只给用户返回需要的polyfill,社区维护。(部分国内奇葩浏览器UA可能无法识别,但可以降级返回所需全部polyfill)
- @babel-preset-env 中通过useBuiltIns: ‘usage参数来动态加载polyfill。
3)speed-measure-webpack-plugin
简称 SMP,分析出 Webpack 打包过程中 Loader 和 Plugin 的耗时,有助于找到构建过程中的性能瓶颈。
4)开发阶段常用的插件
开启多核压缩
插件:terser-webpack-plugin
1 | const TerserPlugin = require('terser-webpack-plugin') |
监控面板
插件:speed-measure-webpack-plugin
在打包的时候显示出每一个loader,plugin所用的时间,来精准优化
1 | // webpack.config.js文件 |
开启一个通知面板
插件:webpack-build-notifier
1 | // webpack.config.js文件 |
开启打包进度
插件:progress-bar-webpack-plugin
1 | // webpack.config.js文件 |
开发面板更清晰
插件:webpack-dashboard
1 | // webpack.config.js文件 |
1 | // package.json文件 |
开启窗口的标题
第三方库: node-bash-title
这个包mac的item用有效果,windows暂时没看到效果
1 | // webpack.config.js文件 |
friendly-errors-webpack-plugin
插件:friendly-errors-webpack-plugin
1 | const webpackConfig= { |
如何封装 node 中间件
在NodeJS中,中间件主要是指封装所有Http请求细节处理的方法。一次Http请求通常包含很多工作,如记录日志、ip过滤、查询字符串、请求体解析、Cookie处理、权限验证、参数验证、异常处理等,但对于Web应用而言,并不希望接触到这么多细节性的处理,因此引入中间件来简化和隔离这些基础设施与业务逻辑之间的细节,让开发者能够关注在业务的开发上,以达到提升开发效率的目的。
中间件的行为比较类似Java中过滤器的工作原理,就是在进入具体的业务处理之前,先让过滤器处理。
1 | const http = require('http') |
node 中间层怎样做的请求合并转发
1)什么是中间层
- 就是前端—请求—> nodejs —-请求—->后端 —-响应—>nodejs–数据处理—响应—->前端。这么一个流程,这个流程的好处就是当业务逻辑过多,或者业务需求在不断变更的时候,前端不需要过多当去改变业务逻辑,与后端低耦合。前端即显示,渲染。后端获取和存储数据。中间层处理数据结构,返回给前端可用可渲染的数据结构。
- nodejs是起中间层的作用,即根据客户端不同请求来做相应的处理或渲染页面,处理时可以是把获取的数据做简单的处理交由底层java那边做真正的数据持久化或数据更新,也可以是从底层获取数据做简单的处理返回给客户端。
- 通常我们把Web领域分为客户端和服务端,也就是前端和后端,这里的后端就包含了网关,静态资源,接口,缓存,数据库等。而中间层呢,就是在后端这里再抽离一层出来,在业务上处理和客户端衔接更紧密的部分,比如页面渲染(SSR),数据聚合,接口转发等等。
- 以SSR来说,在服务端将页面渲染好,可以加快用户的首屏加载速度,避免请求时白屏,还有利于网站做SEO,他的好处是比较好理解的。
2)中间层可以做的事情
- 代理:在开发环境下,我们可以利用代理来,解决最常见的跨域问题;在线上环境下,我们可以利用代理,转发请求到多个服务端。
- 缓存:缓存其实是更靠近前端的需求,用户的动作触发数据的更新,node中间层可以直接处理一部分缓存需求。
- 限流:node中间层,可以针对接口或者路由做响应的限流。
- 日志:相比其他服务端语言,node中间层的日志记录,能更方便快捷的定位问题(是在浏览器端还是服务端)。
- 监控:擅长高并发的请求处理,做监控也是合适的选项。
- 鉴权:有一个中间层去鉴权,也是一种单一职责的实现。
- 路由:前端更需要掌握页面路由的权限和逻辑。
- 服务端渲染:node中间层的解决方案更灵活,比如SSR、模板直出、利用一些JS库做预渲染等等。
3)node转发API(node中间层)的优势
- 可以在中间层把java|php的数据,处理成对前端更友好的格式
- 可以解决前端的跨域问题,因为服务器端的请求是不涉及跨域的,跨域是浏览器的同源策略导致的
- 可以将多个请求在通过中间层合并,减少前端的请求
4)如何做请求合并转发
- 使用express中间件multifetch可以将请求批量合并
- 使用express+http-proxy-middleware实现接口代理转发
5)不使用用第三方模块手动实现一个nodejs代理服务器,实现请求合并转发
实现思路
- 搭建http服务器,使用Node的http模块的createServer方法
- 接收客户端发送的请求,就是请求报文,请求报文中包括请求行、请求头、请求体
- 将请求报文发送到目标服务器,使用http模块的request方法
实现步骤
- 第一步:http服务器搭建
1 | const http = require("http"); |
- 第二步:接收客户端发送到代理服务器的请求报文
1 | const http = require("http"); |
这一步主要数据在客户端到服务器端进行传输时在nodejs中需要用到buffer来处理一下。处理过程就是将所有接收的数据片段chunk塞到一个数组中,然后将其合并到一起还原出源数据。合并方法需要用到Buffer.concat,这里不能使用加号,加号会隐式的将buffer转化为字符串,这种转化不安全。
- 第三步:使用http模块的request方法,将请求报文发送到目标服务器
第二步已经得到了客户端上传的数据,但是缺少请求头,所以在这一步根据客户端发送的请求需要构造请求头,然后发送
1 | const http = require("http"); |
介绍下 promise 的特性、优缺点,内部是如何实现的,动手实现 Promise
1)Promise基本特性
- Promise有三种状态:pending(进行中)、fulfilled(已成功)、rejected(已失败)
- Promise对象接受一个回调函数作为参数, 该回调函数接受两个参数,分别是成功时的回调resolve和失败时的回调reject;另外resolve的参数除了正常值以外, 还可能是一个Promise对象的实例;reject的参数通常是一个Error对象的实例。
- then方法返回一个新的Promise实例,并接收两个参数onResolved(fulfilled状态的回调);onRejected(rejected状态的回调,该参数可选)
- catch方法返回一个新的Promise实例
- finally方法不管Promise状态如何都会执行,该方法的回调函数不接受任何参数
- Promise.all()方法将多个多个Promise实例,包装成一个新的Promise实例,该方法接受一个由Promise对象组成的数组作为参数(Promise.all()方法的参数可以不是数组,但必须具有Iterator接口,且返回的每个成员都是Promise实例),注意参数中只要有一个实例触发catch方法,都会触发Promise.all()方法返回的新的实例的catch方法,如果参数中的某个实例本身调用了catch方法,将不会触发Promise.all()方法返回的新实例的catch方法
- Promise.race()方法的参数与Promise.all方法一样,参数中的实例只要有一个率先改变状态就会将该实例的状态传给Promise.race()方法,并将返回值作为Promise.race()方法产生的Promise实例的返回值
- Promise.resolve()将现有对象转为Promise对象,如果该方法的参数为一个Promise对象,Promise.resolve()将不做任何处理;如果参数thenable对象(即具有then方法),Promise.resolve()将该对象转为Promise对象并立即执行then方法;如果参数是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为fulfilled,其参数将会作为then方法中onResolved回调函数的参数,如果Promise.resolve方法不带参数,会直接返回一个fulfilled状态的 Promise 对象。需要注意的是,立即resolve()的 Promise 对象,是在本轮“事件循环”(event loop)的结束时执行,而不是在下一轮“事件循环”的开始时。
- Promise.reject()同样返回一个新的Promise对象,状态为rejected,无论传入任何参数都将作为reject()的参数
2)Promise优点
- 统一异步 API
Promise 的一个重要优点是它将逐渐被用作浏览器的异步 API ,统一现在各种各样的 API ,以及不兼容的模式和手法。 - Promise 与事件对比
和事件相比较, Promise 更适合处理一次性的结果。在结果计算出来之前或之后注册回调函数都是可以的,都可以拿到正确的值。 Promise 的这个优点很自然。但是,不能使用 Promise 处理多次触发的事件。链式处理是 Promise 的又一优点,但是事件却不能这样链式处理。 - Promise 与回调对比
解决了回调地狱的问题,将异步操作以同步操作的流程表达出来。 - Promise 带来的额外好处是包含了更好的错误处理方式(包含了异常处理),并且写起来很轻松(因为可以重用一些同步的工具,比如 Array.prototype.map() )。
3)Promise缺点
- 无法取消Promise,一旦新建它就会立即执行,无法中途取消。
- 如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
- 当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
- Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以 Promise 的报错堆栈上下文不太友好。
4)简单代码实现
最简单的Promise实现有7个主要属性, state(状态), value(成功返回值), reason(错误信息), resolve方法, reject方法, then方法。
1 | class Promise { |
实现 Promise.all
1)核心思路
- 接收一个 Promise 实例的数组或具有 Iterator 接口的对象作为参数
- 这个方法返回一个新的 promise 对象,
- 遍历传入的参数,用Promise.resolve()将参数”包一层”,使其变成一个promise对象
- 参数所有回调成功才是成功,返回值数组与参数顺序一致
- 参数数组其中一个失败,则触发失败状态,第一个触发失败的 Promise 错误信息作为 Promise.all 的错误信息。
2)实现代码
一般来说,Promise.all 用来处理多个并发请求,也是为了页面数据构造的方便,将一个页面所用到的在不同接口的数据一起请求过来,不过,如果其中一个接口失败了,多个请求也就失败了,页面可能啥也出不来,这就看当前页面的耦合程度了~
1 | function promiseAll(promises) { |
delete 操作的注意点
知识点
- delete使用原则:delete 操作符用来删除一个对象的属性。
- delete在删除一个不可配置的属性时在严格模式和非严格模式下的区别:
- (1)在严格模式中,如果属性是一个不可配置(non-configurable)属性,删除时会抛出异常;
- (2)非严格模式下返回 false。
- delete能删除隐式声明的全局变量:这个全局变量其实是global对象(window)的属性
- delete能删除的:
- (1)可配置对象的属性
- (2)隐式声明的全局变量
- (3)用户定义的属性
- (4)在ECMAScript 6中,通过 const 或 let 声明指定的 “temporal dead zone” (TDZ) 对 delete 操作符也会起作用
- delete不能删除的:
- (1)显式声明的全局变量
- (2)内置对象的内置属性
- (3)一个对象从原型继承而来的属性
- delete删除数组元素:
- (1)当你删除一个数组元素时,数组的 length 属性并不会变小,数组元素变成undefined
- (2)当用 delete 操作符删除一个数组元素时,被删除的元素已经完全不属于该数组。
- (3)如果你想让一个数组元素的值变为 undefined 而不是删除它,可以使用 undefined 给其赋值而不是使用 delete 操作符。此时数组元素是在数组中的
- delete 操作符与直接释放内存(只能通过解除引用来间接释放)没有关系。
AMD和CMD规范区别
- AMD规范:是 RequireJS在推广过程中对模块定义的规范化产出的
- CMD规范:是SeaJS 在推广过程中对模块定义的规范化产出的
- CMD 推崇依赖就近;AMD 推崇依赖前置
- CMD 是延迟执行;AMD 是提前执行
- CMD性能好,因为只有用户需要的时候才执行;AMD用户体验好,因为没有延迟,依赖模块提前执行了
SPA单页页面
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
SPA优点
- 用户体验好、快,内容的改变不需要重新加载整个页面,避免了不必要的跳转和重复渲染;
- 基于上面一点,SPA 相对对服务器压力小;
- 前后端职责分离,架构清晰,前端进行交互逻辑,后端负责数据处理;
SPA缺点
- 初次加载耗时多:为实现单页 Web 应用功能及显示效果,需要在加载页面的时候将 JavaScript、CSS 统一加载,部分页面按需加载;
- 前进后退路由管理:由于单页应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理;
- SEO 难度较大:由于所有的内容都在一个页面中动态替换显示,所以在 SEO 上其有着天然的弱势。
Vue.js虚拟DOM的优缺点
1)优点
- 保证性能下限: 框架的虚拟 DOM 需要适配任何上层 API 可能产生的操作,它的一些 DOM 操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的 DOM 操作性能要好很多,因此框架的虚拟 DOM 至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限;
- 无需手动操作 DOM: 我们不再需要手动去操作 DOM,只需要写好 View-Model 的代码逻辑,框架会根据虚拟 DOM 和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率;
- 跨平台: 虚拟 DOM 本质上是 JavaScript 对象,而 DOM 与平台强相关,相比之下虚拟 DOM 可以进行更方便地跨平台操作,例如服务器渲染、weex 开发等等。
2)缺点
- 无法进行极致优化: 虽然虚拟 DOM + 合理的优化,足以应对绝大部分应用的性能需求,但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化。比如VScode采用直接手动操作DOM的方式进行极端的性能优化
Node 中怎么开启一个子线程
work_thread
Node 10.5.0 的发布,work_thread 让 Node 有了真正的多线程能力,worker_thread 模块中有 4 个对象和 2 个类
- isMainThread: 是否是主线程,源码中是通过 threadId === 0 进行判断的。
- MessagePort: 用于线程之间的通信,继承自 EventEmitter。
- MessageChannel: 用于创建异步、双向通信的通道实例。
- threadId: 线程 ID。
- Worker: 用于在主线程中创建子线程。第一个参数为 filename,表示子线程执行的入口。
- parentPort: 在 worker 线程里是表示父进程的 MessagePort 类型的对象,在主线程里为 null
- workerData: 用于在主进程中向子进程传递数据(data 副本)
在主线程中开启五个子线程,并且主线程向子线程发送简单的消息示例代码如下:
1 | const { |
CSS预处理器和Less有什么好处
CSS预处理器
为css增加编程特性的拓展语言,可以使用变量,简单逻辑判断,函数等基本编程技巧。
css预处理器编译输出还是标准的css样式。
less, sass都是动态的样式语言,是css预处理器,css上的一种抽象层。他们是一种特殊的语法语言而编译成css的。
less变量符号是@,sass变量符号是$。
预处理器解决了哪些痛点
css语法不够强大。因为无法嵌套导致有很多重复的选择器 没有变量和合理的样式利用机制,导致逻辑上相关的属性值只能以字面量的形式重复输出,难以维护。
常用规范
变量,嵌套语法,混入,@import,运算,函数,继承
好处
比css代码更加整洁,更易维护,代码量更少 修改更快。
基础颜色使用变量,一处动,处处动。
常用的代码使用代码块,节省大量代码。
css嵌套减少大量的重复选择器,避免一些低级错误。
变量混入大大提升了样式的利用性 额外的工具类似颜色函数(lighten,darken,transparentize),mixins,loops等这些方法使css更像一个真正的编程语言,让开发者能够有能力生成更加复杂的css样式。
Sass
Sass (英文全称:Syntactically Awesome Stylesheets) 是一个最初由 Hampton Catlin 设计并由 Natalie Weizenbaum 开发的层叠样式表语言。
Sass 是一个 CSS 预处理器。
Sass 是 CSS 扩展语言,可以帮助我们减少 CSS 重复的代码,节省开发时间。
Sass 完全兼容所有版本的 CSS。
Sass 扩展了 CSS3,增加了规则、变量、混入、选择器、继承、内置函数等等特性。
Sass 生成良好格式化的 CSS 代码,易于组织和维护。
Sass 文件后缀为 .scss。
浏览器并不支持 Sass 代码。因此,你需要使用一个 Sass 预处理器将 Sass 代码转换为 CSS 代码。
什么是 React?
React 是一个开源前端 JavaScript 库,用于构建用户界面,尤其是单页应用程序。它用于处理网页和移动应用程序的视图层。React 是由 Facebook 的软件工程师 Jordan Walke 创建的。在 2011 年 React 应用首次被部署到 Facebook 的信息流中,之后于 2012 年被应用到 Instagram 上。
React 的主要特点是什么?
- 考虑到真实的 DOM 操作成本很高,它使用 VirtualDOM 而不是真实的 DOM。
- 支持服务端渲染。
- 遵循单向数据流或数据绑定。
- 使用可复用/可组合的 UI 组件开发视图。
react 最新版本解决了什么问题 加了哪些东西
1)React 16.x的三大新特性 Time Slicing, Suspense,hooks
- Time Slicing(解决CPU速度问题)使得在执行任务的期间可以随时暂停,跑去干别的事情,这个特性使得react能在性能极其差的机器跑时,仍然保持有良好的性能
- Suspense (解决网络IO问题)和lazy配合,实现异步加载组件。 能暂停当前组件的渲染, 当完成某件事以后再继续渲染,解决从react出生到现在都存在的「异步副作用」的问题,而且解决得非常的优雅,使用的是「异步但是同步的写法」,我个人认为,这是最好的解决异步问题的方式
- 此外,还提供了一个内置函数 componentDidCatch,当有错误发生时, 我们可以友好地展示 fallback 组件;可以捕捉到它的子元素(包括嵌套子元素)抛出的异常;可以复用错误组件。
2)React16.8
- 加入hooks,让React函数式组件更加灵活
- hooks之前,React存在很多问题
- 在组件间复用状态逻辑很难
- 复杂组件变得难以理解,高阶组件和函数组件的嵌套过深。
- class组件的this指向问题
- 难以记忆的生命周期
- hooks很好的解决了上述问题,hooks提供了很多方法
- useState 返回有状态值,以及更新这个状态值的函数
- useEffect 接受包含命令式,可能有副作用代码的函数。
- useContext 接受上下文对象(从React.createContext返回的值)并返回当前上下文值,
- useReducer useState的替代方案。接受类型为(state,action) => newState的reducer,并返回与dispatch方法配对的当前状态。
- useCallback 返回一个回忆的memoized版本,该版本仅在其中一个输入发生更改时才会更改。纯函数的输入输出确定性
- useMemo 纯的一个记忆函数
- useRef 返回一个可变的ref对象,其.current属性被初始化为传递的参数,返回的 ref 对象在组件的整个生命周期内保持不变。
- useImperativeMethods 自定义使用ref时公开给父组件的实例值
- useMutationEffect 更新兄弟组件之前,它在React执行其DOM改变的同一阶段同步触发
- useLayoutEffect DOM改变后同步触发。使用它来从DOM读取布局并同步重新渲染
3)React16.9
- 重命名 Unsafe 的生命周期方法。新的 UNSAFE_ 前缀将有助于在代码 review 和 debug 期间,使这些有问题的字样更突出
- 废弃 javascript: 形式的 URL。以 javascript: 开头的 URL 非常容易遭受攻击,造成安全漏洞。
- 废弃 “Factory” 组件。 工厂组件会导致 React 变大且变慢。
- act() 也支持异步函数,并且你可以在调用它时使用 await。
- 使用
<React.Profiler>进行性能评估。 在较大的应用中追踪性能回归可能会很方便
4)React16.13.0
- 支持在渲染期间调用setState,但仅适用于同一组件
- 可检测冲突的样式规则并记录警告
- 废弃unstable_createPortal,使用createPortal
- 将组件堆栈添加到其开发警告中,使开发人员能够隔离bug并调试其程序,这可以清楚地说明问题所在,并更快地定位和修复错误。
什么是 JSX?
JSX 是 ECMAScript 一个类似 XML 的语法扩展。基本上,它只是为 React.createElement() 函数提供语法糖,从而让在我们在 JavaScript 中,使用类 HTML 模板的语法,进行页面描述。
什么是 Pure Components?
React.PureComponent 与 React.Component 完全相同,只是它为你处理了 shouldComponentUpdate() 方法。当属性或状态发生变化时,PureComponent 将对属性和状态进行浅比较。另一方面,一般的组件不会将当前的属性和状态与新的属性和状态进行比较。因此,在默认情况下,每当调用 shouldComponentUpdate 时,默认返回 true,所以组件都将重新渲染。
状态和属性有什么区别?
state 和 props 都是普通的 JavaScript 对象。虽然它们都保存着影响渲染输出的信息,但它们在组件方面的功能不同。Props 以类似于函数参数的方式传递给组件,而状态则类似于在函数内声明变量并对它进行管理。
States vs Props
| Conditions | States | Props |
|---|---|---|
| 可从父组件接收初始值 | 是 | 是 |
| 可在父组件中改变其值 | 否 | 是 |
| 在组件内设置默认值 | 是 | 是 |
| 在组件内可改变 | 是 | 否 |
| 可作为子组件的初始值 | 是 | 是 |
我们为什么不能直接更新状态?
如果你尝试直接改变状态,那么组件将不会重新渲染。
1 | //Wrong |
正确方法应该是使用 setState() 方法。它调度组件状态对象的更新。当状态更改时,组件通将会重新渲染。
1 | //Correct |
注意: 你可以在 constructor 中或使用最新的 JavaScript 类属性声明语法直接设置状态对象。
另在React文档中,提到永远不要直接更改this.state,而是使用this.setState进行状态更新,这样做的两个主要原因如下:
setState分批工作:这意味着不能期望setState立即进行状态更新,这是一个异步操作,因此状态更改可能在以后的时间点发生,这意味着手动更改状态可能会被setState覆盖。
性能:当使用纯组件或shouldComponentUpdate时,它们将使用===运算符进行浅表比较,但是如果更改状态,则对象引用将仍然相同,因此比较将失败。
注意: 为了避免避免数组/对象突变,可使用以下方法:
- 使用slice
- 使用Object.assign
- 在ES6中使用Spread operator
- 嵌套对象
为什么 String Refs 被弃用?
如果你以前使用过 React,你可能会熟悉旧的 API,其中的 ref 属性是字符串,如 ref={'textInput'},并且 DOM 节点的访问方式为this.refs.textInput。我们建议不要这样做,因为字符串引用有以下问题,并且被认为是遗留问题。字符串 refs 在 React v16 版本中被移除。
由于它无法知道this,所以需要React去跟踪当前渲染的组件。这使得React变得比较慢。
如果一个库在传递的子组件(子元素)上放置了一个ref,那用户就无法在它上面再放一个ref了。但函数式可以实现这种组合。
它们不能与静态分析工具一起使用,如 Flow。Flow 无法猜测出 this.refs 上的字符串引用的作用及其类型。Callback refs 对静态分析更友好。
下述例子中,string类型的refs写法会让ref被放置在DataTable组件中,而不是MyComponent中。
1 | class MyComponent extends Component { |
什么是 Virtual DOM?
Virtual DOM (VDOM) 是 Real DOM 的内存表示形式。UI 的展示形式被保存在内存中并与真实的 DOM 同步。这是在调用的渲染函数和在屏幕上显示元素之间发生的一个步骤。整个过程被称为 reconciliation。
Real DOM vs Virtual DOM
| Real DOM | Virtual DOM |
|---|---|
| 更新较慢 | 更新较快 |
| 可以直接更新 HTML | 无法直接更新 HTML |
| 如果元素更新,则创建新的 DOM | 如果元素更新,则更新 JSX |
| DOM 操作非常昂贵 | DOM 操作非常简单 |
| 较多的内存浪费 | 没有内存浪费 |
Virtual DOM 如何工作?
Virtual DOM 分为三个简单的步骤。
每当任何底层数据发生更改时,整个 UI 都将以 Virtual DOM 的形式重新渲染。
然后计算先前 Virtual DOM 对象和新的 Virtual DOM 对象之间的差异。
一旦计算完成,真实的 DOM 将只更新实际更改的内容。
为什么虚拟dom会提高性能
虚拟dom相当于在js和真实dom中间加了一个缓存,利用dom diff算法避免了没有必要的dom操作,从而提高性能
具体实现步骤如下
- 用 JavaScript 对象结构表示 DOM 树的结构;然后用这个树构建一个真正的 DOM 树,插到文档当中
- 当状态变更的时候,重新构造一棵新的对象树。然后用新的树和旧的树进行比较,记录两棵树差异
- 把2所记录的差异应用到步骤1所构建的真正的DOM树上,视图就更新
react diff 原理(常考,大厂必考)
- 把树形结构按照层级分解,只比较同级元素。
- 给列表结构的每个单元添加唯一的 key 属性,方便比较。
- React 只会匹配相同 class 的 component(这里面的 class 指的是组件的名字)
- 合并操作,调用 component 的 setState 方法的时候, React 将其标记为 dirty. 到每一个事件循环结束, React 检查所有标记 dirty 的 component 重新绘制.
- 选择性子树渲染。开发人员可以重写 shouldComponentUpdate 提高 diff 的性能。
React Fiber架构中,迭代器和requestIdleCallback结合的优势
requestIdleCallback API
requestIdleCallback 是浏览器提供的 Web API,它是 React Fiber 中用到的核心 API。
API 介绍
requestIdleCallback 利用浏览器的空余时间执行任务,如果浏览器没有空余时间,可以随时终止这些任务。
这样可以实现如果有更高优先级的任务要执行时,当前执行的任务可以被终止,优先执行高级别的任务。
原理是该方法将 在浏览器的空闲时段内调用的函数 排队。
这样使得开发者能够在主事件循环上 执行后台和低优先级的任务,而不会影响 像动画和用户交互 这些关键的延迟触发的事件。
这里的“延迟”指的是大量计算导致运行时间较长。
浏览器空余时间
页面是一帧一帧绘制出来的,当每秒绘制的帧数达到 60 时,页面时流畅的,小于这个值时,用户会感觉到卡顿。
1秒60帧意思是1秒中60张画面在切换。
当帧数低于人眼的捕捉频率(有说24帧或30帧,考虑到视觉残留现象,这个数值可能会更低)时,人脑会识别这是几张图片在切换,也就是静态的。
当帧数高于人眼的捕捉频率,人脑会认为画面是连续的,也就是动态的动画。
帧数越高画面就看起来更流畅。
1秒60帧(大约 1000/60 ≈ 16ms 切换一个画面)差不多是人眼能识别卡顿的分界线。
如果每一帧执行的时间小于 16 ms,就说明浏览器有空余时间。
一帧时间内浏览器要做的事情包括:脚本执行、样式计算、布局、重绘、合成等。
如果某一项内容执行时间过长,浏览器会推迟渲染,造成丢帧卡顿,就没有剩余时间。
应用场景
比如现在有一项计算任务,这项任务需要花费比较长的时间(例如超过16ms)去执行。
在执行任务的过程当中,浏览器的主线程会被一直占用。
在主线程被占用的过程中,浏览器是被阻塞的,并不能执行其他的任务。
如果此时用户想要操作页面,比如向下滑动页面查看其它内容,浏览器是不能响应用户的操作的,给用户的感觉就是页面卡死了,体验非常差。
如何解决呢?
可以将这项任务注册到 requestIdleCallback 中,利用浏览器的空余时间执行它。
当用户操作页面时,就是优先级比较高的任务被执行时,此时计算任务会被终止,优先响应用户的操作,这样用户就不会感觉页面发生卡顿了。
当高优先级的任务执行完成后,再继续执行计算任务。
requestIdleCallback 的作用就是利用浏览器的空余时间执行这些需要大量计算的任务,当空余时间结束,会中断计算任务,执行高优先级的任务,以达到不阻塞主线程任务(例如浏览器 UI 渲染)的目的。
使用方式
1 | var handle = window.requestIdleCallback(callback[, options]) |
- callback:一个在空闲时间即将被调用的回调函数
- 该函数接收一个形参:IdleDeadline,它提供一个方法和一个属性:
- 方法:timeRemaining()
- 用于获取浏览器空闲期的剩余时间,也就是空余时间
- 返回值是毫秒数
- 如果闲置期结束,则返回 0
- 根据时间的多少可以来决定是否要执行任务
- 用于获取浏览器空闲期的剩余时间,也就是空余时间
- 属性:didTimeout(Boolean,只读)
- 表示是否是上一次空闲期因为超时而没有执行的回调函数
- 超时时间由 requestIdleCallback 的参数options.timeout 定义
- 方法:timeRemaining()
- 该函数接收一个形参:IdleDeadline,它提供一个方法和一个属性:
- options:可选配置,目前只有一个配置项
- timeout:超时时间,如果设置了超时时间并超时,回调函数还没有被调用,则会在下一次空闲期强制被调用
功能体验
页面中有两个按钮和一个 DIV,点击第一个按钮执行一项昂贵的计算,使其长期占用主线程,当计算任务执行的时候去点击第二个按钮更改页面中 DIV 的背景颜色。
1 |
|

使用 requestIdleCallback可以完美解决这个卡顿问题:
1 |
|

- 浏览器在空余时间执行 calc 函数
- 当空余时间小于 1ms 时,跳出while循环
- calc 根据 number 判断计算任务是否执行完成,如果没有完成,则继续注册新的空闲期的任务
- 当 btn2 点击事件触发,会等到当前空闲期任务执行完后执行“更改背景颜色”的任务
- “更改背景颜色”任务执行完成后,继续进入空闲期,执行后面的任务
由此可见,所谓执行优先级更高的任务,是手动将计算任务拆分到浏览器的空闲期,以实现每次进入空闲期之前优先执行主线程的任务。
Fiber 出现的目的
Fiber 其实是 React 16 新的 DOM 比对算法的名字,旧的 DOM 比对算法的名字是 Stack。
React 16之前的版本存在的问题
React 16之前的版本对比更新 VirtualDOM 的过程是采用循环加递归实现的。
这种对比方式有一个问题,就是一旦任务开始进行就无法中断(由于递归需要一层一层的进入,一层一层的退出,所以过程不能中断)。
如果应用中组件数量庞大,主线程被长期占用,直到整棵 VirtualDOM 树对比更新完成之后主线程才能被释放,主线程才能执行其它任务。
这就会导致一些用户交互、动画等任务无法立即得到执行,页面就会产生卡顿,非常影响用户的体验。
因为递归利用的 JavaScript 自身的执行栈,所以旧版 DOM 比对的算法称为 **Stack(堆栈)**。
核心问题:递归无法中断,执行重任务耗时长,JavaScript 又是单线程的,无法同时执行其它任务,导致在绘制页面的过程当中不能执行其它任务,比如元素动画、用户交互等任务必须延后,给用户的感觉就是页面变得卡顿,用户体验差。
Stack 算法模拟
模拟 React 16 之前将虚拟 DOM 转化成真实 DOM 的递归算法:
1 | // 要渲染的 jsx |
jsx 会被 Babel 转化成 React.createElement() 的调用,最终返回一个虚拟 DOM 对象:
1 | ; |
去掉一些属性,打印结果:
1 | const jsx = { |
递归转化真实 DOM:
1 | const jsx = {...} |
DOM 更新就是在上面递归的过程中加入了 Virtual DOM 对比的过程。
可以看到递归是无法中断的。
React 16 解决方案 - Fiber
- 利用浏览器空余时间执行任务,拒绝长时间占用主线程
- 在新版本的 React 版本中,使用了 requestIdleCallback API
- 利用浏览器空余时间执行 VirtualDOM 比对任务,也就表示 VirtualDOM 比对不会长期占用主线程
- 如果有高优先级的任务要执行,就会暂时终止 VirtualDOM 的比对过程,先去执行高优先级的任务
- 高优先级任务执行完成,再回来继续执行 VirtualDOM 比对任务
- 这样页面就不会出现卡顿现象
- 放弃递归,只采用循环,因为循环可以被中断
- 由于递归必须一层一层进入,一层一层退出,所以过程无法中断
- 所以要实现任务的终止再继续,就必须放弃递归,只采用循环的方式执行比对的过程
- 因为循环是可以终止的,只需要将循环的条件保存下来,下一次任务就可以从中断的地方执行了
- 任务拆分,将任务拆分成一个个的小任务
- 如果任务要实现终止再继续,任务的单元就必须要小
- 这样任务即使没有执行完就被终止,重新执行任务的代价就会小很多
- 所以要进行任务的拆分,将一个大的任务拆分成一个个小的任务
- VirtualDOM 比对任务如何拆分?
- 以前将整棵 VirtualDOM 树的比对看作一个任务
- 现在将树中每一个节点的比对看作一个任务
新版 React 的解决方案核心就是第 1 点,第 2、3 点都是为了实现第 1 点而存在的,
Fiber 翻译过来是“纤维”,意思就是执行任务的颗粒度变得细腻,像纤维一样。
可以通过这个 Demo 查看 Stack 算法 和 Fiber 算法的效果区别。
实现思路
在 Fiber 方案中,为了实现任务的终止再继续,DOM 对比算法被拆分成了两阶段:
- render 阶段(可中断)
- VirtualDOM 的比对,构建 Fiber 对象,构建链表
- commit 阶段(不可中断)
- 根据构建的链表进行 DOM 操作
过程就是:
- 在使用 React 编写用户界面的时候仍然使用 JSX 语法
- Babel 会将 JSX 语法转换成
React.createElement()方法的调用 React.createElement()方法调用后会返回 VirtualDOM 对象- 接下来就可以执行第一个阶段了:构建 Fiber 对象
- 采用循环的方式从 VirtualDOM 对象中,找到每一个内部的 VirtualDOM 对象
- 为每一个 VirtualDOM 对象构建 Fiber 对象
- Fiber 对象也是 JavaScript 对象,它是从 VirtualDOM 对象衍化来的,它除了 type、props、children以外还存储了更多节点的信息,其中包含的一个核心信息是:当前节点要进行的操作,例如删除、更新、新增
- 在构建 Fiber 的过程中还要构建链表
- 接着进行第二阶段的操作:执行 DOM 操作
总结:
- DOM 初始渲染:
根据 VirtualDOM–>创建 Fiber 对象 及 构建链表–>将 Fiber 对象存储的操作应用到真实 DOM 中 - DOM 更新操作:
newFiber(重新获取所有 Fiber 对象)–>newFiber vs oldFiber(获取旧的 Fiber 对象,进行比对) 将差异操作追加到链表–>将 Fiber 对象应用到真实 DOM 中
什么是 Fiber
Fiber 有两层含义:
- Fiber 是一个执行单元
- Fiber 是一种数据结构
执行单元
在 React 16 之前,将 Virtual DOM 树整体看成一个任务进行递归处理,任务整体庞大执行耗时且不能中断。
在 React 16,将整个任务拆分成一个个小的任务进行处理,每个小的任务指的就是一个 Fiber 节点的构建。
任务会在浏览器的空闲时间被执行,每个单元执行完成后,React 都会检查是否还有空余时间,如果有继续执行下一个人物单元,直到没有空余时间或者所有任务执行完毕,如果没有空余时间就交还主线程的控制权。

数据结构
Fiber 是一种数据结构,支撑 React 构建任务的运转。
Fiber 其实就是 JavaScript 对象,对象中存储了当前节点的父节点、第一个子节点、下一个兄弟节点,以便在构建链表和执行 DOM 操作的时候知道它们的关系。
在 render 阶段的时候,React 会从上(root)向下,再从下向上构建所有节点对应的 Fiber 对象,在从下向上的同时还会构建链表,最后将链头存储到 Root Fiber。
从上向下
- 从 Root 节点开始构建,优先构建子节点
从下向上
- 如果当前节点没有子节点,就会构建下一个兄弟节点
- 如果当前节点没有子节点,也没有下一个兄弟节点,就会返回父节点,构建父节点的兄弟节点
- 如果父节点的下一个兄弟节点有子节点,就继续向下构建
- 如果父节点没有下一个兄弟节点,就继续向上查找
在第二阶段的时候,通过链表结构的属性(child、sibling、parent)准确构建出完整的 DOM 节点树,从而才能将 DOM 对象追加到页面当中。
1 | // Fiber 对象 |
以上面的示例为例:
1 | <div id="a1"> |

1 | // B1 的 Fiber 对象包含这几个属性: |
说一下 react-fiber
1)背景
- react在进行组件渲染时,从setState开始到渲染完成整个过程是同步的(“一气呵成”)。如果需要渲染的组件比较庞大,js执行会占据主线程时间较长,会导致页面响应度变差,使得react在动画、手势等应用中效果比较差。
- 页面卡顿:Stack reconciler的工作流程很像函数的调用过程。父组件里调子组件,可以类比为函数的递归;对于特别庞大的vDOM树来说,reconciliation过程会很长(x00ms),超过16ms,在这期间,主线程是被js占用的,因此任何交互、布局、渲染都会停止,给用户的感觉就是页面被卡住了。
2)实现原理
旧版 React 通过递归的方式进行渲染,使用的是 JS 引擎自身的函数调用栈,它会一直执行到栈空为止。而Fiber实现了自己的组件调用栈,它以链表的形式遍历组件树,可以灵活的暂停、继续和丢弃执行的任务。实现方式是使用了浏览器的requestIdleCallback这一 API。
Fiber 其实指的是一种数据结构,它可以用一个纯 JS 对象来表示:
1 | const fiber = { |
react内部运转分三层:
- Virtual DOM 层,描述页面长什么样。
- Reconciler 层,负责调用组件生命周期方法,进行 Diff 运算等。
- Renderer 层,根据不同的平台,渲染出相应的页面,比较常见的是 ReactDOM 和 ReactNative。
为了实现不卡顿,就需要有一个调度器 (Scheduler) 来进行任务分配。优先级高的任务(如键盘输入)可以打断优先级低的任务(如Diff)的执行,从而更快的生效。任务的优先级有六种:
- synchronous,与之前的Stack Reconciler操作一样,同步执行
- task,在next tick之前执行
- animation,下一帧之前执行
- high,在不久的将来立即执行
- low,稍微延迟执行也没关系
- offscreen,下一次render时或scroll时才执行
Fiber Reconciler(react )执行阶段:
- 阶段一,生成 Fiber 树,得出需要更新的节点信息。这一步是一个渐进的过程,可以被打断。
- 阶段二,将需要更新的节点一次过批量更新,这个过程不能被打断。
Fiber树:React 在 render 第一次渲染时,会通过 React.createElement 创建一颗 Element 树,可以称之为 Virtual DOM Tree,由于要记录上下文信息,加入了 Fiber,每一个 Element 会对应一个 Fiber Node,将 Fiber Node 链接起来的结构成为 Fiber Tree。Fiber Tree 一个重要的特点是链表结构,将递归遍历编程循环遍历,然后配合 requestIdleCallback API, 实现任务拆分、中断与恢复。
从Stack Reconciler到Fiber Reconciler,源码层面其实就是干了一件递归改循环的事情
展示组件(Presentational component)和容器组件(Container component)之间有何区别?
展示组件关心组件看起来是什么。展示专门通过 props 接受数据和回调,并且几乎不会有自身的状态,但当展示组件拥有自身的状态时,通常也只关心 UI 状态而不是数据的状态。
容器组件则更关心组件是如何运作的。容器组件会为展示组件或者其它容器组件提供数据和行为(behavior),它们会调用 Flux actions,并将其作为回调提供给展示组件。容器组件经常是有状态的,因为它们是(其它组件的)数据源。
类组件(Class component)和 函数式组件(Functional component)之间有何区别?
函数式组件比类组件操作简单,只是简单的调取和返回 JSX;而类组件可以使用生命周期函数来操作业务
函数式组件可以理解为静态组件(组件中的内容调取的时候已经固定了,很难再修改),而类组件,可以基于组件内部的状态来动态更新渲染的内容
类组件不仅允许你使用更多额外的功能,如组件自身的状态和生命周期钩子,也能使组件直接访问 store 并维持状态
当组件仅是接收 props,并将组件自身渲染到页面时,该组件就是一个 ‘无状态组件(stateless component)’,可以使用一个纯函数来创建这样的组件。这种组件也被称为哑组件(dumb components)或展示组件
功能组件(Functional Component)与类组件(Class Component)如何选择?
如果您的组件具有状态( state ) 或 生命周期方法,请使用 Class 组件。否则,使用功能组件
解析:
React中有两种组件:函数组件(Functional Components) 和类组件(Class Components)。据我观察,大部分同学都习惯于用类组件,而很少会主动写函数组件,包括我自己也是这样。但实际上,在使用场景和功能实现上,这两类组件是有很大区别的。
来看一个函数组件的例子:
1 | function Welcome = (props) => { |
把上面的函数组件改写成类组件:
1 | import React from 'react' |
下面让我们来分析一下两种实现的区别:
第一眼直观的区别是,函数组件的代码量比类组件要少一些,所以函数组件比类组件更加简洁。千万不要小看这一点,对于我们追求极致的程序员来说,这依然是不可忽视的。
函数组件看似只是一个返回值是DOM结构的函数,其实它的背后是无状态组件(Stateless Components)的思想。函数组件中,你无法使用State,也无法使用组件的生命周期方法,这就决定了函数组件都是展示性组件(Presentational Components),接收Props,渲染DOM,而不关注其他逻辑。
函数组件中没有this。所以你再也不需要考虑this带来的烦恼。而在类组件中,你依然要记得绑定this这个琐碎的事情。如示例中的sayHi。
函数组件更容易理解。当你看到一个函数组件时,你就知道它的功能只是接收属性,渲染页面,它不执行与UI无关的逻辑处理,它只是一个纯函数。而不用在意它返回的DOM结构有多复杂。
性能。目前React还是会把函数组件在内部转换成类组件,所以使用函数组件和使用类组件在性能上并无大的差异。但是,React官方已承诺,未来将会优化函数组件的性能,因为函数组件不需要考虑组件状态和组件生命周期方法中的各种比较校验,所以有很大的性能提升空间。
函数组件迫使你思考最佳实践。这是最重要的一点。组件的主要职责是UI渲染,理想情况下,所有的组件都是展示性组件,每个页面都是由这些展示性组件组合而成。如果一个组件是函数组件,那么它当然满足这个要求。所以牢记函数组件的概念,可以让你在写组件时,先思考这个组件应不应该是展示性组件。更多的展示性组件意味着更多的组件有更简洁的结构,更多的组件能被更好的复用。
所以,当你下次在动手写组件时,一定不要忽略了函数组件,应该尽可能多地使用函数组件。
createElement 和 cloneElement 有什么区别?
传入的第一个参数不同
React.createElement(): JSX 语法就是用 React.createElement()来构建 React 元素的。它接受三个参数,第一个参数可以是一个标签名。如 div、span,或者 React 组件。第二个参数为传入的属性。第三个以及之后的参数,皆作为组件的子组件。
1 | React.createElement(type, [props], [...children]); |
React.cloneElement()与 React.createElement()相似,不同的是它传入的第一个参数是一个 React 元素,而不是标签名或组件。新添加的属性会并入原有的属性,传入到返回的新元素中,而旧的子元素将被替换。将保留原始元素的键和引用。
1 | React.cloneElement(element, [props], [...children]); |
描述事件在 React 中的处理方式
为了解决跨浏览器兼容性问题,您的 React 中的事件处理程序将传递 SyntheticEvent 的实例,它是 React 的浏览器本机事件的跨浏览器包装器。
这些 SyntheticEvent 与您习惯的原生事件具有相同的接口,除了它们在所有浏览器中都兼容。有趣的是,React 实际上并没有将事件附加到子节点本身。React 将使用单个事件监听器监听顶层的所有事件。这对于性能是有好处的,这也意味着在更新 DOM 时,React 不需要担心跟踪事件监听器。
React 中支持哪些指针事件?
Pointer Events 提供了处理所有输入事件的统一方法。在过去,我们有一个鼠标和相应的事件监听器来处理它们,但现在我们有许多与鼠标无关的设备,比如带触摸屏的手机或笔。我们需要记住,这些事件只能在支持 Pointer Events 规范的浏览器中工作。
目前以下事件类型在 React DOM 中是可用的:
- onPointerDown
- onPointerMove
- onPointerUp
- onPointerCancel
- onGotPointerCapture
- onLostPointerCaptur
- onPointerEnter
- onPointerLeave
- onPointerOver
- onPointerOut
React 事件绑定原理
React并不是将click事件绑在该div的真实DOM上,而是在document处监听所有支持的事件,当事件发生并冒泡至document处时,React将事件内容封装并交由真正的处理函数运行。这样的方式不仅减少了内存消耗,还能在组件挂载销毁时统一订阅和移除事件。
另外冒泡到 document 上的事件也不是原生浏览器事件,而是 React 自己实现的合成事件(SyntheticEvent)。因此我们如果不想要事件冒泡的话,调用 event.stopPropagation 是无效的,而应该调用 event.preventDefault。

1)事件注册

- 组件装载 / 更新。
- 通过lastProps、nextProps判断是否新增、删除事件分别调用事件注册、卸载方法。
- 调用EventPluginHub的enqueuePutListener进行事件存储
- 获取document对象。
- 根据事件名称(如onClick、onCaptureClick)判断是进行冒泡还是捕获。
- 判断是否存在addEventListener方法,否则使用attachEvent(兼容IE)。
- 给document注册原生事件回调为dispatchEvent(统一的事件分发机制)。
2)事件存储

- EventPluginHub负责管理React合成事件的callback,它将callback存储在listenerBank中,另外还存储了负责合成事件的Plugin。
- EventPluginHub的putListener方法是向存储容器中增加一个listener。
- 获取绑定事件的元素的唯一标识key。
- 将callback根据事件类型,元素的唯一标识key存储在listenerBank中。
- listenerBank的结构是:listenerBank[registrationName][key]。
1 | { |
3)事件触发执行

- 触发document注册原生事件的回调dispatchEvent
- 获取到触发这个事件最深一级的元素
这里的事件执行利用了React的批处理机制
代码示例
1 | <div onClick={this.parentClick} ref={ref => this.parent = ref}> |
- 首先会获取到this.child
- 遍历这个元素的所有父元素,依次对每一级元素进行处理。
- 构造合成事件。
- 将每一级的合成事件存储在eventQueue事件队列中。
- 遍历eventQueue。
- 通过isPropagationStopped判断当前事件是否执行了阻止冒泡方法。
- 如果阻止了冒泡,停止遍历,否则通过executeDispatch执行合成事件。
- 释放处理完成的事件。
4)合成事件

- 调用EventPluginHub的extractEvents方法。
- 循环所有类型的EventPlugin(用来处理不同事件的工具方法)。
- 在每个EventPlugin中根据不同的事件类型,返回不同的事件池。
- 在事件池中取出合成事件,如果事件池是空的,那么创建一个新的。
- 根据元素nodeid(唯一标识key)和事件类型从listenerBink中取出回调函数
- 返回带有合成事件参数的回调函数
5)总流程

什么是 hooks?
Hooks 是一个新的草案,它允许你在不编写类的情况下使用状态和其他 React 特性。
Hooks 需要遵循什么规则?
为了使用 hooks,你需要遵守两个规则:
- 仅在顶层的 React 函数调用 hooks。也就是说,你不能在循环、条件或内嵌函数中调用 hooks。这将确保每次组件渲染时都以相同的顺序调用 hooks,并且它会在多个 useState 和 useEffect 调用之间保留 hooks 的状态。
- 仅在 React 函数中调用 hooks。例如,你不能在常规的 JavaScript 函数中调用 hooks。
React memo 函数是什么?
当类组件的输入属性相同时,可以使用 pureComponent 或 shouldComponentUpdate 来避免组件的渲染。现在,你可以通过把函数组件包装在 React.memo 中来实现相同的功能。
1 | const MyComponent = React.memo(function MyComponent(props) { |
React lazy 函数是什么?
使用 React.lazy 函数允许你将动态导入的组件作为常规组件进行渲染。当组件开始渲染时,它会自动加载包含对应组件的包。它必须返回一个 Promise,该 Promise 解析后为一个带有默认导出 React 组件的模块。
注意: React.lazy 和 Suspense 还不能用于服务端渲染。如果要在服务端渲染的应用程序中进行代码拆分,我们仍然建议使用 React Loadable。
什么是 Flow?
Flow 是一个静态类型检查器,旨在查找 JavaScript 中的类型错误。与传统类型系统相比,Flow 类型可以表达更细粒度的区别。例如,与大多数类型系统不同,Flow 能帮助你捕获涉及 null 的错误。
Flow 和 PropTypes 有什么区别?
Flow 是一个静态类型检查器(静态检查器),它使用该语言的超集,允许你在所有代码中添加类型注释,并在编译时捕获整个类的错误。
PropTypes 是一个基本类型检查器(运行时检查器),已经被添加到 React 中。除了检查传递给给定组件的属性类型外,它不能检查其他任何内容。
如果你希望对整个项目进行更灵活的类型检查,那么 Flow/TypeScript 是更合适的选择。
React Native 和 React 有什么区别?
React是一个 JavaScript 库,支持前端 Web 和在服务器上运行,用于构建用户界面和 Web 应用程序。
React Native是一个移动端框架,可编译为本机应用程序组件,允许您使用 JavaScript 构建本机移动应用程序(iOS,Android和Windows),允许您使用 React 构建组件。
MVW 模式的缺点是什么?
- DOM 操作非常昂贵,导致应用程序行为缓慢且效率低下。
- 由于循环依赖性,围绕模型和视图创建了复杂的模型。
- 协作型应用程序(如Google Docs)会发生大量数据更改。
- 如果不添加太多额外代码就无法轻松撤消(及时回退)。
什么是 Jest?
Jest是一个由 Facebook 基于 Jasmine 创建的 JavaScript 单元测试框架,提供自动模拟依赖项和jsdom环境。它通常用于测试组件。
Jest 对比 Jasmine 有什么优势?
与 Jasmine 相比,有几个优点:
- 自动查找在源代码中要执行的测试。
- 在运行测试时自动模拟依赖项。
- 允许您同步测试异步代码。
- 通过 jsdom 使用假的 DOM 实现运行测试,以便可以在命令行上运行测试。
- 在并行流程中运行测试,以便更快完成。
什么是 React Router?
React Router 是一个基于 React 之上的强大路由库,可以帮助您快速地向应用添加视图和数据流,同时保持 UI 与 URL 同步。
什么是 React 流行的特定 linters?
ESLint 是一个流行的 JavaScript linter。有一些插件可以分析特定的代码样式。在 React 中最常见的一个是名为 eslint-plugin-react npm 包。默认情况下,它将使用规则检查许多最佳实践,检查内容从迭代器中的键到一组完整的 prop 类型。另一个流行的插件是 eslint-plugin-jsx-a11y,它将帮助修复可访问性的常见问题。由于 JSX 提供的语法与常规 HTML 略有不同,因此常规插件无法获取 alt 文本和 tabindex 的问题。
React 和 ReactDOM 之间有什么区别?
react 包中包含 React.createElement(), React.Component, React.Children,以及与元素和组件类相关的其他帮助程序。你可以将这些视为构建组件所需的同构或通用帮助程序。react-dom 包中包含了 ReactDOM.render(),在 react-dom/server 包中有支持服务端渲染的 ReactDOMServer.renderToString() 和 ReactDOMServer.renderToStaticMarkup() 方法。
为什么 ReactDOM 从 React 分离出来?
React 团队致力于将所有的与 DOM 相关的特性抽取到一个名为 ReactDOM 的独立库中。React v0.14 是第一个拆分后的版本。通过查看一些软件包,react-native,react-art,react-canvas,和 react-three,很明显,React 的优雅和本质与浏览器或 DOM 无关。为了构建更多 React 能应用的环境,React 团队计划将主要的 React 包拆分成两个:react 和 react-dom。这为编写可以在 React 和 React Native 的 Web 版本之间共享的组件铺平了道路。
是否可以在不调用 setState 方法的情况下,强制组件重新渲染?
默认情况下,当组件的状态或属性改变时,组件将重新渲染。如果你的 render() 方法依赖于其他数据,你可以通过调用 forceUpdate() 来告诉 React,当前组件需要重新渲染。
React 很多个 setState 为什么是执行完再 render
react为了提高整体的渲染性能,会将一次渲染周期中的state进行合并,在这个渲染周期中对所有setState的所有调用都会被合并起来之后,再一次性的渲染,这样可以避免频繁的调用setState导致频繁的操作dom,提高渲染性能。
具体的实现方面,可以简单的理解为react中存在一个状态变量isBatchingUpdates,当处于渲染周期开始时,这个变量会被设置成true,渲染周期结束时,会被设置成false,react会根据这个状态变量,当出在渲染周期中时,仅仅只是将当前的改变缓存起来,等到渲染周期结束时,再一次性的全部render。
如何在 React 中启用生产模式?
你应该使用 Webpack 的 DefinePlugin 方法将 NODE_ENV 设置为 production,通过它你可以去除 propType 验证和额外警告等内容。除此之外,如果你压缩代码,如使用 Uglify 的死代码消除,以去掉用于开发的代码和注释,它将大大减少包的大小。
React 的优点是什么?
- 使用 Virtual DOM 提高应用程序的性能。
- JSX 使代码易于读写。
- 它支持在客户端和服务端渲染。
- 易于与框架(Angular,Backbone)集成,因为它只是一个视图库。
- 使用 Jest 等工具轻松编写单元与集成测试。
React 优势
React 速度很快:它并不直接对 DOM 进行操作,引入了一个叫做虚拟 DOM 的概念,安插在 javascript 逻辑和实际的 DOM 之间,性能好。
跨浏览器兼容:虚拟 DOM 帮助我们解决了跨浏览器问题,它为我们提供了标准化的 API,甚至在 IE8 中都是没问题的。
一切都是 component:代码更加模块化,重用代码更容易,可维护性高。
单向数据流:Flux 是一个用于在 JavaScript 应用中创建单向数据层的架构,它随着 React 视图库的开发而被 Facebook 概念化。
同构、纯粹的 javascript:因为搜索引擎的爬虫程序依赖的是服务端响应而不是 JavaScript 的执行,预渲染你的应用有助于搜索引擎优化。
兼容性好:比如使用 RequireJS 来加载和打包,而 Browserify 和 Webpack 适用于构建大型应用。它们使得那些艰难的任务不再让人望而生畏。
React 的局限性是什么?
- React 只是一个视图库,而不是一个完整的框架。
- 对于 Web 开发初学者来说,有一个学习曲线。
- 将 React 集成到传统的 MVC 框架中需要一些额外的配置。
- 代码复杂性随着内联模板和 JSX 的增加而增加。
- 如果有太多的小组件可能增加项目的庞大和复杂。
react性能优化方案
- 重写
shouldComponentUpdate来避免不必要的dom操作 - 使用 production 版本的react.js
- 使用key来帮助React识别列表中所有子组件的最小变化
React 项目中有哪些细节可以优化?实际开发中都做过哪些性能优化
1)对于正常的项目优化,一般都涉及到几个方面,开发过程中、上线之后的首屏、运行过程的状态
来聊聊上线之后的首屏及运行状态:
首屏优化一般涉及到几个指标FP、FCP、FMP;要有一个良好的体验是尽可能的把FCP提前,需要做一些工程化的处理,去优化资源的加载
方式及分包策略,资源的减少是最有效的加快首屏打开的方式;
对于CSR的应用,FCP的过程一般是首先加载js与css资源,js在本地执行完成,然后加载数据回来,做内容初始化渲染,这中间就有几次的网络反复请求的过程;所以CSR可以考虑使用骨架屏及预渲染(部分结构预渲染)、suspence与lazy做懒加载动态组件的方式
当然还有另外一种方式就是SSR的方式,SSR对于首屏的优化有一定的优势,但是这种瓶颈一般在Node服务端的处理,建议使用stream流的方式来处理,对于体验与node端的内存管理等,都有优势;
不管对于CSR或者SSR,都建议配合使用Service worker,来控制资源的调配及骨架屏秒开的体验
react项目上线之后,首先需要保障的是可用性,所以可以通过React.Profiler分析组件的渲染次数及耗时的一些任务,但是Profile记录的是commit阶段的数据,所以对于react的调和阶段就需要结合performance API一起分析;
由于React是父级props改变之后,所有与props不相关子组件在没有添加条件控制的情况之下,也会触发render渲染,这是没有必要的,可以结合React的PureComponent以及React.memo等做浅比较处理,这中间有涉及到不可变数据的处理,当然也可以结合使用ShouldComponentUpdate做深比较处理;
所有的运行状态优化,都是减少不必要的render,React.useMemo与React.useCallback也是可以做很多优化的地方;
在很多应用中,都会涉及到使用redux以及使用context,这两个都可能造成许多不必要的render,所以在使用的时候,也需要谨慎的处理一些数据;
最后就是保证整个应用的可用性,为组件创建错误边界,可以使用componentDidCatch来处理;
实际项目中开发过程中还有很多其他的优化点:
- 保证数据的不可变性
- 使用唯一的键值迭代
- 使用web worker做密集型的任务处理
- 不在render中处理数据
- 不必要的标签,使用React.Fragments
什么是无状态组件?
如果行为独立于其状态,则它可以是无状态组件。你可以使用函数或类来创建无状态组件。但除非你需要在组件中使用生命周期钩子,否则你应该选择函数组件。无状态组件有很多好处: 它们易于编写,理解和测试,速度更快,而且你可以完全避免使用this关键字。
什么是有状态组件?
如果组件的行为依赖于组件的state,那么它可以被称为有状态组件。这些有状态组件总是类组件,并且具有在constructor中初始化的状态。
为什么使用 Fragments 比使用容器 div 更好?
- 通过不创建额外的 DOM 节点,Fragments 更快并且使用更少的内存。这在非常大而深的节点树时很有好处。
- 一些 CSS 机制如Flexbox和CSS Grid具有特殊的父子关系,如果在中间添加 div 将使得很难保持所需的结构。
- 在 DOM 审查器中不会那么的杂乱。
什么是高阶组件(HOC)?
高阶组件(HOC) 就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件,它只是一种模式,这种模式是由react自身的组合性质必然产生的。
我们将它们称为纯组件,因为它们可以接受任何动态提供的子组件,但它们不会修改或复制其输入组件中的任何行为。
1 | const EnhancedComponent = higherOrderComponent(WrappedComponent) |
HOC 有很多用例:
- 代码复用,逻辑抽象化
- 渲染劫持
- 抽象化和操作状态(state)
- 操作属性(props)
在组件类中方法的推荐顺序是什么?
从 mounting 到 render stage 阶段推荐的方法顺序:
- static 方法
- constructor()
- getChildContext()
- componentWillMount()
- componentDidMount()
- componentWillReceiveProps()
- shouldComponentUpdate()
- componentWillUpdate()
- componentDidUpdate()
- componentWillUnmount()
- 点击处理程序或事件处理程序,如 onClickSubmit() 或 onChangeDescription()
- 用于渲染的getter方法,如 getSelectReason() 或 getFooterContent()
- 可选的渲染方法,如 renderNavigation() 或 renderProfilePicture()
- render()
生命周期方法 getSnapshotBeforeUpdate() 的目的是什么?
新的 getSnapshotBeforeUpdate() 生命周期方法在 DOM 更新之前被调用。此方法的返回值将作为第三个参数传递给componentDidUpdate()。
此生命周期方法与 componentDidUpdate() 一起涵盖了 componentWillUpdate() 的所有用例。
生命周期方法 getDerivedStateFromProps() 的目的是什么?
新的静态 getDerivedStateFromProps() 生命周期方法在实例化组件之后以及重新渲染组件之前调用。它可以返回一个对象用于更新状态,或者返回 null 指示新的属性不需要任何状态更新。
此生命周期方法与 componentDidUpdate() 一起涵盖了 componentWillReceiveProps() 的所有用例。
在 React v16 中,哪些生命周期方法将被弃用?
以下生命周期方法将成为不安全的编码实践,并且在异步渲染方面会更有问题。
- componentWillMount()
- componentWillReceiveProps()
- componentWillUpdate()
从 React v16.3 开始,这些方法使用 UNSAFE_ 前缀作为别名,未加前缀的版本将在 React v17 中被移除。
React 生命周期方法有哪些?
React 16.3+
- getDerivedStateFromProps: 在调用render()之前调用,并在 每次 渲染时调用。 需要使用派生状态的情况是很罕见得。值得阅读 如果你需要派生状态.
- componentDidMount: 首次渲染后调用,所有得 Ajax 请求、DOM 或状态更新、设置事件监听器都应该在此处发生。
- shouldComponentUpdate: 确定组件是否应该更新。 默认情况下,它返回true。 如果你确定在更新状态或属性后不需要渲染组件,则可以返回false值。 它是一个提高性能的好地方,因为它允许你在组件接收新属性时阻止重新渲染。
- getSnapshotBeforeUpdate: 在最新的渲染输出提交给 DOM 前将会立即调用,这对于从 DOM 捕获信息(比如:滚动位置)很有用。
- componentDidUpdate: 它主要用于更新 DOM 以响应 prop 或 state 更改。 如果shouldComponentUpdate()返回false,则不会触发。
- componentWillUnmount: 当一个组件被从 DOM 中移除时,该方法被调用,取消网络请求或者移除与该组件相关的事件监听程序等应该在这里进行。
Before 16.3
- componentWillMount: 在组件render()前执行,用于根组件中的应用程序级别配置。应该避免在该方法中引入任何的副作用或订阅。
- componentDidMount: 首次渲染后调用,所有得 Ajax 请求、DOM 或状态更新、设置事件监听器都应该在此处发生。
- componentWillReceiveProps: 在组件接收到新属性前调用,若你需要更新状态响应属性改变(例如,重置它),你可能需对比this.props和nextProps并在该方法中使用this.setState()处理状态改变。
- shouldComponentUpdate: 确定组件是否应该更新。 默认情况下,它返回true。 如果你确定在更新状态或属性后不需要渲染组件,则可以返回false值。 它是一个提高性能的好地方,因为它允许你在组件接收新属性时阻止重新渲染。
- componentWillUpdate: 当shouldComponentUpdate返回true后重新渲染组件之前执行,注意你不能在这调用this.setState()
- componentDidUpdate: 它主要用于更新 DOM 以响应 prop 或 state 更改。 如果shouldComponentUpdate()返回false,则不会触发。
- componentWillUnmount: 当一个组件被从 DOM 中移除时,该方法被调用,取消网络请求或者移除与该组件相关的事件监听程序等应该在这里进行。
组件生命周期的不同阶段是什么?
组件生命周期有三个不同的生命周期阶段:
Mounting: 组件已准备好挂载到浏览器的 DOM 中. 此阶段包含来自 constructor(), getDerivedStateFromProps(), render(), 和 componentDidMount() 生命周期方法中的初始化过程。
Updating: 在此阶段,组件以两种方式更新,发送新的属性并使用 setState() 或 forceUpdate() 方法更新状态. 此阶段包含 getDerivedStateFromProps(), shouldComponentUpdate(), render(), getSnapshotBeforeUpdate() 和 componentDidUpdate() 生命周期方法。
Unmounting: 在这个最后阶段,不需要组件,它将从浏览器 DOM 中卸载。这个阶段包含 componentWillUnmount() 生命周期方法。
值得一提的是,在将更改应用到 DOM 时,React 内部也有阶段概念。它们按如下方式分隔开:
Render 组件将会进行无副作用渲染。这适用于纯组件(Pure Component),在此阶段,React 可以暂停,中止或重新渲染。
Pre-commit 在组件实际将更改应用于 DOM 之前,有一个时刻允许 React 通过getSnapshotBeforeUpdate()捕获一些 DOM 信息(例如滚动位置)。
Commit React 操作 DOM 并分别执行最后的生命周期: componentDidMount() 在 DOM 渲染完成后调用, componentDidUpdate() 在组件更新时调用, componentWillUnmount() 在组件卸载时调用。 React 16.3+ 阶段 (也可以看交互式版本)
React 组件通信方式
react组件间通信常见的几种情况:
- 父组件向子组件通信
- 子组件向父组件通信
- 跨级组件通信
- 非嵌套关系的组件通信
1)父组件向子组件通信
父组件通过 props 向子组件传递需要的信息。
2)子组件向父组件通信
props+回调的方式。
3)跨级组件通信
即父组件向子组件的子组件通信,向更深层子组件通信。
- 使用props,利用中间组件层层传递,但是如果父组件结构较深,那么中间每一层组件都要去传递props,增加了复杂度,并且这些props并不是中间组件自己需要的。
- 使用context,context相当于一个大容器,我们可以把要通信的内容放在这个容器中,这样不管嵌套多深,都可以随意取用,对于跨越多层的全局数据可以使用context实现。
4)非嵌套关系的组件通信
即没有任何包含关系的组件,包括兄弟组件以及不在同一个父级中的非兄弟组件。
- 可以使用自定义事件通信(发布订阅模式)
- 可以通过redux等进行全局状态管理
- 如果是兄弟组件通信,可以找到这两个兄弟节点共同的父节点, 结合父子间通信方式进行通信。
什么是 Flux?
Flux 是应用程序设计范例,用于替代更传统的 MVC 模式。它不是一个框架或库,而是一种新的体系结构,它补充了 React 和单向数据流的概念。在使用 React 时,Facebook 会在内部使用此模式。
简述 flux 思想
Flux 的最大特点,就是数据的”单向流动”。
- 用户访问 View
- View 发出用户的 Action
- Dispatcher 收到 Action,要求 Store 进行相应的更新
- Store 更新后,发出一个”change”事件
- View 收到”change”事件后,更新页面
了解 redux 么,说一下 redux 吧
Redux 是基于 Flux设计模式 的 JavaScript 应用程序的可预测状态容器。Redux 可以与 React 一起使用,也可以与任何其他视图库一起使用。它很小(约2kB)并且没有依赖性。
1、为什么要用redux
在React中,数据在组件中是单向流动的,数据从一个方向父组件流向子组件(通过props), 所以,两个非父子组件之间通信就相对麻烦,redux的出现就是为了解决state里面的数据问题
2、Redux设计理念
Redux是将整个应用状态存储到一个地方上称为store, 里面保存着一个状态树store tree, 组件可以派发(dispatch)行为(action)给store, 而不是直接通知其他组件,组件内部通过订阅store中的状态state来刷新自己的视图。
redux工作流
3、Redux三大原则
唯一数据源
整个应用的state都被存储到一个状态树里面,并且这个状态树,只存在于唯一的store中保持只读状态
state是只读的,唯一改变state的方法就是触发action,action是一个用于描述以发生时间的普通对象数据改变只能通过纯函数来执行
使用纯函数来执行修改,为了描述action如何改变state的,你需要编写reducers
4、Redux概念解析
- Store
- store就是保存数据的地方,你可以把它看成一个数据,整个应用只能有一个store
- Redux提供createStore这个函数,用来生成Store
1 | import { |
- State
state就是store里面存储的数据,store里面可以拥有多个state,Redux规定一个state对应一个View, 只要state相同,view就是一样的,反过来也是一样的,可以通过store.getState( )获取
1 | import { |
- Action
state的改变会导致View的变化,但是在redux中不能直接操作state也就是说不能使用this. setState来操作,用户只能接触到View。在Redux中提供了一个对象来告诉Store需要改变state。Action是一个对象其中type属性是必须的,表示Action的名称,其他的可以根据需求自由设置。
1 | const action = { |
在上面代码中,Action的名称是ADD_TODO,携带的数据是字符串‘redux原理’,Action描述当前发生的事情,这是改变state的唯一的方式
- store.dispatch()
store.dispatch() // 是view发出Action的唯一办法
1 | store.dispatch({ |
store.dispatch接收一个Action作为参数,将它发送给store通知store来改变state。
- Reducer
Store收到Action以后,必须给出一个新的state,这样view才会发生变化。这种state的计算过程就叫做Reducer。 Reducer是一个纯函数,他接收Action和当前state作为参数,返回一个新的state
注意:Reducer必须是一个纯函数,也就是说函数返回的结果必须由参数state和action决定,而且不产生任何副作用也不能修改state和action对象
1 | const reducer = (state, action) => { |
5、Redux源码
1 | let createStore = (reducer) => { |
Redux 的核心原则是什么?
Redux 遵循三个基本原则:
- 单一数据来源: 整个应用程序的状态存储在单个对象树中。单状态树可以更容易地跟踪随时间的变化并调试或检查应用程序。
- 状态是只读的: 改变状态的唯一方法是发出一个动作,一个描述发生的事情的对象。这可以确保视图和网络请求都不会直接写入状态。
- 使用纯函数进行更改: 要指定状态树如何通过操作进行转换,您可以编写reducers。Reducers 只是纯函数,它将先前的状态和操作作为参数,并返回下一个状态。
redux中间件
中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过滤,日志输出,异常报告等功能
redux-logger:提供日志输出redux-thunk:处理异步操作redux-promise:处理异步操作,actionCreator的返回值是promise
我需要将所有状态保存到 Redux 中吗?我应该使用 react 的内部状态吗?
这取决于开发者的决定。即开发人员的工作是确定应用程序的哪种状态,以及每个状态应该存在的位置,有些用户喜欢将每一个数据保存在 Redux 中,以维护其应用程序的完全可序列化和受控。其他人更喜欢在组件的内部状态内保持非关键或UI状态,例如“此下拉列表当前是否打开”。
以下是确定应将哪种数据放入Redux的主要规则:
- 应用程序的其他部分是否关心此数据?
- 您是否需要能够基于此原始数据创建更多派生数据?
- 是否使用相同的数据来驱动多个组件?
- 能够将此状态恢复到给定时间点(即时间旅行调试)是否对您有价值?
- 您是否要缓存数据(即,如果已经存在,则使用处于状态的状态而不是重新请求它)?
与 Flux 相比,Redux 的缺点是什么?
我们应该说使用 Redux 而不是 Flux 几乎没有任何缺点。这些如下:
- 您将需要学会避免突变: Flux 对变异数据毫不吝啬,但 Redux 不喜欢突变,许多与 Redux 互补的包假设您从不改变状态。您可以使用 dev-only 软件包强制执行此操作,例如redux-immutable-state-invariant,Immutable.js,或指示您的团队编写非变异代码。
- 您将不得不仔细选择您的软件包: 虽然 Flux 明确没有尝试解决诸如撤消/重做,持久性或表单之类的问题,但 Redux 有扩展点,例如中间件和存储增强器,以及它催生了丰富的生态系统。
- 还没有很好的 Flow 集成: Flux 目前可以让你做一些非常令人印象深刻的静态类型检查,Redux 还不支持。
Relay 与 Redux 有何不同?
Relay 与 Redux 类似,因为它们都使用单个 Store。主要区别在于 relay 仅管理源自服务器的状态,并且通过GraphQL查询(用于读取数据)和突变(用于更改数据)来使用对状态的所有访问。Relay 通过仅提取已更改的数据而为您缓存数据并优化数据提取。
如何向 Redux 添加多个中间件?
你可以使用applyMiddleware()。
例如,你可以添加redux-thunk和logger作为参数传递给applyMiddleware():
1 | import { createStore, applyMiddleware } from 'redux' |
什么是 Redux Form?
Redux Form与 React 和 Redux 一起使用,以使 React 中的表单能够使用 Redux 来存储其所有状态。Redux Form 可以与原始 HTML5 输入一起使用,但它也适用于常见的 UI 框架,如 Material UI,React Widgets和React Bootstrap。
什么是 Redux Thunk?
Redux Thunk中间件允许您编写返回函数而不是 Action 的创建者。 thunk 可用于延迟 Action 的发送,或仅在满足某个条件时发送。内部函数接收 Store 的方法dispatch()和getState()作为参数。
什么是 redux-saga?
redux-saga是一个库,旨在使 React/Redux 项目中的副作用(数据获取等异步操作和访问浏览器缓存等可能产生副作用的动作)更容易,更好。
这个包在 NPM 上有发布:
1 | npm install --save redux-saga |
在 redux-saga 中 call() 和 put() 之间有什么区别?
call()和put()都是 Effect 创建函数。 call()函数用于创建 Effect 描述,指示中间件调用 promise。put()函数创建一个 Effect,指示中间件将一个 Action 分派给 Store。
让我们举例说明这些 Effect 如何用于获取特定用户数据。
1 | function* fetchUserSaga(action) { |
redux-saga 和 redux-thunk 之间有什么区别?
Redux Thunk和Redux Saga都负责处理副作用。在大多数场景中,Thunk 使用Promises来处理它们,而 Saga 使用Generators。Thunk 易于使用,因为许多开发人员都熟悉 Promise,Sagas/Generators 功能更强大,但您需要学习它们。但是这两个中间件可以共存,所以你可以从 Thunks 开始,并在需要时引入 Sagas。
redux-saga 和 mobx 的比较
1)状态管理
- redux-sage 是 redux 的一个异步处理的中间件。
- mobx 是数据管理库,和 redux 一样。
2)设计思想
- redux-sage 属于 flux 体系, 函数式编程思想。
- mobx 不属于 flux 体系,面向对象编程和响应式编程。
3)主要特点
- redux-sage 因为是中间件,更关注异步处理的,通过 Generator 函数来将异步变为同步,使代码可读性高,结构清晰。action 也不是 action creator 而是 pure action,
- 在 Generator 函数中通过 call 或者 put 方法直接声明式调用,并自带一些方法,如 takeEvery,takeLast,race等,控制多个异步操作,让多个异步更简单。
- mobx 是更简单更方便更灵活的处理数据。 Store 是包含了 state 和 action。state 包装成一个可被观察的对象, action 可以直接修改 state,之后通过 Computed values 将依赖 state 的计算属性更新 ,之后触发 Reactions 响应依赖 state 的变更,输出相应的副作用 ,但不生成新的 state。
4)数据可变性
- redux-sage 强调 state 不可变,不能直接操作 state,通过 action 和 reducer 在原来的 state 的基础上返回一个新的 state 达到改变 state 的目的。
- mobx 直接在方法中更改 state,同时所有使用的 state 都发生变化,不生成新的 state。
5)写法难易度
- redux-sage 比 redux 在 action 和 reducer 上要简单一些。需要用 dispatch 触发 state 的改变,需要 mapStateToProps 订阅 state。
- mobx 在非严格模式下不用 action 和 reducer,在严格模式下需要在 action 中修改 state,并且自动触发相关依赖的更新。
6)使用场景
- redux-sage 很好的解决了 redux 关于异步处理时的复杂度和代码冗余的问题,数据流向比较好追踪。但是 redux 的学习成本比 较高,代码比较冗余,不是特别需要状态管理,最好用别的方式代替。
- mobx 学习成本低,能快速上手,代码比较简洁。但是可能因为代码编写的原因和数据更新时相对黑盒,导致数据流向不利于追踪。
什么是 Redux DevTools?
Redux DevTools是 Redux 的实时编辑的时间旅行环境,具有热重新加载,Action 重放和可自定义的 UI。如果您不想安装 Redux DevTools 并将其集成到项目中,请考虑使用 Chrome 和 Firefox 的扩展插件。
React 和 Angular 有什么区别?
| React | Angular |
|---|---|
| React 是一个库,只有View层 | Angular是一个框架,具有完整的 MVC 功能 |
| React 可以处理服务器端的渲染 | AngularJS 仅在客户端呈现,但 Angular 2 及更高版本可以在服务器端渲染 |
| React 在 JS 中使用看起来像 HTML 的 JSX,这可能令人困惑 | Angular 遵循 HTML 的模板方法,这使得代码更短且易于理解 |
| React Native 是一种 React 类型,它用于构建移动应用程序,它更快,更稳定 | Ionic,Angular 的移动 app 相对原生 app 来说不太稳定和慢 |
| 在 React中,数据只以单一方向传递,因此调试很容易 | 在 Angular 中,数据以两种方式传递,即它在子节点和父节点之间具有双向数据绑定,因此调试通常很困难 |
与 Vue.js 相比,React 有哪些优势?
与 Vue.js 相比,React 具有以下优势:
- 在大型应用程序开发中提供更大的灵活性。
- 更容易测试。
- 更适合创建移动端应用程序。
- 提供更多的信息和解决方案。
比较一下React与Vue
相同点
- 都有组件化开发和Virtual DOM
- 都支持props进行父子组件间数据通信
- 都支持数据驱动视图, 不直接操作真实DOM, 更新状态数据界面就自动更新
- 都支持服务器端渲染
- 都有支持native的方案,React的React Native,Vue的Weex
不同点
- 数据绑定: vue实现了数据的双向绑定,react数据流动是单向的
- 组件写法不一样, React推荐的做法是 JSX , 也就是把HTML和CSS全都写进JavaScript了,即’all in js’; Vue推荐的做法是webpack+vue-loader的单文件组件格式,即html,css,js写在同一个文件
- state对象在react应用中不可变的,需要使用setState方法更新状态;在vue中,state对象不是必须的,数据由data属性在vue对象中管理
- virtual DOM不一样,vue会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。而对于React而言,每当应用的状态被改变时,全部组件都会重新渲染,所以react中会需要shouldComponentUpdate这个生命周期函数方法来进行控制
- React严格上只针对MVC的view层,Vue则是MVVM模式
Vue与React Virtual DOM对比
相同点
vue和react都采用了虚拟dom算法,以最小化更新真实DOM,从而减小不必要的性能损耗。
按颗粒度分为tree diff, component diff, element diff。 tree diff 比较同层级dom节点,进行增、删、移操作。如果遇到component元素, 就会重新tree diff流程。
不同点
dom的更新策略不同
react 会自顶向下全diff。
vue 会跟踪每一个组件的依赖关系,不需要重新渲染整个组件树。
在react中,当状态发生改变时,组件树就会自顶向下的全diff, 重新render页面, 重新生成新的虚拟dom tree, 新旧dom tree进行比较, 进行patch打补丁方式,局部跟新dom. 所以react为了避免父组件跟新而引起不必要的子组件更新, 可以在shouldComponentUpdate做逻辑判断,减少没必要的render, 以及重新生成虚拟dom,做差量对比过程。
在 vue中, 通过Object.defineProperty 把这些 data 属性 全部转为 getter/setter。同时watcher实例对象会在组件渲染时,将属性记录为dep, 当dep 项中的 setter被调用时,通知watch重新计算,使得关联组件更新。
Diff 算法借助元素的 Key 判断元素是新增、删除、修改,从而减少不必要的元素重渲染。
建议
- 基于tree diff
- 开发组件时,注意保持DOM结构的稳定;即尽可能少地动态操作DOM结构,尤其是移动操作。
- 当节点数过大或者页面更新次数过多时,页面卡顿的现象会比较明显。这时可以通过 CSS 隐藏或显示节点,而不是真的移除或添加 DOM 节点。
- 基于component diff
- 注意使用 shouldComponentUpdate() 来减少组件不必要的更新。
- 对于类似的结构应该尽量封装成组件,既减少代码量,又能减少component diff的性能消耗。
- 基于element diff:
- 对于列表结构,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,在一定程度上会影响渲染性能。
- 循环渲染的必须加上key值,唯一标识节点。
什么是mvvm?
MVVM是Model-View-ViewModel的缩写。mvvm是一种设计思想。Model 层代表数据模型,也可以在Model中定义数据修改和操作的业务逻辑;View 代表UI 组件,它负责将数据模型转化成UI 展现出来,ViewModel 是一个同步View 和 Model的对象
- 在MVVM架构下,View 和 Model 之间并没有直接的联系,而是通过ViewModel进行交互,Model 和 ViewModel 之间的交互是双向的, 因此View 数据的变化会同步到Model中,而Model 数据的变化也会立即反应到View 上。
- ViewModel 通过双向数据绑定把 View 层和 Model 层连接了起来,而View 和 Model 之间的同步工作完全是自动的,无需人为干涉,因此开发者只需关注业务逻辑,不需要手动操作DOM, 不需要关注数据状态的同步问题,复杂的数据状态维护完全由 MVVM 来统一管理
MVC、MVP 与 MVVM 模式
一、MVC
通信方式如下
视图(View):用户界面。 传送指令到 Controller
控制器(Controller):业务逻辑 完成业务逻辑后,要求 Model 改变状态
模型(Model):数据保存 将新的数据发送到 View,用户得到反馈
二、MVP
通信方式如下
各部分之间的通信,都是双向的。
View 与 Model 不发生联系,都通过 Presenter 传递。
View 非常薄,不部署任何业务逻辑,称为”被动视图”(Passive View),即没有任何主动性,而 Presenter 非常厚,所有逻辑都部署在那里。
三、MVVM
MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。通信方式如下
唯一的区别是,它采用双向绑定(data-binding):View 的变动,自动反映在 ViewModel,反之亦然。
MVVM
MVVM 由以下三个内容组成
View:界面Model:数据模型ViewModel:作为桥梁负责沟通View和Model
- 在 JQuery 时期,如果需要刷新 UI 时,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和页面有强耦合
- 在 MVVM 中,UI 是通过数据驱动的,数据一旦改变就会相应的刷新对应的 UI,UI 如果改变,也会改变对应的数据。这种方式就可以在业务处理中只关心数据的流转,而无需直接和页面打交道。ViewModel 只关心数据和业务的处理,不关心 View 如何处理数据,在这种情况下,View 和 Model 都可以独立出来,任何一方改变了也不一定需要改变另一方,并且可以将一些可复用的逻辑放在一个 ViewModel 中,让多个 View 复用这个 ViewModel
- 在 MVVM 中,最核心的也就是数据双向绑定,例如 Angluar 的脏数据检测,Vue 中的数据劫持
脏数据检测
- 当触发了指定事件后会进入脏数据检测,这时会调用 $digest 循环遍历所有的数据观察者,判断当前值是否和先前的值有区别,如果检测到变化的话,会调用 $watch 函数,然后再次调用 $digest 循环直到发现没有变化。循环至少为二次 ,至多为十次
- 脏数据检测虽然存在低效的问题,但是不关心数据是通过什么方式改变的。并且脏数据检测可以实现批量检测出更新的值,再去统一更新 UI,大大减少了操作 DOM 的次数
数据劫持
Vue内部使用了Obeject.defineProperty()来实现双向绑定,通过这个函数可以监听到set和get的事件
1 | var data = { name: 'yck' } |
以上代码简单的实现了如何监听数据的 set 和 get 的事件,但是仅仅如此是不够的,还需要在适当的时候给属性添加发布订阅
1 | <div> |
在解析如上模板代码时,遇到
{{name}}就会给属性name添加发布订阅
1 | // 通过 Dep 解耦 |
接下来,对 defineReactive 函数进行改造
1 | function observe(obj) { |
以上实现了一个简易的双向绑定,核心思路就是手动触发一次属性的 getter 来实现发布订阅的添加
Proxy 与 Obeject.defineProperty 对比
Obeject.defineProperty虽然已经能够实现双向绑定了,但是他还是有缺陷的。- 只能对属性进行数据劫持,所以需要深度遍历整个对象
- 对于数组不能监听到数据的变化
虽然
Vue中确实能检测到数组数据的变化,但是其实是使用了hack的办法,并且也是有缺陷的
vue的优点是什么?
低耦合。视图(View)可以独立于 Model 变化和修改,一个 ViewModel 可以绑定到不同的”View”上,当 View 变化的时候 Model 可以不变,当 Model 变化的时候 View 也可以不变。
可重用性。你可以把一些视图逻辑放在一个 ViewModel 里面,让很多 view 重用这段视图逻辑。
独立开发。开发人员可以专注于业务逻辑和数据的开发(ViewModel),设计人员可以专注于页面设计。
可测试。界面素来是比较难于测试的,而现在测试可以针对 ViewModel 来写。
对于 Vue 是一套渐进式框架的理解
每个框架都不可避免会有自己的一些特点,从而会对使用者有一定的要求,这些要求就是主张,主张有强有弱,它的强势程度会影响在业务开发中的使用方式。
1、使用 vue,你可以在原有大系统的上面,把一两个组件改用它实现,当 jQuery 用;
2、也可以整个用它全家桶开发,当 Angular 用;
3、还可以用它的视图,搭配你自己设计的整个下层用。你可以在底层数据逻辑的地方用 OO(Object–Oriented )面向对象和设计模式的那套理念。 也可以函数式,都可以。
它只是个轻量视图而已,只做了自己该做的事,没有做不该做的事,仅此而已。
你不必一开始就用 Vue 所有的全家桶,根据场景,官方提供了方便的框架供你使用。
场景联想
场景 1: 维护一个老项目管理后台,日常就是提交各种表单了,这时候你可以把 vue 当成一个 js 库来使用,就用来收集 form 表单,和表单验证。
场景 2: 得到 boss 认可, 后面整个页面的 dom 用 Vue 来管理,抽组件,列表用 v-for 来循环,用数据驱动 DOM 的变化
场景 3: 越来越受大家信赖,领导又找你了,让你去做一个移动端 webapp,直接上了 vue 全家桶!
场景 1-3 从最初的只因多看你一眼而用了前端 js 库,一直到最后的大型项目解决方案。
Vue2.0 中,“渐进式框架”和“自底向上增量开发的设计”这两个概念是什么?
在我看来,渐进式代表的含义是:主张最少。
每个框架都不可避免会有自己的一些特点,从而会对使用者有一定的要求,这些要求就是主张,主张有强有弱,它的强势程度会影响在业务开发中的使用方式。
比如说,Angular,它两个版本都是强主张的,如果你用它,必须接受以下东西:
- 必须使用它的模块机制
- 必须使用它的依赖注入
- 必须使用它的特殊形式定义组件(这一点每个视图框架都有,难以避免)
所以Angular是带有比较强的排它性的,如果你的应用不是从头开始,而是要不断考虑是否跟其他东西集成,这些主张会带来一些困扰。
比如React,它也有一定程度的主张,它的主张主要是函数式编程的理念,比如说,你需要知道什么是副作用,什么是纯函数,如何隔离副作用。它的侵入性看似没有Angular那么强,主要因为它是软性侵入。
你当然可以只用React的视图层,但几乎没有人这么用,为什么呢,因为你用了它,就会觉得其他东西都很别扭,于是你要引入Flux,Redux,Mobx之中的一个,于是你除了Redux,还要看saga,于是你要纠结业务开发过程中每个东西有没有副作用,纯不纯,甚至你连这个都可能不能忍:
1 | const getData = () => { |
因为你要纠结它有外部依赖,同样是不加参数调用,连续两次的结果是不一样的,于是不纯。
为什么我一直不认同在中后台项目中使用React,原因就在这里,我反对的是整个业务应用的函数式倾向,很多人都是看到有很多好用的React组件,就会倾向于把它引入,然后,你知道怎么把自己的业务映射到函数式的那套理念上吗?
函数式编程,无副作用,写出来的代码没有bug,这是真理没错,但是有两个问题需要考虑:
- JS本身,有太多特性与纯函数式的主张不适配,这一点,题叶能说得更多
- 业务系统里面的实体关系,如何组织业务逻辑,几十年来积累了无数的基于设计模式的场景经验,有太多的东西可以模仿,但是,没有人给你总结那么多如何把你的厚重业务映射到函数式理念的经验,这个地方很考验综合水平的,真的每个人都有能力去做这种映射吗?
函数式编程无bug的根本就在于要把业务逻辑完全都依照这套理念搞好,你看看自己公司做中后台的员工,他们熟悉的是什么?是基于传统OO设计模式的这套东西,他们以为拿着你们给的组件库就得到了一切,但是可能还要被灌输函数式编程的一整套东西,而且又没人告诉他们在业务场景下,如何规划业务模型、组织代码,还要求快速开发,怎么能快起来?
所以我真是心疼这些人,他们要的只是组件库,却不得不把业务逻辑的思考方式也作转换,这个事情没有一两年时间洗脑,根本洗不到能开发业务的程度。
没有好组件库的时候,大家痛点在视图层,有了基于React的组件化,把原先没那么痛的业务逻辑部分搞得也痛起来了,原先大家按照设计模式教的东西,照猫画虎还能继续开发了,学了一套新理念之后,都不知道怎么写代码了,怎么写都怀疑自己不对,可怕。
我宁可支持Angular也不支持React的原因也就在此,Angular至少在业务逻辑这块没有软主张,能够跟OO设计模式那套东西配合得很好。我面对过很多商务场景,都是前端很厚重的东西,不仅仅是管理控制台这种,这类东西里面,业务逻辑的占比要比视图大挺多的,如何组织这些东西,目前几个主流技术栈都没有解决方案,要靠业务架构师去摆平。
如果你的场景不是这么厚重的,只是简单管理控制台,那当我没说好了。
框架是不能解决业务问题的,只能作为工具,放在合适的人手里,合适的场景下。
现在我要说说为什么我这么支持Vue了,没什么,可能有些方面是不如React,不如Angular,但它是渐进的,没有强主张,你可以在原有大系统的上面,把一两个组件改用它实现,当jQuery用;也可以整个用它全家桶开发,当Angular用;还可以用它的视图,搭配你自己设计的整个下层用。你可以在底层数据逻辑的地方用OO和设计模式的那套理念,也可以函数式,都可以,它只是个轻量视图而已,只做了自己该做的事,没有做不该做的事,仅此而已。
渐进式的含义,我的理解是:没有多做职责之外的事。
Vue computed 实现
- 建立与其他属性(如:data、 Store)的联系;
- 属性改变后,通知计算属性重新计算
实现时,主要如下
- 初始化 data, 使用
Object.defineProperty把这些属性全部转为getter/setter。 - 初始化
computed, 遍历computed里的每个属性,每个 computed 属性都是一个 watch 实例。每个属性提供的函数作为属性的 getter,使用 Object.defineProperty 转化。 Object.defineProperty getter依赖收集。用于依赖发生变化时,触发属性重新计算。- 若出现当前 computed 计算属性嵌套其他 computed 计算属性时,先进行其他的依赖收集
Vue complier 实现
- 模板解析这种事,本质是将数据转化为一段 html ,最开始出现在后端,经过各种处理吐给前端。随着各种 mv* 的兴起,模板解析交由前端处理。
- 总的来说,Vue complier 是将 template 转化成一个 render 字符串。
可以简单理解成以下步骤:
- parse 过程,将 template 利用正则转化成 AST 抽象语法树。
- optimize 过程,标记静态节点,后 diff 过程跳过静态节点,提升性能。
- generate 过程,生成 render 字符串
如何编译 template 模板?
- 首先第一步实例化一个vue项目
- 模板编译是在vue生命周期的mount阶段进行的
- 在mount阶段的时候执行了compile方法将template里面的内容转化成真正的html代码
- parse阶段是将html转化成 AST 抽象语法树,用来表示template代码的数据结构。在 Vue 中我把它理解为嵌套的、携带标签名、属性和父子关系的 JS 对象,以树来表现 DOM 结构。
1 | html: "<div id="test">texttext</div>" |
- optimize 会对parse阶段生成的 AST 树进行静态资源优化(静态内容指的是和数据没有关系,不需要每次都刷新的内容)
- generate 函数会将每一个 AST 节点生成一个render字符串方法,其实就是一个内部调用的方法等待后面的调用。
1
2
3
4
5
6
7
8<template>
<div id="test">
{{val}}
<img src="http://xx.jpg">
</div>
</template>
// 最后输出
// {render: "with(this){return _c('div',{attrs:{"id":"test"}},[[_v(_s(val))]),_v(" "),_m(0)])}"} - 在complie过程结束之后会生成一个render字符串,接下来就是 new watcher这个时候会对绑定的数据执行监听,render 函数就是数据监听的回调所调用的,其结果便是重新生成 Vnode。当这个 render 函数字符串在第一次 mount、或者绑定的数据更新的时候,都会被调用,生成 Vnode。如果是数据的更新,那么 Vnode 会与数据改变之前的 Vnode 做 diff,对内容做改动之后,就会更新到我们真正的 DOM 上啦
vue 中的性能优化
1)编码优化
- 尽量减少data中的数据,data中的数据都会增加getter和setter,会收集对应的watcher
- v-if和v-for不能连用
- 如果需要使用v-for给每项元素绑定事件时使用事件代理
- SPA 页面采用keep-alive缓存组件
- 在更多的情况下,使用v-if替代v-show
- key保证唯一
- 使用路由懒加载、异步组件
- 防抖、节流
- 第三方模块按需导入
- 长列表滚动到可视区域动态加载
- 图片懒加载
2)用户体验优化
- 骨架屏
- PWA(渐进式WEB应用)
- 还可以使用缓存(客户端缓存、服务端缓存)优化、服务端开启gzip压缩等。
3)SEO优化
- 预渲染
- 服务端渲染SSR
4)打包优化
- 压缩代码;
- Tree Shaking/Scope Hoisting;
- 使用cdn加载第三方模块;
- 多线程打包happypack;
- splitChunks抽离公共文件;
- sourceMap优化;
说明:优化是个大工程,会涉及很多方面
Vue 的实例生命周期
beforeCreate 初始化实例后 数据观测和事件配置之前调用
created 实例创建完成后调用
beforeMount 挂载开始前被用
mounted el 被新建 vm. $el 替换并挂在到实例上之后调用
beforeUpdate 数据更新时调用
updated 数据更改导致的 DOM 重新渲染后调用
beforeDestory 实例被销毁前调用
destroyed 实例销毁后调用
Vue2 与Vue3的生命周期对比
| 变量 | 实例化(次数) |
|---|---|
| beforeCreate(组件创建之前) | setup(组件创建之前) |
| created(组件创建完成) | setup(组件创建完成) |
| beforeMount(组件挂载之前) | onBeforeMount(组件挂载之前) |
| mounted(组件挂载完成) | onMounted(组件挂载完成) |
| beforeUpdate(数据更新,虚拟DOM打补丁之前) | onBeforeUpdate(数据更新,虚拟DOM打补丁之前) |
| updated(数据更新,虚拟DOM渲染完成) | onUpdated(数据更新,虚拟DOM渲染完成) |
| beforeDestroy(组件销毁之前) | onBeforeUnmount(组件销毁之前) |
| destroyed(组件销毁之后) | onUnmounted(组件销毁之后) |
Vue 的双向数据绑定的原理
VUE 实现双向数据绑定的原理就是利用了 Object. defineProperty() 这个方法重新定义了对象获取属性值(get)和设置属性值(set)的操作来实现的。
Vue3. 0 将用原生 Proxy 替换 Object. defineProperty
为什么要替换 Object.defineProperty?(Proxy 相比于 defineProperty 的优势)
在 Vue 中,Object.defineProperty 无法监控到数组下标的变化,导致直接通过数组的下标给数组设置值,不能实时响应。
Object.defineProperty只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。Vue 2.x里,是通过 递归 + 遍历 data 对象来实现对数据的监控的,如果属性值也是对象那么需要深度遍历,显然如果能劫持一个完整的对象是才是更好的选择。
而要取代它的Proxy有以下两个优点:
- 可以劫持整个对象,并返回一个新对象
- 有13种劫持操作
既然Proxy能解决以上两个问题,而且Proxy作为es6的新属性在vue2.x之前就有了,为什么vue2.x不使用Proxy呢?一个很重要的原因就是:
Proxy是es6提供的新特性,兼容性不好,最主要的是这个属性无法用polyfill来兼容
什么是 Proxy?
含义:
Proxy 是 ES6 中新增的一个特性,翻译过来意思是”代理”,用在这里表示由它来“代理”某些操作。 Proxy 让我们能够以简洁易懂的方式控制外部对对象的访问。其功能非常类似于设计模式中的代理模式。
Proxy 可以理解成,在目标对象之前架设一层“拦截”,外界对该对象的访问,都必须先通过这层拦截,因此提供了一种机制,可以对外界的访问进行过滤和改写。
使用 Proxy 的核心优点是可以交由它来处理一些非核心逻辑(如:读取或设置对象的某些属性前记录日志;设置对象的某些属性值前,需要验证;某些属性的访问控制等)。 从而可以让对象只需关注于核心逻辑,达到关注点分离,降低对象复杂度等目的。
基本用法:
1 | let p = new Proxy(target, handler); |
参数:
- target 是用Proxy包装的被代理对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理)。
- handler 是一个对象,其声明了代理target 的一些操作,其属性是当执行一个操作时定义代理的行为的函数。
- p 是代理后的对象。当外界每次对 p 进行操作时,就会执行 handler 对象上的一些方法。Proxy共有13种劫持操作,
handler代理的一些常用的方法有如下几个:
1 | get: 读取 |
示例:
下面就用Proxy来定义一个对象的get和set,作为一个基础demo
1 | let obj = {}; |
p 读取属性的值时,实际上执行的是 handler.get() :在控制台输出信息,并且读取被代理对象 obj 的属性。
p 设置属性值时,实际上执行的是 handler.set() :在控制台输出信息,并且设置被代理对象 obj 的属性的值。
以上介绍了Proxy基本用法,实际上这个属性还有许多内容,具体可参考Proxy文档
为什么避免 v-if 和 v-for 用在一起
当 Vue 处理指令时,v-for 比 v-if 具有更高的优先级,这意味着 v-if 将分别重复运行于每个 v-for 循环中。通过 v-if 移动到容器元素,不会再重复遍历列表中的每个值。取而代之的是,我们只检查它一次,且不会在 v-if 为否的时候运算 v-for。
组件的设计原则
- 页面上每个独立的可视/可交互区域视为一个组件(比如页面的头部,尾部,可复用的区块)
- 每个组件对应一个工程目录,组件所需要的各种资源在这个目录下就近维护(组件的就近维护思想体现了前端的工程化思想,为前端开发提供了很好的分治策略,在vue.js中,通过.vue文件将组件依赖的模板,js,样式写在一个文件中)
(每个开发者清楚开发维护的功能单元,它的代码必然存在在对应的组件目录中,在该目录下,可以找到功能单元所有的内部逻辑) - 页面不过是组件的容器,组件可以嵌套自由组合成完整的页面
vue 等单页面应用及其优缺点
优点:
- 用户体验好、快,内容的改变不需要重新加载整个页面,避免了不必要的跳转和重复渲染。
- 前后端职责业分离(前端负责view,后端负责model),架构清晰
- 减轻服务器的压力
缺点:
- SEO(搜索引擎优化)难度高
- 初次加载页面更耗时
- 前进、后退、地址栏等,需要程序进行管理,所以会大大提高页面的复杂性和逻辑的难度
$route和$router的区别
$route 是路由信息对象,包括path,params,hash,query,fullPath,matched,name 等路由信息参数。
$router 是路由实例对象,包括了路由的跳转方法,钩子函数等
什么是 vue 的计算属性?
定义: 当其依赖的属性的值发生变化的时,计算属性会重新计算。反之则使用缓存中的属性值。 计算属性和vue中的其它数据一样,都是响应式的,只不过它必须依赖某一个数据实现,并且只有它依赖的数据的值改变了,它才会更新。
watch的作用是什么
watch 主要作用是监听某个数据值的变化。和计算属性相比除了没有缓存,作用是一样的。
借助 watch 还可以做一些特别的事情,例如监听页面路由,当页面跳转时,我们可以做相应的权限控制,拒绝没有权限的用户访问页面。
计算属性的缓存和方法调用的区别
计算属性是基于数据的依赖缓存,数据发生变化,缓存才会发生变化,如果数据没有发生变化,调用计算属性直接调用的是存储的缓存值;
而方法每次调用都会重新计算;
所以可以根据实际需要选择使用,如果需要计算大量数据,性能开销比较大,可以选用计算属性,如果不能使用缓存可以使用方法;
其实这两个区别还应加一个watch,watch是用来监测数据的变化,和计算属性相比,是watch没有缓存,但是一般想要在数据变化时响应时,或者执行异步操作时,可以选择watch
指令 v-el 的作用是什么?
通过v-el我们可以获取到DOM对象,通过this.$els[elValue]获得DOM对象;通过v-ref获取到整个组件(component)的对象,通过this.$refs[refValue]获得Component实例对象。
vuex 有哪几种属性?
有五种,分别是 State、 Getter、Mutation 、Action、 Module
vuex的State特性
- Vuex就是一个仓库,仓库里面放了很多对象。其中state就是数据源存放地,对应于一般Vue对象里面的data
- state里面存放的数据是响应式的,Vue组件从store中读取数据,若是store中的数据发生改变,依赖这个数据的组件也会发生更新
- 它通过mapState把全局的 state 和 getters 映射到当前组件的 computed 计算属性中
vuex的Getter特性
- getters 可以对State进行计算操作,它就是Store的计算属性
- 虽然在组件内也可以做计算属性,但是getters 可以在多组件之间复用
- 如果一个状态只在一个组件内使用,是可以不用getters
vuex的Mutation特性
- Action 类似于 mutation,不同在于:Action 提交的是 mutation,而不是直接变更状态;Action 可以包含任意异步操作。
不用 Vuex 会带来什么问题?
可维护性会下降,想修改数据要维护三个地方;
可读性会下降,因为一个组件里的数据,根本就看不出来是从哪来的;
增加耦合,大量的上传派发,会让耦合性大大增加,本来 Vue 用 Component 就是为了减少耦合,现在这么用,和组件化的初衷相背。
vue-router 有哪几种导航钩子( 导航守卫 )?
答案:三种
第一种: 全局导航钩子, router.beforeEach(to, from, next),作用:跳转前进行判断拦截;
1
2
3router.beforeEach((to, from, next) => {
// TODO
});第二种:单独路由独享组件;
1
2
3
4
5
6
7
8{
path: '/home',
name: 'home',
component: Home,
beforeEnter(to, from, next) {
// TODO
}
}第三种:组件内的钩子。
1
2
3
4
5
6
7
8
9
10
11
12beforeRouteEnter(to, from, next) {
// do someting
// 在渲染该组件的对应路由被 confirm 前调用
},
beforeRouteUpdate(to, from, next) {
// do someting
// 在当前路由改变,但是依然渲染该组件是调用
},
beforeRouteLeave(to, from ,next) {
// do someting
// 导航离开该组件的对应路由时被调用
}
vue-router 实现路由懒加载( 动态加载路由 )
vue项目实现按需加载的3种方式:vue异步组件、es提案的import()、webpack的require.ensure()
vue异步组件技术
- vue-router配置路由,使用vue的异步组件技术,可以实现按需加载。
但是,这种情况下一个组件生成一个js文件。
举例如下:
1 | { |
es提案的import()
- 推荐使用这种方式(需要webpack > 2.4)
- webpack官方文档:webpack中使用import()
vue官方文档:路由懒加载(使用import())
- vue-router配置路由,代码如下:
1 | // 下面2行代码,没有指定webpackChunkName,每个组件打包成一个js文件。 |
webpack提供的require.ensure()
- vue-router配置路由,使用webpack的require.ensure技术,也可以实现按需加载。
这种情况下,多个路由指定相同的chunkName,会合并打包成一个js文件。
举例如下:
1 | { |
谈一谈 nextTick 的原理
在下次 DOM 更新循环结束之后执行延迟回调。
nextTick主要使用了宏任务和微任务。
根据执行环境分别尝试采用
Promise MutationObserver setImmediate
如果以上都不行则采用setTimeout定义了一个异步方法,多次调用nextTick会将方法存入队列中,通过这个异步方法清空当前队列。
Vue 的父组件和子组件生命周期钩子执行顺序是什么
加载渲染过程
- 父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
子组件更新过程
- 父beforeUpdate->子beforeUpdate->子updated->父updated
父组件更新过程
- 父beforeUpdate->父updated
销毁过程
- 父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
实现通信方式
方式1: props
- 通过一般属性实现父向子通信
- 通过函数属性实现子向父通信
- 缺点: 隔代组件和兄弟组件间通信比较麻烦
方式2: vue自定义事件
- vue内置实现, 可以代替函数类型的props
- 绑定监听: <MyComp @eventName=”callback”
- 触发(分发)事件: this.$emit(“eventName”, data)
- 缺点: 只适合于子向父通信
方式3: 消息订阅与发布
- 需要引入消息订阅与发布的实现库, 如: pubsub-js
- 订阅消息: PubSub.subscribe(‘msg’, (msg, data)=>{})
- 发布消息: PubSub.publish(‘msg’, data)
- 优点: 此方式可用于任意关系组件间通信
方式4: vuex
- 是什么: vuex是vue官方提供的集中式管理vue多组件共享状态数据的vue插件
- 优点: 对组件间关系没有限制, 且相比于pubsub库管理更集中, 更方便
方式5: slot
- 是什么: 专门用来实现父向子传递带数据的标签
- 子组件
- 父组件
- 注意: 通信的标签模板是在父组件中解析好后再传递给子组件的
说说Vue的MVVM实现原理
- Vue作为MVVM模式的实现库的2种技术
- 模板解析
- 数据绑定
- 模板解析: 实现初始化显示
- 解析大括号表达式
- 解析指令
- 数据绑定: 实现更新显示
- 通过数据劫持实现
Vue.use是干什么的?原理是什么?
vue.use 是用来使用插件的,我们可以在插件中扩展全局组件、指令、原型方法等。
- 检查插件是否注册,若已注册,则直接跳出;
- 处理入参,将第一个参数之后的参数归集,并在首部塞入 this 上下文;
- 执行注册方法,调用定义好的 install 方法,传入处理的参数,若没有 install 方法并且插件本身为 function 则直接进行注册;
插件不能重复的加载
install 方法的第一个参数是vue的构造函数,其他参数是Vue.use中除了第一个参数的其他参数; 代码:args.unshift(this)
调用插件的install 方法 代码:typeof plugin.install === ‘function’
插件本身是一个函数,直接让函数执行。 代码:plugin.apply(null, args)
缓存插件。 代码:installedPlugins.push(plugin)
1 | export function toArray (list: any, start?: number): Array<any> { |
new Vue() 发生了什么?
结论:new Vue()是创建Vue实例,它内部执行了根实例的初始化过程。
具体包括以下操作:
选项合并
$children,$refs,$slots,$createElement等实例属性的方法初始化
自定义事件处理
数据响应式处理
生命周期钩子调用 (beforecreate created)
可能的挂载
- 总结:new Vue()创建了根实例并准备好数据和方法,未来执行挂载时,此过程还会递归的应用于它的子组件上,最终形成一个有紧密关系的组件实例树。
请说一下响应式数据的理解?
根据数据类型来做不同处理,数组和对象类型当值变化时如何劫持。
对象内部通过defineReactive方法,使用Object. defineProperty() 监听数据属性的 get 来进行数据依赖收集,再通过 set 来完成数据更新的派发;
数组则通过重写数组方法来实现的。扩展它的 7 个变更⽅法,通过监听这些方法可以做到依赖收集和派发更新;( push/pop/shift/unshift/splice/reverse/sort )
这里在回答时可以带出一些相关知识点 (比如多层对象是通过递归来实现劫持,顺带提出vue3中是使用 proxy来实现响应式数据)
补充回答:
内部依赖收集是怎么做到的,每个属性都拥有自己的dep属性,存放他所依赖的 watcher,当属性变化后会通知自己对应的 watcher去更新。
响应式流程:
defineReactive 把数据定义成响应式的;
给属性增加一个 dep,用来收集对应的那些watcher;
等数据变化进行更新
dep.depend() // get 取值:进行依赖收集
dep.notify() // set 设置时:通知视图更新
这里可以引出性能优化相关的内容:
对象层级过深,性能就会差。
不需要响应数据的内容不要放在data中。
object.freeze() 可以冻结数据。
Vue如何检测数组变化?
数组考虑性能原因没有用defineProperty对数组的每一项进行拦截,而是选择重写数组方法。当数组调用到这 7 个方法的时候,执行 ob.dep.notify() 进行派发通知 Watcher 更新;
重写数组方法:push/pop/shift/unshift/splice/reverse/sort
补充回答:
在Vue中修改数组的索引和长度是无法监控到的。需要通过以下7种变异方法修改数组才会触发数组对应的wacther进行更新。数组中如果是对象数据类型也会进行递归劫持。
说明:那如果想要改索引更新数据怎么办?
可以通过Vue.set()来进行处理 =》 核心内部用的是 splice 方法。
1 | // 取出原型方法; |
Vue.set 方法是如何实现的?
为什么$set可以触发更新,我们给对象和数组本身都增加了dep属性,当给对象新增不存在的属性则触发对象依赖的watcher去更新,当修改数组索引时我们调用数组本身的splice方法去更新数组。
补充回答:
官方定义Vue.set(object, key, value)
如果是数组,调用重写的splice方法 (这样可以更新视图 )
代码:target.splice(key, 1, val)
如果不是响应式的也不需要将其定义成响应式属性。
如果是对象,将属性定义成响应式的 defineReactive(ob, key, val)
通知视图更新 ob.dep.notify()
Vue3.x响应式数据原理
Vue3.x改用Proxy替代Object.defineProperty。因为Proxy可以直接监听对象和数组的变化,并且有多达13种拦截方法。并且作为新标准将受到浏览器厂商重点持续的性能优化。
Vue3.x中Proxy只会代理对象的第一层,那么Vue3又是怎样处理这个问题的呢?
判断当前Reflect.get的返回值是否为Object,如果是则再通过reactive方法做代理, 这样就实现了深度观测。
Vue3.x中监测数组的时候可能触发多次get/set,那么如何防止触发多次呢?
我们可以判断key是否为当前被代理对象target自身属性,也可以判断旧值与新值是否相等,只有满足以上两个条件之一时,才有可能执行trigger。
vue2.x中如何监测数组变化
- 使用了函数劫持的方式,重写了数组的方法,Vue将data中的数组进行了原型链重写,指向了自己定义的数组原型方法。
- 这样当调用数组api时,可以通知依赖更新。
- 如果数组中包含着引用类型,会对数组中的引用类型再次递归遍历进行监控。这样就实现了监测数组变化。
Vue2.x和Vue3.x渲染器的diff算法分别说一下
简单来说,diff算法有以下过程
- 同级比较,再比较子节点
- 先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
- 比较都有子节点的情况(核心diff)
- 递归比较子节点
- 正常Diff两个树的时间复杂度是O(n^3) ,但实际情况下我们很少会进行跨层级的移动DOM,所以Vue将Diff进行了优化,从O(n^3) -> O(n),只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。
Vue3.x借鉴了 ivi算法和 inferno算法
在创建VNode时就确定其类型,以及在mount/patch的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。(实际的实现可以结合Vue3.x源码看。)
SSR了解吗?
SSR也就是服务端渲染,也就是将Vue在客户端把标签渲染成HTML的工作放在服务端完成,然后再把html直接返回给客户端。
SSR有着更好的SEO、并且首屏加载速度更快等优点。
不过它也有一些缺点,比如我们的开发条件会受到限制,服务器端渲染只支持beforeCreate和created两个钩子,当我们需要一些外部扩展库时需要特殊处理,服务端渲染应用程序也需要处于Node.js的运行环境。
还有就是服务器会有更大的负载需求。
组件中写 name选项有哪些好处及作用?
可以通过名字找到对应的组件( 递归组件 )
可以通过name属性实现缓存功能 (keep-alive)
可以通过name来识别组件(跨级组件通信时非常重要)
1 | Vue.extend = function () { |
传统diff、react优化diff、vue优化diff
传统diff
计算两颗树形结构差异并进行转换,传统diff算法是这样做的:循环递归每一个节点

比如左侧树a节点依次进行如下对比,左侧树节点b、c、d、e亦是与右侧树每个节点对比,算法复杂度能达到O(n^2),n代表节点的个数
a->e、a->d、a->b、a->c、a->a
查找完差异后还需计算最小转换方式,这其中的原理我没仔细去看,最终达到的算法复杂度是O(n^3)
react优化的diff策略
传统diff算法复杂度达到O(n^3 )这意味着1000个节点就要进行数10亿次的比较,这是非常消耗性能的。react大胆的将diff的复杂度从O(n^3)降到了O(n),他是如何做到的呢
- 由于web UI中跨级移动操作非常少、可以忽略不计,所以react实现的diff是同层级比较

拥有相同类型的两个组件产生的DOM结构也是相似的,不同类型的两个组件产生的DOM结构则不近相同
对于同一层级的一组子节点,通过分配唯一的key进行区分
react虚拟节点
dom中没有直接提供api让我们获取一棵树结构,这里我们自己构建一个虚拟的dom结构,遍历这样的数据结构是一件很轻松直观的事情。
对于下面的dom,可以用js构造出一个简单的虚拟dom
1 | <div className="myDiv"> |
1 | { |
先序深度优先遍历
首先要遍历新旧两棵树,采用深度优先策略,为树的每个节点标示唯一一个id

在遍历过程中,对比新旧节点,将差异记录下来,记录差异的方式后面会提到
1 | //若新旧树节点只是位置不同,移动 |
差异类型
上面代码中,将所有的差异保存在了patches对象中,会有如下几种差异类型:
- 插入:
patches[0]: {type:'INSERT_MARKUP',node: newNode } - 移动:
patches[0]: {type: 'MOVE_EXISTING'} - 删除:
patches[0]: {type: 'REMOVE_NODE'} - 文本内容改变:
patches[0]: {type: 'TEXT_CONTENT',content: 'virtual DOM2'} - 属性改变:
patches[0]: {type: 'SET_MARKUP',props: {className:''}}
列表对比
节点两两进行对比时,我们知道新节点较旧节点有什么不同。如果同一层的多个子节点进行对比,他们只是顺序不同,按照上面的算法,会先删除旧节点,再新增一个相同的节点,这可不是我们想看到的结果
实际上,react在同级节点对比时,提供了更优的算法:

首先对新集合的节点(nextChildren)进行in循环遍历,通过唯一的key(这里是变量name)可以取得新老集合中相同的节点,如果不存在,prevChildren即为undefined。如果存在相同节点,也即prevChild === nextChild,则进行移动操作,但在移动前需要将当前节点在老集合中的位置与 lastIndex 进行比较,见moveChild函数,如下图

if (child._mountIndex < lastIndex),则进行节点移动操作,否则不执行该操作。这是一种顺序优化手段,lastIndex一直在更新,表示访问过的节点在老集合中最右的位置(即最大的位置),如果新集合中当前访问的节点比lastIndex大,说明当前访问节点在老集合中就比上一个节点位置靠后,则该节点不会影响其他节点的位置,因此不用添加到差异队列中,即不执行移动操作,只有当访问的节点比lastIndex小时,才需要进行移动操作。
所以下图中只需要移动A、C

Vue优化的diff策略
既然传统diff算法性能开销如此之大,Vue做了什么优化呢?
- 跟react一样,只进行同层级比较,忽略跨级操作
react以及Vue在diff时,都是在对比虚拟dom节点,下文提到的节点都指虚拟节点。Vue是怎样描述一个节点的呢?
Vue虚拟节点
1 | // body下的 <div id="v" class="classA"><div> 对应的 oldVnode 就是 |
patch
diff时调用patch函数,patch接收两个参数vnode,oldVnode,分别代表新旧节点。
1 | function patch (oldVnode, vnode) { |
patch函数内第一个if判断sameVnode(oldVnode, vnode)就是判断这两个节点是否为同一类型节点,以下是它的实现:
1 | function sameVnode(oldVnode, vnode){ |
也就是说,即便同一个节点元素比如div,他的className不同,Vue就认为是两个不同类型的节点,执行删除旧节点、插入新节点操作。这与react diff实现是不同的,react对于同一个节点元素认为是同一类型节点,只更新其节点上的属性。
patchVnode
对于同类型节点调用patchVnode(oldVnode, vnode)进一步比较:
1 | patchVnode (oldVnode, vnode) { |
updateChildren
patchVnode中有一个重要的概念updateChildren,这是Vue diff实现的核心:
1 | updateChildren (parentElm, oldCh, newCh) { |

过程可以概括为:oldCh和newCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和newCh至少有一个已经遍历完了,就会结束比较。
这种由两端至中间的对比方法与react的updateChildren实现也是不同,后者是从左至右依次进行对比,各有优点。
比如一个集合,只是把最后一个节点移到了第一个,react实现就出现了短板,react会依次移动前三个节点到对应的位置:
{kind=link}
而Vue会在首尾对比时,只移动最后一个节点到第一位即可
vue的diff算法和react的diff算法的区别
vue和react的diff算法,都是忽略跨级比较,只做同级比较。vue diff时调动patch函数,参数是vnode和oldVnode,分别代表新旧节点。
vue对比节点。当节点元素相同,但是classname不同,认为是不同类型的元素,删除重建,而react认为是同类型节点,只是修改节点属性。
vue的列表对比,采用的是两端到中间比对的方式,而react采用的是从左到右依次对比的方式。当一个集合只是把最后一个节点移到了第一个,react会把前面的节点依次移动,而vue只会把最后一个节点移到第一个。总体上,vue的方式比较高效。
axios的特点有哪些?
- Axios 是一个基于 promise 的 HTTP 库,支持promise所有的API
- 它可以拦截请求和响应
- 它可以转换请求数据和响应数据,并对响应回来的内容自动转换成 JSON类型的数据
- 安全性更高,客户端支持防御 XSRF
axios有哪些常用方法?
- axios.get(url[, config]) //get请求用于列表和信息查询
- axios.delete(url[, config]) //删除
- axios.post(url[, data[, config]]) //post请求用于信息的添加
- axios.put(url[, data[, config]]) //更新操作
说下你了解的axios相关配置属性?
url 是用于请求的服务器URL
method 是创建请求时使用的方法,默认是get
baseURL 将自动加在 url 前面,除非 url 是一个绝对URL。它可以通过设置一个 baseURL 便于为axios实例的方法传递相对URL
transformRequest 允许在向服务器发送前,修改请求数据,只能用在’PUT’,’POST’和’PATCH’这几个请求方法
headers 是即将被发送的自定义请求头
1 | headers:{'X-Requested-With':'XMLHttpRequest'}, |
params 是即将与请求一起发送的URL参数,必须是一个无格式对象(plainobject)或URLSearchParams对象
1 | params:{ |
auth 表示应该使用HTTP基础验证,并提供凭据
这将设置一个 Authorization 头,覆写掉现有的任意使用 headers 设置的自定义 Authorization 头
1 | auth:{ |
‘proxy’定义代理服务器的主机名称和端口auth 表示HTTP基础验证应当用于连接代理,并提供凭据
这将会设置一个 Proxy-Authorization 头,覆写掉已有的通过使用 header 设置的自定义 Proxy-Authorization 头。
1 | proxy:{ |
事件机制
1.1 事件触发三阶段
- document 往事件触发处传播,遇到注册的捕获事件会触发
- 传播到事件触发处时触发注册的事件
- 从事件触发处往 document 传播,遇到注册的冒泡事件会触发
事件触发一般来说会按照上面的顺序进行,但是也有特例,如果给一个目标节点同时注册冒泡和捕获事件,事件触发会按照注册的顺序执行
1 | // 以下会先打印冒泡然后是捕获 |
1.2 注册事件
- 通常我们使用
addEventListener注册事件,该函数的第三个参数可以是布尔值,也可以是对象。对于布尔值useCapture参数来说,该参数默认值为false。useCapture决定了注册的事件是捕获事件还是冒泡事件 - 一般来说,我们只希望事件只触发在目标上,这时候可以使用
stopPropagation来阻止事件的进一步传播。通常我们认为stopPropagation是用来阻止事件冒泡的,其实该函数也可以阻止捕获事件。stopImmediatePropagation同样也能实现阻止事件,但是还能阻止该事件目标执行别的注册事件
1 | node.addEventListener('click',(event) =>{ |
1.3 事件代理
如果一个节点中的子节点是动态生成的,那么子节点需要注册事件的话应该注册在父节点上
1 | <ul id="ul"> |
事件代理的方式相对于直接给目标注册事件来说,有以下优点
- 节省内存
- 不需要给子节点注销事件
跨域
因为浏览器出于安全考虑,有同源策略。也就是说,如果协议、域名或者端口有一个不同就是跨域,Ajax 请求会失败
2.1 JSONP
JSONP 的原理很简单,就是利用
<script>标签没有跨域限制的漏洞。通过<script>标签指向一个需要访问的地址并提供一个回调函数来接收数据当需要通讯时
1 | <script src="http://domain/api?param1=a¶m2=b&callback=jsonp"></script> |
- JSONP 使用简单且兼容性不错,但是只限于 get 请求
2.2 CORS
CORS需要浏览器和后端同时支持- 浏览器会自动进行
CORS通信,实现CORS通信的关键是后端。只要后端实现了CORS,就实现了跨域。 - 服务端设置
Access-Control-Allow-Origin就可以开启CORS。 该属性表示哪些域名可以访问资源,如果设置通配符则表示所有网站都可以访问资源
2.3 document.domain
- 该方式只能用于二级域名相同的情况下,比如
a.test.com和b.test.com适用于该方式。 - 只需要给页面添加
document.domain = 'test.com'表示二级域名都相同就可以实现跨域
2.4 postMessage
这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
1 | // 发送消息端 |
前端错误监控
1 前言
错误监控包含的内容是:
- 前端错误的分类
- 每种错误的捕获方式
- 上报错误的基本原理
面试时,可能有两种问法:
- 如何监测
js错误?(开门见山的方式) - 如何保证产品质量?(其实问的也是错误监控)
2 前端错误的分类
包括两种:
- 即时运行错误(代码错误)
- 资源加载错误
3 每种错误的捕获方式
3.1 即时运行错误的捕获方式
方式1:try ... catch。
这种方式要部署在代码中。
方式2:window.onerror函数。这个函数是全局的。
1 | window.onerror = function(msg, url, row, col, error) { ... } |
参数解释:
msg为异常基本信息source为发生异常Javascript文件的urlrow为发生错误的行号
方式二中的
window.onerror是属于DOM0的写法,我们也可以用DOM2的写法:window.addEventListener("error", fn);也可以。
问题延伸1:
window.onerror默认无法捕获跨域的js运行错误。捕获出来的信息如下:(基本属于无效信息)
比如说,我们的代码想引入
B网站的b.js文件,怎么捕获它的异常呢?
解决办法:在方法二的基础之上,做如下操作:
- 在
b.js文件里,加入如下responseheader,表示允许跨域:(或者世界给静态资源b.js加这个 response header)
1 | Access-Control-Allow-Origin: * |
- 引入第三方的文件
b.js时,在<script>标签中增加crossorigin属性;
问题延伸2:
只靠方式二中的
window.onerror是不够的,因为我们无法获取文件名是什么,不知道哪里出了错误。解决办法:把堆栈信息作为msg打印出来,堆栈里很详细。
3.2 资源加载错误的捕获方式
上面的
window.onerror只能捕获即时运行错误,无法捕获资源加载错误。原理是:资源加载错误,并不会向上冒泡,object.onerror捕获后就会终止(不会冒泡给window),所以window.onerror并不能捕获资源加载错误。
- 方式1:
object.onerror。img标签、script标签等节点都可以添加onerror事件,用来捕获资源加载的错误。 - 方式2:performance.getEntries。可以获取所有已加载资源的加载时长,通过这种方式,可以间接的拿到没有加载的资源错误。
举例:
浏览器打开一个网站,在
Console控制台下,输入:
1 | performance.getEntries().forEach(function(item){console.log(item.name)}) |
或者输入:
1 | performance.getEntries().forEach(item=>{console.log(item.name)}) |
上面这个
api,返回的是数组,既然是数组,就可以用forEach遍历。打印出来的资源就是已经成功加载的资源。;

再入
document.getElementsByTagName('img'),就会显示出所有需要加载的的img集合。
于是,
document.getElementsByTagName('img')获取的资源数组减去通过performance.getEntries()获取的资源数组,剩下的就是没有成功加载的,这种方式可以间接捕获到资源加载错误。
这种方式非常有用,一定要记住。
方式3;Error事件捕获。
源加载错误,虽然会阻止冒泡,但是不会阻止捕获。我们可以在捕获阶段绑定error事件。例如:

总结:如果我们能回答出后面的两种方式,面试官对我们的印象会大大增加。既可以体现出我们对错误监控的了解,还可以体现出我们对事件模型的掌握。
4 错误上报的两种方式
- 方式一:采用Ajax通信的方式上报(此方式虽然可以上报错误,但是我们并不采用这种方式)
- 方式二:利用Image对象上报(推荐。网站的监控体系都是采用的这种方式)
方式二的实现方式如下:
1 |
|
打开浏览器,效果如下:

上图中,红色那一栏表明,我的请求已经发出去了。点进去看看:

这种方式,不需要借助第三方的库,一行代码即可搞定。
HTML
语义化
HTML标签的语义化是指:通过使用包含语义的标签(如h1-h6)恰当地表示文档结构
css命名的语义化是指:为html标签添加有意义的class
为什么需要语义化:
- 去掉样式后页面呈现清晰的结构
- 盲人使用读屏器更好地阅读
- 搜索引擎更好地理解页面,有利于收录
- 便团队项目的可持续运作及维护
简述一下你对HTML语义化的理解?
- 用正确的标签做正确的事情。
- html语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析;
- 即使在没有样式CSS情况下也以一种文档格式显示,并且是容易阅读的;
- 搜索引擎的爬虫也依赖于HTML标记来确定上下文和各个关键字的权重,利于SEO;
- 使阅读源代码的人对网站更容易将网站分块,便于阅读维护理解
Doctype作用?标准模式与兼容模式各有什么区别?
<!DOCTYPE>声明位于位于HTML文档中的第一行,处于<html>标签之前。告知浏览器的解析器用什么文档标准解析这个文档。DOCTYPE不存在或格式不正确会导致文档以兼容模式呈现- 标准模式的排版 和JS运作模式都是以该浏览器支持的最高标准运行。在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作
HTML5 为什么只需要写 ?
- HTML5 不基于 SGML,因此不需要对DTD进行引用,但是需要doctype来规范浏览器的行为(让浏览器按照它们应该的方式来运行)
- 而HTML4.01基于SGML,所以需要对DTD进行引用,才能告知浏览器文档所使用的文档类型
行内元素有哪些?块级元素有哪些? 空(void)元素有那些?
- 行内元素有:
a b span img input select strong(强调的语气) - 块级元素有:
div ul ol li dl dt dd h1 h2 h3 h4…p - 常见的空元素:
<br> <hr> <img> <input> <link> <meta>
页面导入样式时,使用link和@import有什么区别?
link属于XHTML标签,除了加载CSS外,还能用于定义RSS,定义rel连接属性等作用;而@import是CSS提供的,只能用于加载CSS- 页面被加载的时,
link会同时被加载,而@import引用的CSS会等到页面被加载完再加载 import是CSS2.1提出的,只在IE5以上才能被识别,而link是XHTML标签,无兼容问题
介绍一下你对浏览器内核的理解?
主要分成两部分:渲染引擎(
layout engineer或Rendering Engine)和JS引擎渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核
JS引擎则:解析和执行javascript来实现网页的动态效果
最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎
常见的浏览器内核有哪些?
Trident内核:IE,MaxThon,TT,The World,360,搜狗浏览器等。[又称MSHTML]Gecko内核:Netscape6及以上版本,FF,MozillaSuite/SeaMonkey等Presto内核:Opera7及以上。 [Opera内核原为:Presto,现为:Blink;]Webkit内核:Safari,Chrome等。 [Chrome的Blink(WebKit的分支)]
html5有哪些新特性、移除了那些元素?如何处理HTML5新标签的浏览器兼容问题?如何区分 HTML 和 HTML5?
HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加
- 绘画 canvas
- 用于媒介回放的 video 和 audio 元素
- 本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失
- sessionStorage 的数据在浏览器关闭后自动删除
- 语意化更好的内容元素,比如 article、footer、header、nav、section
- 表单控件,calendar、date、time、email、url、search
- 新的技术webworker, websocket, Geolocation
移除的元素:
- 纯表现的元素:basefont,big,center,font, s,strike,tt,u
- 对可用性产生负面影响的元素:frame,frameset,noframes
支持HTML5新标签:
- IE8/IE7/IE6支持通过document.createElement方法产生的标签
- 可以利用这一特性让这些浏览器支持HTML5新标签
- 浏览器支持新标签后,还需要添加标签默认的样式
当然也可以直接使用成熟的框架、比如html5shim
1 | <!--[if lt IE 9]> |
- 如何区分HTML5: DOCTYPE声明\新增的结构元素\功能元素
HTML5的离线储存怎么使用,工作原理能不能解释一下?
在用户没有与因特网连接时,可以正常访问站点或应用,在用户与因特网连接时,更新用户机器上的缓存文件
原理:HTML5的离线存储是基于一个新建的.appcache文件的缓存机制(不是存储技术),通过这个文件上的解析清单离线存储资源,这些资源就会像cookie一样被存储了下来。之后当网络在处于离线状态下时,浏览器会通过被离线存储的数据进行页面展示
如何使用:
- 页面头部像下面一样加入一个manifest的属性;
- 在cache.manifest文件的编写离线存储的资源
- 在离线状态时,操作window.applicationCache进行需求实现
1
2
3
4
5
6
7
8
9CACHE MANIFEST
#v0.11
CACHE:
js/app.js
css/style.css
NETWORK:
resourse/logo.png
FALLBACK:
/ /offline.html
浏览器是怎么对HTML5的离线储存资源进行管理和加载的呢?
在线的情况下,浏览器发现html头部有manifest属性,它会请求manifest文件,如果是第一次访问app,那么浏览器就会根据manifest文件的内容下载相应的资源并且进行离线存储。如果已经访问过app并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。
离线的情况下,浏览器就直接使用离线存储的资源。
请描述一下 cookies,sessionStorage 和 localStorage 的区别?
cookie是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)
cookie数据始终在同源的http请求中携带(即使不需要),记会在浏览器和服务器间来回传递
sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存存储大小:
cookie数据大小不能超过4ksessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
有期时间:
localStorage存储持久数据,浏览器关闭后数据不丢失除非主动删除数据sessionStorage数据在当前浏览器窗口关闭后自动删除cookie设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭
iframe有那些缺点?
- iframe会阻塞主页面的Onload事件
- 搜索引擎的检索程序无法解读这种页面,不利于SEO
- iframe和主页面共享连接池,而浏览器对相同域的连接有限制,所以会影响页面的并行加载
- 使用
iframe之前需要考虑这两个缺点。如果需要使用iframe,最好是通过javascript动态给iframe添加src属性值,这样可以绕开以上两个问题
Label的作用是什么?是怎么用的?
- label标签来定义表单控制间的关系,当用户选择该标签时,浏览器会自动将焦点转到和标签相关的表单控件
HTML5的form如何关闭自动完成功能?
- 给不想要提示的 form 或某个 input 设置为 autocomplete=off。
如何实现浏览器内多个标签页之间的通信? (阿里)
- WebSocket、SharedWorker
- 也可以调用localstorge、cookies等本地存储方式
webSocket如何兼容低浏览器?(阿里)
- Adobe Flash Socket 、
- ActiveX HTMLFile (IE) 、
- 基于 multipart 编码发送 XHR 、
- 基于长轮询的 XHR
页面可见性(Page Visibility API) 可以有哪些用途?
- 通过 visibilityState 的值检测页面当前是否可见,以及打开网页的时间等;
- 在页面被切换到其他后台进程的时候,自动暂停音乐或视频的播放
如何在页面上实现一个圆形的可点击区域?
- map+area或者svg
- border-radius
- 纯js实现 需要求一个点在不在圆上简单算法、获取鼠标坐标等等
实现不使用 border 画出1px高的线,在不同浏览器的标准模式与怪异模式下都能保持一致的效果
1 | <div style="height:1px;overflow:hidden;background:red"></div> |
网页验证码是干嘛的,是为了解决什么安全问题
- 区分用户是计算机还是人的公共全自动程序。可以防止恶意破解密码、刷票、论坛灌水
- 有效防止黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试
title与h1的区别、b与strong的区别、i与em的区别?
title属性没有明确意义只表示是个标题,H1则表示层次明确的标题,对页面信息的抓取也有很大的影响strong是标明重点内容,有语气加强的含义,使用阅读设备阅读网络时:<strong>会重读,而<B>是展示强调内容- i内容展示为斜体,em表示强调的文本
页面导入样式时,使用 link 和 @import 有什么区别?
- link 属于HTML标签,除了加载CSS外,还能用于定 RSS等;@import 只能用于加载CSS
- 页面加载的时,link 会同时被加载,而 @import 引用的 CSS 会等到页面被加载完再加载
- @import 只在 IE5 以上才能被识别,而 link 是HTML标签,无兼容问题
介绍一下你对浏览器内核的理解?
- 浏览器内核主要分为两部分:渲染引擎(layout engineer 或 Rendering Engine) 和 JS引擎
- 渲染引擎负责取得网页的内容进行布局计和样式渲染,然后会输出至显示器或打印机
- JS引擎则负责解析和执行JS脚本来实现网页的动态效果和用户交互
- 最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎
常见的浏览器内核有哪些?
- Blink内核:新版 Chrome、新版 Opera
- Webkit内核:Safari、原Chrome
- Gecko内核:FireFox、Netscape6及以上版本
- Trident内核(又称MSHTML内核):IE、国产浏览器
- Presto内核:原Opera7及以上
HTML5有哪些新特性?
- 新增选择器 document.querySelector、document.querySelectorAll
- 拖拽释放(Drag and drop) API
- 媒体播放的 video 和 audio
- 本地存储 localStorage 和 sessionStorage
- 离线应用 manifest
- 桌面通知 Notifications
- 语意化标签 article、footer、header、nav、section
- 增强表单控件 calendar、date、time、email、url、search
- 地理位置 Geolocation
- 多任务 webworker
- 全双工通信协议 websocket
- 历史管理 history
- 跨域资源共享(CORS) Access-Control-Allow-Origin
- 页面可见性改变事件 visibilitychange
- 跨窗口通信 PostMessage
- Form Data 对象
- 绘画 canvas
HTML5移除了那些元素?
- 纯表现的元素:basefont、big、center、font、s、strike、tt、u
- 对可用性产生负面影响的元素:frame、frameset、noframes
如何处理HTML5新标签的浏览器兼容问题?
- 通过 document.createElement 创建新标签
- 使用垫片 html5shim.js
如何区分 HTML 和 HTML5?
- DOCTYPE声明、新增的结构元素、功能元素
HTML5的离线储存工作原理能不能解释一下,怎么使用?
HTML5的离线储存原理:
- 用户在线时,保存更新用户机器上的缓存文件;当用户离线时,可以正常访离线储存问站点或应用内容
HTML5的离线储存使用:
- 在文档的 html 标签设置 manifest 属性,如 manifest=”/offline.appcache”
- 在项目中新建 manifest 文件,manifest 文件的命名建议:xxx.appcache
- 在 web 服务器配置正确的 MIME-type,即 text/cache-manifest
浏览器是怎么对HTML5的离线储存资源进行管理和加载的?
- 在线的情况下,浏览器发现 html 标签有 manifest 属性,它会请求 manifest 文件
- 如果是第一次访问app,那么浏览器就会根据 manifest 文件的内容下载相应的资源并且进行离线存储
- 如果已经访问过app且资源已经离线存储了,浏览器会对比新的 manifest 文件与旧的 manifest 文件,如果文件没有发生改变,就不做任何操作。如果文件改变了,那么就会重新下载文件中的资源并进行离线存储
- 离线的情况下,浏览器就直接使用离线存储的资源。
iframe 有那些优点和缺点?
优点:
- 用来加载速度较慢的内容(如广告)
- 可以使脚本可以并行下载
- 可以实现跨子域通信
缺点:
- iframe 会阻塞主页面的 onload 事件
- 无法被一些搜索引擎索识别
- 会产生很多页面,不容易管理
label 的作用是什么?怎么使用的?
label标签来定义表单控件的关系:
- 当用户选择label标签时,浏览器会自动将焦点转到和label标签相关的表单控件上
使用方法1:
<label for="mobile">Number:</label><input type="text" id="mobile"/>
使用方法2:
<label>Date:<input type="text"/></label>
如何实现浏览器内多个标签页之间的通信?
- iframe + contentWindow
- postMessage
- SharedWorker(Web Worker API)
- storage 事件(localStorge API)
- WebSocket
webSocket 如何兼容低浏览器?
- Adobe Flash Socket
- ActiveX HTMLFile (IE)
- 基于 multipart 编码发送 XHR
- 基于长轮询的 XHR
页面可见性(Page Visibility API) 可以有哪些用途?
- 在页面被切换到其他后台进程的时候,自动暂停音乐或视频的播放
- 当用户浏览其他页面,暂停网站首页幻灯自动播放
- 完成登陆后,无刷新自动同步其他页面的登录状态
title 与 h1 的区别、b 与 strong 的区别、i 与 em 的区别?
- title 表示是整个页面标题,h1 则表示层次明确的标题,对页面信息的抓取有很大的影响
strong是标明重点内容,有语气加强的含义,使用阅读设备阅读网络时:<strong>会重读,而<B>是展示强调内容- i内容展示为斜体,em表示强调的文本
是展示强调内容
- i 内容展示为斜体,em 表示强调的文本
- 自然样式标签:b, i, u, s, pre
- 语义样式标签:strong, em, ins, del, code
- 应该准确使用语义样式标签, 但不能滥用。如果不能确定时,首选使用自然样式标签
CSS
display: none; 与 visibility: hidden; 的区别
- 联系:它们都能让元素不可见
- 区别:
display:none;会让元素完全从渲染树中消失,渲染的时候不占据任何空间;visibility: hidden;不会让元素从渲染树消失,渲染师元素继续占据空间,只是内容不可见display: none;是非继承属性,子孙节点消失由于元素从渲染树消失造成,通过修改子孙节点属性无法显示;visibility:hidden;是继承属性,子孙节点消失由于继承了hidden,通过设置visibility: visible;可以让子孙节点显式- 修改常规流中元素的
display通常会造成文档重排。修改visibility属性只会造成本元素的重绘 - 读屏器不会读取
display: none;元素内容;会读取visibility: hidden元素内容
css hack原理及常用hack
- 原理:利用不同浏览器对CSS的支持和解析结果不一样编写针对特定浏览器样式。
- 常见的hack有
- 属性hack
- 选择器hack
- IE条件注释
link 与 @import 的区别
link是HTML方式,@import是CSS方式link最大限度支持并行下载,@import过多嵌套导致串行下载,出现FOUClink可以通过rel="alternate stylesheet"指定候选样式- 浏览器对
link支持早于@import,可以使用@import对老浏览器隐藏样式 @import必须在样式规则之前,可以在css文件中引用其他文件- 总体来说:
link优于@import
CSS有哪些继承属性
- 关于文字排版的属性如:
fontword-breakletter-spacingtext-aligntext-renderingword-spacingwhite-spacetext-indenttext-transformtext-shadow
line-heightcolorvisibilitycursor
display,float,position的关系
- 如果
display为none,那么position和float都不起作用,这种情况下元素不产生框 - 否则,如果
position值为absolute或者fixed,框就是绝对定位的,float的计算值为none,display根据下面的表格进行调整 - 否则,如果
float不是none,框是浮动的,display根据下表进行调整 - 否则,如果元素是根元素,
display根据下表进行调整 - 其他情况下
display的值为指定值 总结起来:绝对定位、浮动、根元素都需要调整display
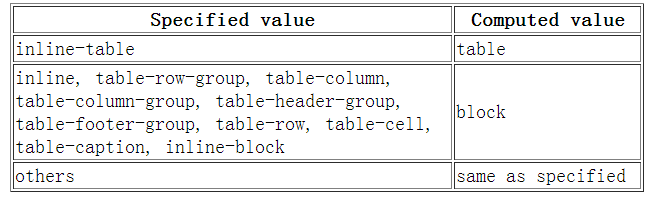
外边距折叠(collapsing margins)
- 毗邻的两个或多个
margin会合并成一个margin,叫做外边距折叠。规则如下:- 两个或多个毗邻的普通流中的块元素垂直方向上的
margin会折叠 - 浮动元素或
inline-block元素或绝对定位元素的margin不会和垂直方向上的其他元素的margin折叠 - 创建了块级格式化上下文的元素,不会和它的子元素发生margin折叠
- 元素自身的
margin-bottom和margin-top相邻时也会折
- 两个或多个毗邻的普通流中的块元素垂直方向上的
介绍一下标准的CSS的盒子模型?低版本IE的盒子模型有什么不同的?
- 有两种, IE 盒子模型、W3C 盒子模型;
- 盒模型: 内容(content)、填充(padding)、边界(margin)、 边框(border);
- 区 别: IE的content部分把 border 和 padding计算了进去;
CSS选择符有哪些?哪些属性可以继承?
id选择器( # myid)
类选择器(.myclassname)
标签选择器(div, h1, p)
相邻选择器(h1 + p)
子选择器(ul > li)
后代选择器(li a)
通配符选择器( * )
属性选择器(a[rel = “external”])
伪类选择器(a:hover, li:nth-child)
可继承的样式:
font-size font-family color, UL LI DL DD DT不可继承的样式:
border padding margin width height
CSS优先级算法如何计算?
- 优先级就近原则,同权重情况下样式定义最近者为准
- 载入样式以最后载入的定位为准
- 优先级为:
!important > id > class > tagimportant 比 内联优先级高
CSS3新增伪类有那些?
1 | p:first-of-type 选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 |
如何居中div?如何居中一个浮动元素?如何让绝对定位的div居中?
- 给
div设置一个宽度,然后添加margin:0 auto属性
1 | div{ |
- 居中一个浮动元素
1 | //确定容器的宽高 宽500 高 300 的层 |
- 让绝对定位的div居中
1 | position: absolute; |
display有哪些值?说明他们的作用
- block 象块类型元素一样显示。
- none 缺省值。象行内元素类型一样显示。
- inline-block 象行内元素一样显示,但其内容象块类型元素一样显示。
- list-item 象块类型元素一样显示,并添加样式列表标记。
- table 此元素会作为块级表格来显示
- inherit 规定应该从父元素继承 display 属性的值
position的值relative和absolute定位原点是?
- absolute
- 生成绝对定位的元素,相对于值不为 static的第一个父元素进行定位。
- fixed (老IE不支持)
- 生成绝对定位的元素,相对于浏览器窗口进行定位。
- relative
- 生成相对定位的元素,相对于其正常位置进行定位。
- static
- 默认值。没有定位,元素出现在正常的流中(忽略 top, bottom, left, right - z-index 声明)。
- inherit
- 规定从父元素继承 position 属性的值
CSS3有哪些新特性?
- 新增各种CSS选择器 (: not(.input):所有 class 不是“input”的节点)
- 圆角 (border-radius:8px)
- 多列布局 (multi-column layout)
- 阴影和反射 (Shadow\Reflect)
- 文字特效 (text-shadow、)
- 文字渲染 (Text-decoration)
- 线性渐变 (gradient)
- 旋转 (transform)
- 增加了旋转,缩放,定位,倾斜,动画,多背景
transform:\scale(0.85,0.90)\ translate(0px,-30px)\ skew(-9deg,0deg)\Animation:
用纯CSS创建一个三角形的原理是什么?
1 | // 把上、左、右三条边隐藏掉(颜色设为 transparent) |
一个满屏 品 字布局 如何设计?
- 简单的方式:
- 上面的div宽100%,
- 下面的两个div分别宽50%,
- 然后用float或者inline使其不换行即可
经常遇到的浏览器的兼容性有哪些?原因,解决方法是什么,常用hack的技巧 ?
png24位的图片在iE6浏览器上出现背景,解决方案是做成PNG8.
浏览器默认的margin和padding不同。解决方案是加一个全局的*{margin:0;padding:0;}来统一
IE下,可以使用获取常规属性的方法来获取自定义属性,也可以使用getAttribute()获取自定义属性;
Firefox下,只能使用getAttribute()获取自定义属性。
- 解决方法:统一通过getAttribute()获取自定义属性
IE下,even对象有x,y属性,但是没有pageX,pageY属性
Firefox下,event对象有pageX,pageY属性,但是没有x,y属性
li与li之间有看不见的空白间隔是什么原因引起的?有什么解决办法?
- 行框的排列会受到中间空白(回车\空格)等的影响,因为空格也属于字符,这些空白也会被应用样式,占据空间,所以会有间隔,把字符大小设为0,就没有空格了
为什么要初始化CSS样式
- 因为浏览器的兼容问题,不同浏览器对有些标签的默认值是不同的,如果没对CSS初始化往往会出现浏览器之间的页面显示差异
对BFC规范(块级格式化上下文:block formatting context)的理解?
- 一个页面是由很多个 Box 组成的,元素的类型和 display 属性,决定了这个 Box 的类型
- 不同类型的 Box,会参与不同的 Formatting Context(决定如何渲染文档的容器),因此Box内的元素会以不同的方式渲染,也就是说BFC内部的元素和外部的元素不会互相影响
css定义的权重
1 | // 以下是权重的规则:标签的权重为1,class的权重为10,id的权重为100,以下/// 例子是演示各种定义的权重值: |
display:inline-block 什么时候会显示间隙?(携程)
- 移除空格、使用margin负值、使用font-size:0、letter-spacing、word-spacing
谈谈浮动和清除浮动
- 浮动的框可以向左或向右移动,直到他的外边缘碰到包含框或另一个浮动框的边框为止。由于浮动框不在文档的普通流中,所以文档的普通流的块框表现得就像浮动框不存在一样。浮动的块框会漂浮在文档普通流的块框上
介绍一下标准的CSS的盒子模型?低版本IE的盒子模型有什么不同的?
- 盒子模型构成:内容(content)、内填充(padding)、 边框(border)、外边距(margin)
- IE8及其以下版本浏览器,未声明 DOCTYPE,内容宽高会包含内填充和边框,称为怪异盒模型(IE盒模型)
- 标准(W3C)盒模型:元素宽度 = width + padding + border + margin
- 怪异(IE)盒模型:元素宽度 = width + margin
- 标准浏览器通过设置 css3 的 box-sizing: border-box 属性,触发“怪异模式”解析计算宽高
box-sizing 常用的属性有哪些?分别有什么作用?
- box-sizing: content-box; // 默认的标准(W3C)盒模型元素效果
- box-sizing: border-box; // 触发怪异(IE)盒模型元素的效果
- box-sizing: inherit; // 继承父元素 box-sizing 属性的值
CSS选择器有哪些?
- id选择器 #id
- 类选择器 .class
- 标签选择器 div, h1, p
- 相邻选择器 h1 + p
- 子选择器 ul > li
- 后代选择器 li a
- 通配符选择器 *
- 属性选择器 a[rel=’external’]
- 伪类选择器 a:hover, li:nth-child
CSS哪些属性可以继承?哪些属性不可以继承?
- 可以继承的样式:font-size、font-family、color、list-style、cursor
- 不可继承的样式:width、height、border、padding、margin、background
CSS如何计算选择器优先?
- 相同权重,定义最近者为准:行内样式 > 内部样式 > 外部样式
- 含外部载入样式时,后载入样式覆盖其前面的载入的样式和内部样式
- 选择器优先级: 行内样式[1000] > id[100] > class[10] > Tag[1]
- 在同一组属性设置中,!important 优先级最高,高于行内样式
CSS3新增伪类有哪些?
:root 选择文档的根元素,等同于 html 元素
:empty 选择没有子元素的元素
:target 选取当前活动的目标元素
:not(selector) 选择除 selector 元素意外的元素
:enabled 选择可用的表单元素
:disabled 选择禁用的表单元素
:checked 选择被选中的表单元素
:after 在元素内部最前添加内容
:before 在元素内部最后添加内容
:nth-child(n) 匹配父元素下指定子元素,在所有子元素中排序第n
:nth-last-child(n) 匹配父元素下指定子元素,在所有子元素中排序第n,从后向前数
:nth-child(odd)
:nth-child(even)
:nth-child(3n+1)
:first-child
:last-child
:only-child
:nth-of-type(n) 匹配父元素下指定子元素,在同类子元素中排序第n
:nth-last-of-type(n) 匹配父元素下指定子元素,在同类子元素中排序第n,从后向前数
:nth-of-type(odd)
:nth-of-type(even)
:nth-of-type(3n+1)
:first-of-type
:last-of-type
:only-of-type
::selection 选择被用户选取的元素部分
:first-line 选择元素中的第一行
:first-letter 选择元素中的第一个字符
请列举几种隐藏元素的方法
- visibility: hidden; 这个属性只是简单的隐藏某个元素,但是元素占用的空间任然存在
- opacity: 0; CSS3属性,设置0可以使一个元素完全透明
- position: absolute; 设置一个很大的 left 负值定位,使元素定位在可见区域之外
- display: none; 元素会变得不可见,并且不会再占用文档的空间。
- transform: scale(0); 将一个元素设置为缩放无限小,元素将不可见,元素原来所在的位置将被保留
<div hidden="hidden">HTML5属性,效果和display:none;相同,但这个属性用于记录一个元素的状态- height: 0; 将元素高度设为 0 ,并消除边框
- filter: blur(0); CSS3属性,将一个元素的模糊度设置为0,从而使这个元素“消失”在页面中
rgba() 和 opacity 的透明效果有什么不同?
- opacity 作用于元素以及元素内的所有内容(包括文字)的透明度
- rgba() 只作用于元素自身的颜色或其背景色,子元素不会继承透明效果
css 属性 content 有什么作用?
- content 属性专门应用在 before/after 伪元素上,用于插入额外内容或样式
CSS3有哪些新特性?
- 新增选择器 p:nth-child(n){color: rgba(255, 0, 0, 0.75)}
- 弹性盒模型 display: flex;
- 多列布局 column-count: 5;
- 媒体查询 @media (max-width: 480px) {.box: {column-count: 1;}}
- 个性化字体 @font-face{font-family: BorderWeb; src:url(BORDERW0.eot);}
- 颜色透明度 color: rgba(255, 0, 0, 0.75);
- 圆角 border-radius: 5px;
- 渐变 background:linear-gradient(red, green, blue);
- 阴影 box-shadow:3px 3px 3px rgba(0, 64, 128, 0.3);
- 倒影 box-reflect: below 2px;
- 文字装饰 text-stroke-color: red;
- 文字溢出 text-overflow:ellipsis;
- 背景效果 background-size: 100px 100px;
- 边框效果 border-image:url(bt_blue.png) 0 10;
- 转换
- 旋转 transform: rotate(20deg);
- 倾斜 transform: skew(150deg, -10deg);
- 位移 transform: translate(20px, 20px);
- 缩放 transform: scale(.5);
- 平滑过渡 transition: all .3s ease-in .1s;
- 动画 @keyframes anim-1 {50% {border-radius: 50%;}} animation: anim-1 1s;
请解释一下 CSS3 的 Flexbox(弹性盒布局模型)以及适用场景?
- Flexbox 用于不同尺寸屏幕中创建可自动扩展和收缩布局
经常遇到的浏览器的JS兼容性有哪些?解决方法是什么?
- 当前样式:getComputedStyle(el, null) VS el.currentStyle
- 事件对象:e VS window.event
- 鼠标坐标:e.pageX, e.pageY VS window.event.x, window.event.y
- 按键码:e.which VS event.keyCode
- 文本节点:el.textContent VS el.innerText
li与li之间有看不见的空白间隔是什么原因引起的?有什么解决办法?
- li排列受到中间空白(回车/空格)等的影响,因为空白也属于字符,会被应用样式占据空间,产生间隔
- 解决办法:在ul设置设置font-size=0,在li上设置需要的文字大小
什么是外边距重叠? 重叠的结果是什么?
外边距重叠就是 margin-collapse
相邻的两个盒子(可能是兄弟关系也可能是祖先关系)的外边距可以结合成一个单独的外边距。
这种合并外边距的方式被称为折叠,结合而成的外边距称为折叠外边距折叠结果遵循下列计算规则:
- 两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值
- 两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值
- 两个外边距一正一负时,折叠结果是两者的相加的和
请写出多种等高布局
- 在列的父元素上使用这个背景图进行Y轴的铺放,从而实现一种等高列的假像
- 模仿表格布局等高列效果:兼容性不好,在ie6-7无法正常运行
- css3 flexbox 布局: .container{display: flex; align-items: stretch;}
css垂直居中的方法有哪些?
- 如果是单行文本, line-height 设置成和 height 值
1 | .vertical { |
- 已知高度的块级子元素,采用绝对定位和负边距
1 | .container { |
- 未知高度的块级父子元素居中,模拟表格布局
- 缺点:IE67不兼容,父级 overflow:hidden 失效
1 | .container { |
- 新增 inline-block 兄弟元素,设置 vertical-align
- 缺点:需要增加额外标签,IE67不兼容
1 |
|
- 绝对定位配合 CSS3 位移
1 | .vertical { |
- CSS3弹性盒模型
1 | .container { |
圣杯布局的实现原理?
- 要求:三列布局;中间主体内容前置,且宽度自适应;两边内容定宽
- 好处:重要的内容放在文档流前面可以优先渲染
- 原理:利用相对定位、浮动、负边距布局,而不添加额外标签
1 | .container { |
什么是双飞翼布局?实现原理?
- 双飞翼布局:对圣杯布局(使用相对定位,对以后布局有局限性)的改进,消除相对定位布局
- 原理:主体元素上设置左右边距,预留两翼位置。左右两栏使用浮动和负边距归位,消除相对定位。
1 | .container { |
在CSS样式中常使用 px、em 在表现上有什么区别?
- px 相对于显示器屏幕分辨率,无法用浏览器字体放大功能
- em 值并不是固定的,会继承父级的字体大小: em = 像素值 / 父级font-size
为什么要初始化CSS样式?
- 不同浏览器对有些标签样式的默认值解析不同
- 不初始化CSS会造成各现浏览器之间的页面显示差异
- 可以使用 reset.css 或 Normalize.css 做 CSS 初始化
解释下什么是浮动和它的工作原理?
- 非IE浏览器下,容器不设高度且子元素浮动时,容器高度不能被内容撑开。
此时,内容会溢出到容器外面而影响布局。这种现象被称为浮动(溢出)。 - 工作原理:
- 浮动元素脱离文档流,不占据空间(引起“高度塌陷”现象)
- 浮动元素碰到包含它的边框或者其他浮动元素的边框停留
浮动元素引起的问题?
- 父元素的高度无法被撑开,影响与父元素同级的元素
- 与浮动元素同级的非浮动元素会跟随其后
列举几种清除浮动的方式?
- 添加额外标签,例如
<div style="clear:both"></div> - 使用 br 标签和其自身的 clear 属性,例如
<br clear="all" /> - 父元素设置 overflow:hidden; 在IE6中还需要触发 hasLayout,例如zoom:1;
- 父元素也设置浮动
- 使用 :after 伪元素。由于IE6-7不支持 :after,使用 zoom:1 触发 hasLayout
清除浮动最佳实践(after伪元素闭合浮动):
1 | .clearfix:after{ |
什么是 FOUC(Flash of Unstyled Content)? 如何来避免 FOUC?
- 当使用 @import 导入 CSS 时,会导致某些页面在 IE 出现奇怪的现象:没有样式的页面内容显示瞬间闪烁,这种现象称为“文档样式短暂失效”,简称为FOUC
- 产生原因:当样式表晚于结构性html加载时,加载到此样式表时,页面将停止之前的渲染。等待此样式表被下载和解析后,再重新渲染页面,期间导致短暂的花屏现象。
- 解决方法:使用 link 标签将样式表放在文档 head
介绍使用过的 CSS 预处理器?
- CSS 预处理器基本思想:为 CSS 增加了一些编程的特性(变量、逻辑判断、函数等)
- 开发者使用这种语言进行进行 Web 页面样式设计,再编译成正常的 CSS 文件使用
- 使用 CSS 预处理器,可以使 CSS 更加简洁、适应性更强、可读性更佳,无需考虑兼容性
- 最常用的 CSS 预处理器语言包括:Sass(SCSS)和 LESS
CSS优化、提高性能的方法有哪些?
- 多个css合并,尽量减少HTTP请求
- 将css文件放在页面最上面
- 移除空的css规则
- 避免使用CSS表达式
- 选择器优化嵌套,尽量避免层级过深
- 充分利用css继承属性,减少代码量
- 抽象提取公共样式,减少代码量
- 属性值为0时,不加单位
- 属性值为小于1的小数时,省略小数点前面的0
- css雪碧图
浏览器是怎样解析CSS选择器的?
- 浏览器解析 CSS 选择器的方式是从右到左
在网页中的应该使用奇数还是偶数的字体?
- 在网页中的应该使用“偶数”字体:
- 偶数字号相对更容易和 web 设计的其他部分构成比例关系
- 使用奇数号字体时文本段落无法对齐
- 宋体的中文网页排布中使用最多的就是 12 和 14
margin和padding分别适合什么场景使用?
- 需要在border外侧添加空白,且空白处不需要背景(色)时,使用 margin
- 需要在border内测添加空白,且空白处需要背景(色)时,使用 padding
抽离样式模块怎么写,说出思路?
- CSS可以拆分成2部分:公共CSS 和 业务CSS:
- 网站的配色,字体,交互提取出为公共CSS。这部分CSS命名不应涉及具体的业务
- 对于业务CSS,需要有统一的命名,使用公用的前缀。可以参考面向对象的CSS
元素竖向的百分比设定是相对于容器的高度吗?
- 元素竖向的百分比设定是相对于容器的宽度,而不是高度
全屏滚动的原理是什么? 用到了CSS的那些属性?
- 原理类似图片轮播原理,超出隐藏部分,滚动时显示
- 可能用到的CSS属性:overflow:hidden; transform:translate(100%, 100%); display:none;
什么是响应式设计?响应式设计的基本原理是什么?如何兼容低版本的IE?
- 响应式设计就是网站能够兼容多个终端,而不是为每个终端做一个特定的版本
- 基本原理是利用CSS3媒体查询,为不同尺寸的设备适配不同样式
- 对于低版本的IE,可采用JS获取屏幕宽度,然后通过resize方法来实现兼容:
1 | $(window).resize(function () { |
什么是视差滚动效果,如何给每页做不同的动画?
视差滚动是指多层背景以不同的速度移动,形成立体的运动效果,具有非常出色的视觉体验
一般把网页解剖为:背景层、内容层和悬浮层。当滚动鼠标滚轮时,各图层以不同速度移动,形成视差的
实现原理
- 以 “页面滚动条” 作为 “视差动画进度条”
- 以 “滚轮刻度” 当作 “动画帧度” 去播放动画的
- 监听 mousewheel 事件,事件被触发即播放动画,实现“翻页”效果
a标签上四个伪类的执行顺序是怎么样的?
link > visited > hover > active
- L-V-H-A love hate 用喜欢和讨厌两个词来方便记忆
伪元素和伪类的区别和作用?
- 伪元素 – 在内容元素的前后插入额外的元素或样式,但是这些元素实际上并不在文档中生成。
- 它们只在外部显示可见,但不会在文档的源代码中找到它们,因此,称为“伪”元素。例如:
1 | p::before {content:"第一章:";} |
- 伪类 – 将特殊的效果添加到特定选择器上。它是已有元素上添加类别的,不会产生新的元素。例如:
1 | a:hover {color: #FF00FF} |
::before 和 :after 中双冒号和单冒号有什么区别?
- 在 CSS 中伪类一直用 : 表示,如 :hover, :active 等
- 伪元素在CSS1中已存在,当时语法是用 : 表示,如 :before 和 :after
- 后来在CSS3中修订,伪元素用 :: 表示,如 ::before 和 ::after,以此区分伪元素和伪类
- 由于低版本IE对双冒号不兼容,开发者为了兼容性各浏览器,继续使使用 :after 这种老语法表示伪元素
- 综上所述:::before 是 CSS3 中写伪元素的新语法; :after 是 CSS1 中存在的、兼容IE的老语法
如何修改Chrome记住密码后自动填充表单的黄色背景?
- 产生原因:由于Chrome默认会给自动填充的input表单加上 input:-webkit-autofill 私有属性造成的
- 解决方案1:在form标签上直接关闭了表单的自动填充:autocomplete=”off”
- 解决方案2:input:-webkit-autofill { background-color: transparent; }
input [type=search] 搜索框右侧小图标如何美化?
1 | input[type="search"]::-webkit-search-cancel-button{ |
网站图片文件,如何点击下载?而非点击预览?
<a href="logo.jpg" download>下载</a><a href="logo.jpg" download="网站LOGO" >下载</a>
iOS safari 如何阻止“橡皮筋效果”?
1 | $(document).ready(function(){ |
你对 line-height 是如何理解的?
- line-height 指一行字的高度,包含了字间距,实际上是下一行基线到上一行基线距离
- 如果一个标签没有定义 height 属性,那么其最终表现的高度是由 line-height 决定的
- 一个容器没有设置高度,那么撑开容器高度的是 line-height 而不是容器内的文字内容
- 把 line-height 值设置为 height 一样大小的值可以实现单行文字的垂直居中
- line-height 和 height 都能撑开一个高度,height 会触发 haslayout,而 line-height 不会
line-height 三种赋值方式有何区别?(带单位、纯数字、百分比)
- 带单位:px 是固定值,而 em 会参考父元素 font-size 值计算自身的行高
- 纯数字:会把比例传递给后代。例如,父级行高为 1.5,子元素字体为 18px,则子元素行高为 1.5 * 18 = 27px
- 百分比:将计算后的值传递给后代
设置元素浮动后,该元素的 display 值会如何变化?
- 设置元素浮动后,该元素的 display 值自动变成 block
怎么让Chrome支持小于12px 的文字?
1 | .shrink{ |
让页面里的字体变清晰,变细用CSS怎么做?(IOS手机浏览器字体齿轮设置)
1 | -webkit-font-smoothing: antialiased; |
font-style 属性 oblique 是什么意思?
- font-style: oblique; 使没有 italic 属性的文字实现倾斜
如果需要手动写动画,你认为最小时间间隔是多久?
- 16.7ms 多数显示器默认频率是60Hz,即1秒刷新60次,所以理论上最小间隔: 1s / 60 * 1000 = 16.7ms
display:inline-block 什么时候会显示间隙?
- 相邻的 inline-block 元素之间有换行或空格分隔的情况下会产生间距
- 非 inline-block 水平元素设置为 inline-block 也会有水平间距
- 可以借助 vertical-align:top; 消除垂直间隙
- 可以在父级加 font-size:0; 在子元素里设置需要的字体大小,消除垂直间隙
- 把 li 标签写到同一行可以消除垂直间隙,但代码可读性差
overflow: scroll 时不能平滑滚动的问题怎么处理?
- 监听滚轮事件,然后滚动到一定距离时用 jquery 的 animate 实现平滑效果。
一个高度自适应的div,里面有两个div,一个高度100px,希望另一个填满剩下的高度
- 方案1:
.sub { height: calc(100%-100px); } - 方案2:
.container { position:relative; }
.sub { position: absolute; top: 100px; bottom: 0; } - 方案3:
.container { display:flex; flex-direction:column; }
.sub { flex:1; }
JavaScript
JavaScript的组成
- JavaScript 由以下三部分组成:
- ECMAScript(核心):JavaScript 语言基础
- DOM(文档对象模型):规定了访问HTML和XML的接口
- BOM(浏览器对象模型):提供了浏览器窗口之间进行交互的对象和方法
JS的基本数据类型和引用数据类型
- 基本数据类型:undefined、null、boolean、number、string、symbol
- 引用数据类型:object、array、function
检测浏览器版本版本有哪些方式?
- 根据 navigator.userAgent // UA.toLowerCase().indexOf(‘chrome’)
- 根据 window 对象的成员 // ‘ActiveXObject’ in window
介绍JS有哪些内置对象?
- 数据封装类对象:Object、Array、Boolean、Number、String
- 其他对象:Function、Arguments、Math、Date、RegExp、Error
- ES6新增对象:Symbol、Map、Set、Promises、Proxy、Reflect
说几条写JavaScript的基本规范?
- 代码缩进,建议使用“四个空格”缩进
- 代码段使用花括号{}包裹
- 语句结束使用分号;
- 变量和函数在使用前进行声明
- 以大写字母开头命名构造函数,全大写命名常量
- 规范定义JSON对象,补全双引号
- 用{}和[]声明对象和数组
如何编写高性能的JavaScript?
- 遵循严格模式:”use strict”;
- 将js脚本放在页面底部,加快渲染页面
- 将js脚本将脚本成组打包,减少请求
- 使用非阻塞方式下载js脚本
- 尽量使用局部变量来保存全局变量
- 尽量减少使用闭包
- 使用 window 对象属性方法时,省略 window
- 尽量减少对象成员嵌套
- 缓存 DOM 节点的访问
- 通过避免使用 eval() 和 Function() 构造器
- 给 setTimeout() 和 setInterval() 传递函数而不是字符串作为参数
- 尽量使用直接量创建对象和数组
- 最小化重绘(repaint)和回流(reflow)
描述浏览器的渲染过程,DOM树和渲染树的区别?
浏览器的渲染过程:
- 解析HTML构建 DOM(DOM树),并行请求 css/image/js
- CSS 文件下载完成,开始构建 CSSOM(CSS树)
- CSSOM 构建结束后,和 DOM 一起生成 Render Tree(渲染树)
- 布局(Layout):计算出每个节点在屏幕中的位置
- 显示(Painting):通过显卡把页面画到屏幕上
DOM树 和 渲染树 的区别:
- DOM树与HTML标签一一对应,包括head和隐藏元素
- 渲染树不包括head和隐藏元素,大段文本的每一个行都是独立节点,每一个节点都有对应的css属性
重绘和回流(重排)的区别和关系?
- 重绘:当渲染树中的元素外观(如:颜色)发生改变,不影响布局时,产生重绘
- 回流:当渲染树中的元素的布局(如:尺寸、位置、隐藏/状态状态)发生改变时,产生重绘回流
- 注意:JS获取Layout属性值(如:offsetLeft、scrollTop、getComputedStyle等)也会引起回流。因为浏览器需要通过回流计算最新值
- 回流必将引起重绘,而重绘不一定会引起回流
如何最小化重绘(repaint)和回流(reflow)?
- 需要要对元素进行复杂的操作时,可以先隐藏(display:”none”),操作完成后再显示
- 需要创建多个DOM节点时,使用DocumentFragment创建完后一次性的加入document
- 缓存Layout属性值,如:var left = elem.offsetLeft; 这样,多次使用 left 只产生一次回流
- 尽量避免用table布局(table元素一旦触发回流就会导致table里所有的其它元素回流)
- 避免使用css表达式(expression),因为每次调用都会重新计算值(包括加载页面)
- 尽量使用 css 属性简写,如:用 border 代替 border-width, border-style, border-color
- 批量修改元素样式:elem.className 和 elem.style.cssText 代替 elem.style.xxx
script 的位置是否会影响首屏显示时间?
- 在解析 HTML 生成 DOM 过程中,js 文件的下载是并行的,不需要 DOM 处理到 script 节点。因此,script的位置不影响首屏显示的开始时间。
- 浏览器解析 HTML 是自上而下的线性过程,script作为 HTML 的一部分同样遵循这个原则
- 因此,script 会延迟 DomContentLoad,只显示其上部分首屏内容,从而影响首屏显示的完成时间
解释JavaScript中的作用域与变量声明提升?
JavaScript作用域:
- 在Java、C等语言中,作用域为for语句、if语句或{}内的一块区域,称为作用域;
- 而在 JavaScript 中,作用域为function(){}内的区域,称为函数作用域。
JavaScript变量声明提升:
- 在JavaScript中,函数声明与变量声明经常被JavaScript引擎隐式地提升到当前作用域的顶部。
- 声明语句中的赋值部分并不会被提升,只有名称被提升
- 函数声明的优先级高于变量,如果变量名跟函数名相同且未赋值,则函数声明会覆盖变量声明
- 如果函数有多个同名参数,那么最后一个参数(即使没有定义)会覆盖前面的同名参数
介绍JavaScript的原型,原型链?有什么特点?
原型:
- JavaScript的所有对象中都包含了一个
[__proto__]内部属性,这个属性所对应的就是该对象的原型 - JavaScript的函数对象,除了原型
[__proto__]之外,还预置了 prototype 属性 - 当函数对象作为构造函数创建实例时,该 prototype 属性值将被作为实例对象的原型
[__proto__]。
- JavaScript的所有对象中都包含了一个
原型链:
- 当一个对象调用的属性/方法自身不存在时,就会去自己
[__proto__]关联的前辈 prototype 对象上去找 - 如果没找到,就会去该 prototype 原型
[__proto__]关联的前辈 prototype 去找。依次类推,直到找到属性/方法或 undefined 为止。从而形成了所谓的“原型链”
- 当一个对象调用的属性/方法自身不存在时,就会去自己
原型特点:
- JavaScript对象是通过引用来传递的,当修改原型时,与之相关的对象也会继承这一改变
JavaScript有几种类型的值?,你能画一下他们的内存图吗
- 原始数据类型(Undefined,Null,Boolean,Number、String)– 栈
- 引用数据类型(对象、数组和函数)– 堆
- 两种类型的区别是:存储位置不同:
- 原始数据类型是直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据;
- 引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定,如果存储在栈中,将会影响程序运行的性能;
- 引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。
- 当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
JavaScript如何实现一个类,怎么实例化这个类?
- 构造函数法(this + prototype) – 用 new 关键字 生成实例对象
- 缺点:用到了 this 和 prototype,编写复杂,可读性差
1 | function Mobile(name, price){ |
- Object.create 法 – 用 Object.create() 生成实例对象
- 缺点:不能实现私有属性和私有方法,实例对象之间也不能共享数据
1 | var Person = { |
- 极简主义法(消除 this 和 prototype) – 调用 createNew() 得到实例对象
- 优点:容易理解,结构清晰优雅,符合传统的”面向对象编程”的构造
1 | var Cat = { |
- ES6 语法糖 class – 用 new 关键字 生成实例对象
1 | class Point { |
Javascript如何实现继承?
- 构造函数绑定:使用 call 或 apply 方法,将父对象的构造函数绑定在子对象上
1 | function Cat(name,color){ |
- 实例继承:将子对象的 prototype 指向父对象的一个实例
1 | Cat.prototype = new Animal(); |
- 拷贝继承:如果把父对象的所有属性和方法,拷贝进子对象
1 | function extend(Child, Parent) { |
- 原型继承:将子对象的 prototype 指向父对象的 prototype
1 | function extend(Child, Parent) { |
- ES6 语法糖 extends:class ColorPoint extends Point {}
1 | class ColorPoint extends Point { |
Javascript作用链域?
- 全局函数无法查看局部函数的内部细节,但局部函数可以查看其上层的函数细节,直至全局细节
- 如果当前作用域没有找到属性或方法,会向上层作用域查找,直至全局函数,这种形式就是作用域链
谈谈this对象的理解
- this 总是指向函数的直接调用者
- 如果有 new 关键字,this 指向 new 出来的实例对象
- 在事件中,this指向触发这个事件的对象
- IE下 attachEvent 中的this总是指向全局对象Window
eval是做什么的?
eval的功能是把对应的字符串解析成JS代码并运行
- 应该避免使用eval,不安全,非常耗性能(先解析成js语句,再执行)
- 由JSON字符串转换为JSON对象的时候可以用 eval(‘(‘+ str +’)’);
什么是 Window 对象? 什么是 Document 对象?
- Window 对象表示当前浏览器的窗口,是JavaScript的顶级对象。
- 我们创建的所有对象、函数、变量都是 Window 对象的成员。
- Window 对象的方法和属性是在全局范围内有效的。
- Document 对象是 HTML 文档的根节点与所有其他节点(元素节点,文本节点,属性节点, 注释节点)
- Document 对象使我们可以通过脚本对 HTML 页面中的所有元素进行访问
- Document 对象是 Window 对象的一部分,可通过 window.document 属性对其进行访问
介绍 DOM 的发展
- DOM:文档对象模型(Document Object Model),定义了访问HTML和XML文档的标准,与编程语言及平台无关
- DOM0:提供了查询和操作Web文档的内容API。未形成标准,实现混乱。如:document.forms[‘login’]
- DOM1:W3C提出标准化的DOM,简化了对文档中任意部分的访问和操作。如:JavaScript中的Document对象
- DOM2:原来DOM基础上扩充了鼠标事件等细分模块,增加了对CSS的支持。如:getComputedStyle(elem, pseudo)
- DOM3:增加了XPath模块和加载与保存(Load and Save)模块。如:XPathEvaluator
介绍DOM0,DOM2,DOM3事件处理方式区别
- DOM0级事件处理方式:
btn.onclick = func;btn.onclick = null;
- DOM2级事件处理方式:
btn.addEventListener('click', func, false);btn.removeEventListener('click', func, false);btn.attachEvent("onclick", func);btn.detachEvent("onclick", func);
- DOM3级事件处理方式:
eventUtil.addListener(input, "textInput", func);eventUtil是自定义对象,textInput是DOM3级事件
事件的三个阶段
- 捕获、目标、冒泡
介绍事件“捕获”和“冒泡”执行顺序和事件的执行次数?
- 按照W3C标准的事件:首是进入捕获阶段,直到达到目标元素,再进入冒泡阶段
- 事件执行次数(DOM2-addEventListener):元素上绑定事件的个数
- 注意1:前提是事件被确实触发
- 注意2:事件绑定几次就算几个事件,即使类型和功能完全一样也不会“覆盖”
- 事件执行顺序:判断的关键是否目标元素
- 非目标元素:根据W3C的标准执行:捕获->目标元素->冒泡(不依据事件绑定顺序)
- 目标元素:依据事件绑定顺序:先绑定的事件先执行(不依据捕获冒泡标准)
- 最终顺序:父元素捕获->目标元素事件1->目标元素事件2->子元素捕获->子元素冒泡->父元素冒泡
- 注意:子元素事件执行前提 事件确实“落”到子元素布局区域上,而不是简单的具有嵌套关系
在一个DOM上同时绑定两个点击事件:一个用捕获,一个用冒泡。事件会执行几次,先执行冒泡还是捕获?
- 该DOM上的事件如果被触发,会执行两次(执行次数等于绑定次数)
- 如果该DOM是目标元素,则按事件绑定顺序执行,不区分冒泡/捕获
- 如果该DOM是处于事件流中的非目标元素,则先执行捕获,后执行冒泡
事件的代理/委托
- 事件委托是指将事件绑定目标元素的到父元素上,利用冒泡机制触发该事件
- 优点:
- 可以减少事件注册,节省大量内存占用
- 可以将事件应用于动态添加的子元素上
- 缺点:
使用不当会造成事件在不应该触发时触发 - 示例:
- 优点:
1 | ulEl.addEventListener('click', function(e){ |
IE与火狐的事件机制有什么区别? 如何阻止冒泡?
- IE只事件冒泡,不支持事件捕获;火狐同时支持件冒泡和事件捕获
IE的事件处理和W3C的事件处理有哪些区别?
绑定事件
- W3C: targetEl.addEventListener(‘click’, handler, false);
- IE: targetEl.attachEvent(‘onclick’, handler);
删除事件
- W3C: targetEl.removeEventListener(‘click’, handler, false);
- IE: targetEl.detachEvent(event, handler);
事件对象
- W3C: var e = arguments.callee.caller.arguments[0]
- IE: window.event
事件目标
- W3C: e.target
- IE: window.event.srcElement
阻止事件默认行为
- W3C: e.preventDefault()
- IE: window.event.returnValue = false
阻止事件传播
- W3C: e.stopPropagation()
- IE: window.event.cancelBubble = true
W3C事件的 target 与 currentTarget 的区别?
- target 只会出现在事件流的目标阶段
- currentTarget 可能出现在事件流的任何阶段
- 当事件流处在目标阶段时,二者的指向相同
- 当事件流处于捕获或冒泡阶段时:currentTarget 指向当前事件活动的对象(一般为父级)
如何派发事件(dispatchEvent)?(如何进行事件广播?)
- W3C: 使用 dispatchEvent 方法
- IE: 使用 fireEvent 方法
1 | var fireEvent = function(element, event){ |
什么是函数节流?介绍一下应用场景和原理?
函数节流(throttle)是指阻止一个函数在很短时间间隔内连续调用。
只有当上一次函数执行后达到规定的时间间隔,才能进行下一次调用。
但要保证一个累计最小调用间隔(否则拖拽类的节流都将无连续效果)函数节流用于 onresize, onscroll 等短时间内会多次触发的事件
函数节流的原理:使用定时器做时间节流。
当触发一个事件时,先用 setTimout 让这个事件延迟一小段时间再执行。
如果在这个时间间隔内又触发了事件,就 clearTimeout 原来的定时器,
再 setTimeout 一个新的定时器重复以上流程。函数节流简单实现:
1 | function throttle(method, context) { |
区分什么是“客户区坐标”、“页面坐标”、“屏幕坐标”?
- 客户区坐标:鼠标指针在可视区中的水平坐标(clientX)和垂直坐标(clientY)
- 页面坐标:鼠标指针在页面布局中的水平坐标(pageX)和垂直坐标(pageY)
- 屏幕坐标:设备物理屏幕的水平坐标(screenX)和垂直坐标(screenY)
如何获得一个DOM元素的绝对位置?
- elem.offsetLeft:返回元素相对于其定位父级左侧的距离
- elem.offsetTop:返回元素相对于其定位父级顶部的距离
- elem.getBoundingClientRect():返回一个DOMRect对象,包含一组描述边框的只读属性,单位像素
分析 [‘1’, ‘2’, ‘3’].map(parseInt) 答案是多少?
- 答案:[1, NaN, NaN]
- parseInt(string, radix) 第2个参数 radix 表示进制。省略 radix 或 radix = 0,则数字将以十进制解析
- map 每次为 parseInt 传3个参数(elem, index, array),其中 index 为数组索引
- 因此,map 遍历 [“1”, “2”, “3”],相应 parseInt 接收参数如下
1 | parseInt('1', 0); // 1 |
- 所以,parseInt 参数 radix 不合法,导致返回值为 NaN
new 操作符具体干了什么?
- 创建实例对象,this 变量引用该对象,同时还继承了构造函数的原型
- 属性和方法被加入到 this 引用的对象中
- 新创建的对象由 this 所引用,并且最后隐式的返回 this
用原生JavaScript的实现过什么功能吗?
- 封装选择器、调用第三方API、设置和获取样式
解释一下这段代码的意思吗?
1 | [].forEach.call($$("*"), function(el){ |
- 解释:获取页面所有的元素,遍历这些元素,为它们添加1像素随机颜色的轮廓(outline)
$$(sel)// $$函数被许多现代浏览器命令行支持,等价于 document.querySelectorAll(sel)
[].forEach.call(NodeLists)// 使用 call 函数将数组遍历函数 forEach 应到节点元素列表
el.style.outline = "1px solid #333"// 样式 outline 位于盒模型之外,不影响元素布局位置
(1<<24)// parseInt(“ffffff”, 16) == 16777215 == 2^24 - 1 // 1<<24 == 2^24 == 16777216
Math.random()*(1<<24)// 表示一个位于 0 到 16777216 之间的随机浮点数
~~Math.random()*(1<<24)//~~作用相当于 parseInt 取整
(~~(Math.random()*(1<<24))).toString(16)// 转换为一个十六进制-
** JavaScript实现异步编程的方法?**
- 回调函数
- 事件监听
- 发布/订阅
- Promises对象
- Async函数[ES7]
web开发中会话跟踪的方法有哪些
- cookie
- session
- url重写
- 隐藏input
- ip地址
介绍js的基本数据类型
- Undefined、Null、Boolean、Number、String
介绍js有哪些内置对象?
- Object 是 JavaScript 中所有对象的父对象
- 数据封装类对象:Object、Array、Boolean、Number 和 String
- 其他对象:Function、Arguments、Math、Date、RegExp、Error
说几条写JavaScript的基本规范?
- 不要在同一行声明多个变量
- 请使用 ===/!==来比较true/false或者数值
- 使用对象字面量替代new Array这种形式
- 不要使用全局函数
- Switch语句必须带有default分支
- 函数不应该有时候有返回值,有时候没有返回值
- If语句必须使用大括号
- for-in循环中的变量 应该使用var关键字明确限定作用域,从而避免作用域污
JavaScript原型,原型链 ? 有什么特点?
每个对象都会在其内部初始化一个属性,就是prototype(原型),当我们访问一个对象的属性时
如果这个对象内部不存在这个属性,那么他就会去prototype里找这个属性,这个prototype又会有自己的prototype,于是就这样一直找下去,也就是我们平时所说的原型链的概念
关系:
instance.constructor.prototype = instance.__proto__特点:
- JavaScript对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
当我们需要一个属性的时,Javascript引擎会先看当前对象中是否有这个属性, 如果没有的
就会查找他的Prototype对象是否有这个属性,如此递推下去,一直检索到 Object 内建对象
JavaScript有几种类型的值?,你能画一下他们的内存图吗?
栈:原始数据类型(Undefined,Null,Boolean,Number、String)
堆:引用数据类型(对象、数组和函数)
两种类型的区别是:存储位置不同;
原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定,如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其
在栈中的地址,取得地址后从堆中获得实体
Javascript如何实现继承?
构造继承
原型继承
实例继承
拷贝继承
原型prototype机制或apply和call方法去实现较简单,建议使用构造函数与原型混合方式
1 | function Parent(){ |
javascript创建对象的几种方式?
javascript创建对象简单的说,无非就是使用内置对象或各种自定义对象,当然还可以用JSON;但写法有很多种,也能混合使用
- 对象字面量的方式
1 | person={firstname:"Mark",lastname:"Yun",age:25,eyecolor:"black"}; |
- 用function来模拟无参的构造函数
1 | function Person(){} |
- 用function来模拟参构造函数来实现(用this关键字定义构造的上下文属性)
1 | function Pet(name,age,hobby){ |
- 用工厂方式来创建(内置对象)
1 | var wcDog =new Object(); |
- 用原型方式来创建
1 | function Dog(){ |
- 用混合方式来创建
1 | function Car(name,price){ |
Javascript作用链域?
- 全局函数无法查看局部函数的内部细节,但局部函数可以查看其上层的函数细节,直至全局细节
- 当需要从局部函数查找某一属性或方法时,如果当前作用域没有找到,就会上溯到上层作用域查找
- 直至全局函数,这种组织形式就是作用域链
谈谈This对象的理解
- this总是指向函数的直接调用者(而非间接调用者)
- 如果有new关键字,this指向new出来的那个对象
- 在事件中,this指向触发这个事件的对象,特殊的是,IE中的attachEvent中的this总是指向全局对象Window
eval是做什么的?
- 它的功能是把对应的字符串解析成JS代码并运行
- 应该避免使用eval,不安全,非常耗性能(2次,一次解析成js语句,一次执行)
- 由JSON字符串转换为JSON对象的时候可以用eval,var obj =eval(‘(‘+ str +’)’)
null,undefined 的区别?
undefined 表示不存在这个值。
undefined :是一个表示”无”的原始值或者说表示”缺少值”,就是此处应该有一个值,但是还没有定义。当尝试读取时会返回 undefined
例如变量被声明了,但没有赋值时,就等于undefined
null 表示一个对象被定义了,值为“空值”
null : 是一个对象(空对象, 没有任何属性和方法)
例如作为函数的参数,表示该函数的参数不是对象;
在验证null时,一定要使用 === ,因为 == 无法分别 null 和 undefined
写一个通用的事件侦听器函数
1 | // event(事件)工具集,来源:github.com/markyun |
[“1”, “2”, “3”].map(parseInt) 答案是多少?
- [1, NaN, NaN] 因为 parseInt 需要两个参数 (val, radix),其中 radix 表示解析时用的基数。
- map 传了 3 个 (element, index, array),对应的 radix 不合法导致解析失败。
事件是?IE与火狐的事件机制有什么区别? 如何阻止冒泡?
- 我们在网页中的某个操作(有的操作对应多个事件)。例如:当我们点击一个按钮就会产生一个事件。是可以被 JavaScript 侦测到的行为
- 事件处理机制:IE是事件冒泡、Firefox同时支持两种事件模型,也就是:捕获型事件和冒泡型事件
- ev.stopPropagation();(旧ie的方法 ev.cancelBubble = true;)
什么是闭包(closure),为什么要用它?
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,通过另一个函数访问这个函数的局部变量,利用闭包可以突破作用链域
闭包的特性:
- 函数内再嵌套函数
- 内部函数可以引用外层的参数和变量
- 参数和变量不会被垃圾回收机制回收
javascript 代码中的”use strict”;是什么意思 ? 使用它区别是什么?
- use strict是一种ECMAscript 5 添加的(严格)运行模式,这种模式使得 Javascript 在更严格的条件下运行,使JS编码更加规范化的模式,消除Javascript语法的一些不合理、不严谨之处,减少一些怪异行为
如何判断一个对象是否属于某个类?
1 | // 使用instanceof (待完善) |
new操作符具体干了什么呢?
- 创建一个空对象,并且 this 变量引用该对象,同时还继承了该函数的原型
- 属性和方法被加入到 this 引用的对象中
- 新创建的对象由 this 所引用,并且最后隐式的返回 this
1 | var obj = {}; |
js延迟加载的方式有哪些?
- defer和async、动态创建DOM方式(用得最多)、按需异步载入js
Ajax 是什么? 如何创建一个Ajax?
ajax的全称:Asynchronous Javascript And XML
异步传输+js+xml
所谓异步,在这里简单地解释就是:向服务器发送请求的时候,我们不必等待结果,而是可以同时做其他的事情,等到有了结果它自己会根据设定进行后续操作,与此同时,页面是不会发生整页刷新的,提高了用户体验
创建XMLHttpRequest对象,也就是创建一个异步调用对象
建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息
设置响应HTTP请求状态变化的函数
发送HTTP请求
获取异步调用返回的数据
用JavaScript和DOM实现局部刷新
同步和异步的区别?
- 同步:浏览器访问服务器请求,用户看得到页面刷新,重新发请求,等请求完,页面刷新,新内容出现,用户看到新内容,进行下一步操作
- 异步:浏览器访问服务器请求,用户正常操作,浏览器后端进行请求。等请求完,页面不刷新,新内容也会出现,用户看到新内容
异步加载JS的方式有哪些?
- defer,只支持IE
- async:
- 创建script,插入到DOM中,加载完毕后callBack
documen.write和 innerHTML的区别
- document.write只能重绘整个页面
- innerHTML可以重绘页面的一部分
DOM操作——怎样添加、移除、移动、复制、创建和查找节点?
- (1)创建新节点
- createDocumentFragment() //创建一个DOM片段
- createElement() //创建一个具体的元素
- createTextNode() //创建一个文本节点
- (2)添加、移除、替换、插入
- appendChild()
- removeChild()
- replaceChild()
- insertBefore() //在已有的子节点前插入一个新的子节点
- (3)查找
- getElementsByTagName() //通过标签名称
- getElementsByName() // 通过元素的Name属性的值(IE容错能力较强,会得到一个数组,其中包括id等于name值的)
- getElementById() //通过元素Id,唯一性
那些操作会造成内存泄漏?
- 内存泄漏指任何对象在您不再拥有或需要它之后仍然存在
- 垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收
- setTimeout 的第一个参数使用字符串而非函数的话,会引发内存泄漏
- 闭包、控制台日志、循环(在两个对象彼此引用且彼此保留时,就会产生一个循环)
渐进增强和优雅降级
渐进增强 :针对低版本浏览器进行构建页面,保证最基本的功能,然后再针对高级浏览器进行效果、交互等改进和追加功能达到更好的用户体验。
优雅降级 :一开始就构建完整的功能,然后再针对低版本浏览器进行兼容
Javascript垃圾回收方法
- 标记清除(mark and sweep)
- 这是JavaScript最常见的垃圾回收方式,当变量进入执行环境的时候,比如函数中声明一个变量,垃圾回收器将其标记为“进入环境”,当变量离开环境的时候(函数执行结束)将其标记为“离开环境”
- 垃圾回收器会在运行的时候给存储在内存中的所有变量加上标记,然后去掉环境中的变量以及被环境中变量所引用的变量(闭包),在这些完成之后仍存在标记的就是要删除的变量了
引用计数(reference counting)
在低版本IE中经常会出现内存泄露,很多时候就是因为其采用引用计数方式进行垃圾回收。引用计数的策略是跟踪记录每个值被使用的次数,当声明了一个 变量并将一个引用类型赋值给该变量的时候这个值的引用次数就加1,如果该变量的值变成了另外一个,则这个值得引用次数减1,当这个值的引用次数变为0的时 候,说明没有变量在使用,这个值没法被访问了,因此可以将其占用的空间回收,这样垃圾回收器会在运行的时候清理掉引用次数为0的值占用的空间
js继承方式及其优缺点
原型链继承的缺点
- 一是字面量重写原型会中断关系,使用引用类型的原型,并且子类型还无法给超类型传递参数。
借用构造函数(类式继承)
- 借用构造函数虽然解决了刚才两种问题,但没有原型,则复用无从谈起。所以我们需要原型链+借用构造函数的模式,这种模式称为组合继承
组合式继承
- 组合式继承是比较常用的一种继承方法,其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又保证每个实例都有它自己的属性。
defer和async
- defer并行加载js文件,会按照页面上script标签的顺序执行async并行加载js文件,下载完成立即执行,不会按照页面上script标签的顺序执行
用过哪些设计模式?
工厂模式:
- 主要好处就是可以消除对象间的耦合,通过使用工程方法而不是new关键字。将所有实例化的代码集中在一个位置防止代码重复
- 工厂模式解决了重复实例化的问题 ,但还有一个问题,那就是识别问题,因为根本无法 搞清楚他们到底是哪个对象的实例1
2
3
4
5
6
7
8
9
10
11function createObject(name,age,profession){//集中实例化的函数var obj = new Object();
obj.name = name;
obj.age = age;
obj.profession = profession;
obj.move = function () {
return this.name + ' at ' + this.age + ' engaged in ' + this.profession;
};
return obj;
}
var test1 = createObject('trigkit4',22,'programmer');//第一个实例var test2 = createObject('mike',25,'engineer');//第二个实例构造函数模式
- 使用构造函数的方法 ,即解决了重复实例化的问题 ,又解决了对象识别的问题,该模式与工厂模式的不同之处在于
构造函数方法没有显示的创建对象 (new Object());
直接将属性和方法赋值给 this 对象;
没有 renturn 语句
说说你对闭包的理解
使用闭包主要是为了设计私有的方法和变量。闭包的优点是可以避免全局变量的污染,缺点是闭包会常驻内存,会增大内存使用量,使用不当很容易造成内存泄露。在js中,函数即闭包,只有函数才会产生作用域的概念
闭包有三个特性:
1.函数嵌套函数
2.函数内部可以引用外部的参数和变量
3.参数和变量不会被垃圾回收机制回收
请解释一下 JavaScript 的同源策略
- 概念:同源策略是客户端脚本(尤其是Javascript)的重要的安全度量标准。它最早出自Netscape Navigator2.0,其目的是防止某个文档或脚本从多个不同源装载。这里的同源策略指的是:协议,域名,端口相同,同源策略是一种安全协议
- 指一段脚本只能读取来自同一来源的窗口和文档的属性
为什么要有同源限制?
- 我们举例说明:比如一个黑客程序,他利用Iframe把真正的银行登录页面嵌到他的页面上,当你使用真实的用户名,密码登录时,他的页面就可以通过Javascript读取到你的表单中input中的内容,这样用户名,密码就轻松到手了。
- 缺点
- 现在网站的JS都会进行压缩,一些文件用了严格模式,而另一些没有。这时这些本来是严格模式的文件,被 merge后,这个串就到了文件的中间,不仅没有指示严格模式,反而在压缩后浪费了字节
实现一个函数clone,可以对JavaScript中的5种主要的数据类型(包括Number、String、Object、Array、Boolean)进行值复制
1 | Object.prototype.clone = function(){ |
说说严格模式的限制
严格模式主要有以下限制:
变量必须声明后再使用
函数的参数不能有同名属性,否则报错
不能使用with语句
不能对只读属性赋值,否则报错
不能使用前缀0表示八进制数,否则报错
不能删除不可删除的属性,否则报错
不能删除变量delete prop,会报错,只能删除属性delete global[prop]
eval不会在它的外层作用域引入变量
eval和arguments不能被重新赋值
arguments不会自动反映函数参数的变化
不能使用arguments.callee
不能使用arguments.caller
禁止this指向全局对象
不能使用fn.caller和fn.arguments获取函数调用的堆栈
增加了保留字(比如protected、static和interface)
如何删除一个cookie
- 将时间设为当前时间往前一点
1 | var date = new Date(); |
setDate()方法用于设置一个月的某一天
- expires的设置
1 | document.cookie = 'user='+ encodeURIComponent('name') + ';expires = ' + new Date(0) |
编写一个方法 求一个字符串的字节长度
- 假设:一个英文字符占用一个字节,一个中文字符占用两个字节
1 | function GetBytes(str){ |
请解释什么是事件代理
- 事件代理(Event Delegation),又称之为事件委托。是 JavaScript 中常用绑定事件的常用技巧。顾名思义,“事件代理”即是把原本需要绑定的事件委托给父元素,让父元素担当事件监听的职务。事件代理的原理是DOM元素的事件冒泡。使用事件代理的好处是可以提高性能
attribute和property的区别是什么?
attribute是dom元素在文档中作为html标签拥有的属性;
property就是dom元素在js中作为对象拥有的属性。
对于html的标准属性来说,attribute和property是同步的,是会自动更新的
但是对于自定义的属性来说,他们是不同步的
页面编码和被请求的资源编码如果不一致如何处理?
- 后端响应头设置 charset
- 前端页面
<meta>设置 charset
把<script>放在</body>之前和之后有什么区别?浏览器会如何解析它们?
- 按照HTML标准,在
</body>结束后出现<script>或任何元素的开始标签,都是解析错误 - 虽然不符合HTML标准,但浏览器会自动容错,使实际效果与写在
</body>之前没有区别 - 浏览器的容错机制会忽略
<script>之前的</body>,视作<script>仍在 body 体内。省略</body>和</html>闭合标签符合HTML标准,服务器可以利用这一标准尽可能少输出内容
延迟加载JS的方式有哪些?
- 设置
<script>属性 defer=”defer” (脚本将在页面完成解析时执行) - 动态创建 script DOM:document.createElement(‘script’);
- XmlHttpRequest 脚本注入
- 延迟加载工具 LazyLoad
异步加载JS的方式有哪些?
- 设置
<script>属性 async=”async” (一旦脚本可用,则会异步执行) - 动态创建 script DOM:document.createElement(‘script’);
- XmlHttpRequest 脚本注入
- 异步加载库 LABjs
- 模块加载器 Sea.js
JavaScript 中,调用函数有哪几种方式?
- 方法调用模式 Foo.foo(arg1, arg2);
- 函数调用模式 foo(arg1, arg2);
- 构造器调用模式 (new Foo())(arg1, arg2);
- call/applay调用模式 Foo.foo.call(that, arg1, arg2);
- bind调用模式 Foo.foo.bind(that)(arg1, arg2)();
简单实现 Function.bind 函数?
1 | if (!Function.prototype.bind) { |
** 列举一下JavaScript数组和对象有哪些原生方法?**
数组:
- arr.concat(arr1, arr2, arrn);
- arr.join(“,”);
- arr.sort(func);
- arr.pop();
- arr.push(e1, e2, en);
- arr.shift();
- unshift(e1, e2, en);
- arr.reverse();
- arr.slice(start, end);
- arr.splice(index, count, e1, e2, en);
- arr.indexOf(el);
- arr.includes(el); // ES6
对象:
- object.hasOwnProperty(prop);
- object.propertyIsEnumerable(prop);
- object.valueOf();
- object.toString();
- object.toLocaleString();
- Class.prototype.isPropertyOf(object);
Array.splice() 与 Array.splice() 的区别?
slice – “读取”数组指定的元素,不会对原数组进行修改
- 语法:arr.slice(start, end)
- start 指定选取开始位置(含)
- end 指定选取结束位置(不含)
splice
- “操作”数组指定的元素,会修改原数组,返回被删除的元素
- 语法:arr.splice(index, count, [insert Elements])
- index 是操作的起始位置
- count = 0 插入元素,count > 0 删除元素
- [insert Elements] 向数组新插入的元素
JavaScript 对象生命周期的理解?
- 当创建一个对象时,JavaScript 会自动为该对象分配适当的内存
- 垃圾回收器定期扫描对象,并计算引用了该对象的其他对象的数量
- 如果被引用数量为 0,或惟一引用是循环的,那么该对象的内存即可回收
哪些操作会造成内存泄漏?
JavaScript 内存泄露指对象在不需要使用它时仍然存在,导致占用的内存不能使用或回收
未使用 var 声明的全局变量
闭包函数(Closures)
循环引用(两个对象相互引用)
控制台日志(console.log)
移除存在绑定事件的DOM元素(IE)
JQuery
你觉得jQuery或zepto源码有哪些写的好的地方
- jquery源码封装在一个匿名函数的自执行环境中,有助于防止变量的全局污染,然后通过传入window对象参数,可以使window对象作为局部变量使用,好处是当jquery中访问window对象的时候,就不用将作用域链退回到顶层作用域了,从而可以更快的访问window对象。同样,传入undefined参数,可以缩短查找undefined时的作用域链
1 | (function( window, undefined ) { |
- jquery将一些原型属性和方法封装在了jquery.prototype中,为了缩短名称,又赋值给了jquery.fn,这是很形象的写法
- 有一些数组或对象的方法经常能使用到,jQuery将其保存为局部变量以提高访问速度
- jquery实现的链式调用可以节约代码,所返回的都是同一个对象,可以提高代码效率
jQuery 的实现原理?
(function(window, undefined) {})(window);jQuery 利用 JS 函数作用域的特性,采用立即调用表达式包裹了自身,解决命名空间和变量污染问题
window.jQuery = window.$ = jQuery;在闭包当中将 jQuery 和 $ 绑定到 window 上,从而将 jQuery 和 $ 暴露为全局变量
jQuery.fn 的 init 方法返回的 this 指的是什么对象? 为什么要返回 this?
- jQuery.fn 的 init 方法 返回的 this 就是 jQuery 对象
- 用户使用 jQuery() 或 $() 即可初始化 jQuery 对象,不需要动态的去调用 init 方法
jQuery.extend 与 jQuery.fn.extend 的区别?
$.fn.extend()和$.extend()是 jQuery 为扩展插件提拱了两个方法$.extend(object); // 为jQuery添加“静态方法”(工具方法)
1 | $.extend({ |
$.extend([true,] targetObject, object1[, object2]);// 对targt对象进行扩展
1 | var settings = {validate:false, limit:5}; |
$.fn.extend(json);// 为jQuery添加“成员函数”(实例方法)
1 | $.fn.extend({ |
jQuery 的属性拷贝(extend)的实现原理是什么,如何实现深拷贝?
浅拷贝(只复制一份原始对象的引用)
var newObject = $.extend({}, oldObject);深拷贝(对原始对象属性所引用的对象进行进行递归拷贝)
var newObject = $.extend(true, {}, oldObject);
jQuery 的队列是如何实现的?队列可以用在哪些地方?
- jQuery 核心中有一组队列控制方法,由 queue()/dequeue()/clearQueue() 三个方法组成。
- 主要应用于 animate(),ajax,其他要按时间顺序执行的事件中
1 | var func1 = function(){alert('事件1');} |
jQuery 中的 bind(), live(), delegate(), on()的区别?
- bind 直接绑定在目标元素上
- live 通过冒泡传播事件,默认document上,支持动态数据
- delegate 更精确的小范围使用事件代理,性能优于 live
- on 是最新的1.9版本整合了之前的三种方式的新事件绑定机制
是否知道自定义事件? jQuery 里的 fire 函数是什么意思,什么时候用?
- 事件即“发布/订阅”模式,自定义事件即“消息发布”,事件的监听即“订阅订阅”
- JS 原生支持自定义事件,示例:
1 | document.createEvent(type); // 创建事件 |
- jQuery 里的 fire 函数用于调用 jQuery 自定义事件列表中的事件
jQuery 通过哪个方法和 Sizzle 选择器结合的?
- Sizzle 选择器采取 Right To Left 的匹配模式,先搜寻所有匹配标签,再判断它的父节点
- jQuery 通过 $(selecter).find(selecter); 和 Sizzle 选择器结合
jQuery 中如何将数组转化为 JSON 字符串,然后再转化回来?
1 | // 通过原生 JSON.stringify/JSON.parse 扩展 jQuery 实现 |
jQuery 一个对象可以同时绑定多个事件,这是如何实现的?
1 | $("#btn").on("mouseover mouseout", func); |
针对 jQuery 的优化方法?
- 缓存频繁操作DOM对象
- 尽量使用id选择器代替class选择器
- 总是从#id选择器来继承
- 尽量使用链式操作
- 使用时间委托 on 绑定事件
- 采用jQuery的内部函数data()来存储数据
- 使用最新版本的 jQuery
jQuery 的 slideUp 动画,当鼠标快速连续触发, 动画会滞后反复执行,该如何处理呢?
- 在触发元素上的事件设置为延迟处理:使用 JS 原生 setTimeout 方法
- 在触发元素的事件时预先停止所有的动画,再执行相应的动画事件:$(‘.tab’).stop().slideUp();
jQuery UI 如何自定义组件?
- 通过向 $.widget() 传递组件名称和一个原型对象来完成
$.widget("ns.widgetName", [baseWidget], widgetPrototype);
jQuery 与 jQuery UI、jQuery Mobile 区别?
jQuery 是 JS 库,兼容各种PC浏览器,主要用作更方便地处理 DOM、事件、动画、AJAX
jQuery UI 是建立在 jQuery 库上的一组用户界面交互、特效、小部件及主题
jQuery Mobile 以 jQuery 为基础,用于创建“移动Web应用”的框架
jQuery 和 Zepto 的区别? 各自的使用场景?
- jQuery 主要目标是PC的网页中,兼容全部主流浏览器。在移动设备方面,单独推出 jQuery Mobile
- Zepto 从一开始就定位移动设备,相对更轻量级。它的 API 基本兼容 jQuery,但对PC浏览器兼容不理想
Ajax
- 什么是
Ajax? 如何创建一个Ajax?
AJAX(Asynchronous Javascript And XML)= 异步JavaScript+XML在后台与服务器进行异步数据交换,不用重载整个网页,实现局部刷新。创建
ajax步骤:- 1.创建
XMLHttpRequest对象 - 2.创建一个新的
HTTP请求,并指定该HTTP请求的类型、验证信息 - 3.设置响应
HTTP请求状态变化的回调函数 - 4.发送
HTTP请求 - 5.获取异步调用返回的数据
- 6.使用
JavaScript和DOM实现局部刷新
- 1.创建
1 | var xhr = new XMLHttpRequest(); |
HTTP
http状态码有那些?分别代表是什么意思?
1 | 简单版 |
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?(流程说的越详细越好)
注:这题胜在区分度高,知识点覆盖广,再不懂的人,也能答出几句,
而高手可以根据自己擅长的领域自由发挥,从URL规范、HTTP协议、DNS、CDN、数据库查询、
到浏览器流式解析、CSS规则构建、layout、paint、onload/domready、JS执行、JS API绑定等等;
详细版:
- 浏览器会开启一个线程来处理这个请求,对 URL 分析判断如果是 http 协议就按照 Web 方式来处理;
- 调用浏览器内核中的对应方法,比如 WebView 中的 loadUrl 方法;
- 通过DNS解析获取网址的IP地址,设置 UA 等信息发出第二个GET请求;
- 进行HTTP协议会话,客户端发送报头(请求报头);
- 进入到web服务器上的 Web Server,如 Apache、Tomcat、Node.JS 等服务器;
- 进入部署好的后端应用,如 PHP、Java、JavaScript、Python 等,找到对应的请求处理;
- 处理结束回馈报头,此处如果浏览器访问过,缓存上有对应资源,会与服务器最后修改时间对比,一致则返回304;
- 浏览器开始下载html文档(响应报头,状态码200),同时使用缓存;
- 文档树建立,根据标记请求所需指定MIME类型的文件(比如css、js),同时设置了cookie;
- 页面开始渲染DOM,JS根据DOM API操作DOM,执行事件绑定等,页面显示完成。
简洁版:
- 浏览器根据请求的URL交给DNS域名解析,找到真实IP,向服务器发起请求;
- 服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、JS、CSS、图象等);
- 浏览器对加载到的资源(HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM);
- 载入解析到的资源文件,渲染页面,完成。
说说TCP传输的三次握手四次挥手策略
为了准确无误地把数据送达目标处,TCP协议采用了三次握手策略。用TCP协议把数据包送出去后,TCP不会对传送 后的情况置之不理,它一定会向对方确认是否成功送达。握手过程中使用了TCP的标志:SYN和ACK
发送端首先发送一个带SYN标志的数据包给对方。接收端收到后,回传一个带有SYN/ACK标志的数据包以示传达确认信息。 最后,发送端再回传一个带ACK标志的数据包,代表“握手”结束。 若在握手过程中某个阶段莫名中断,TCP协议会再次以相同的顺序发送相同的数据包
断开一个TCP连接则需要“四次握手”:
第一次挥手:主动关闭方发送一个FIN,用来关闭主动方到被动关闭方的数据传送,也就是主动关闭方告诉被动关闭方:我已经不 会再给你发数据了(当然,在fin包之前发送出去的数据,如果没有收到对应的ack确认报文,主动关闭方依然会重发这些数据),但是,此时主动关闭方还可 以接受数据
第二次挥手:被动关闭方收到FIN包后,发送一个ACK给对方,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号)
第三次挥手:被动关闭方发送一个FIN,用来关闭被动关闭方到主动关闭方的数据传送,也就是告诉主动关闭方,我的数据也发送完了,不会再给你发数据了
第四次挥手:主动关闭方收到FIN后,发送一个ACK给被动关闭方,确认序号为收到序号+1,至此,完成四次挥手
TCP和UDP的区别
TCP(Transmission Control Protocol,传输控制协议)是基于连接的协议,也就是说,在正式收发数据前,必须和对方建立可靠的连接。一个TCP连接必须要经过三次“对话”才能建立起来
UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是面向非连接的协议,它不与对方建立连接,而是直接就把数据包发送过去! UDP适用于一次只传送少量数据、对可靠性要求不高的应用环境
HTTP和HTTPS
- HTTP协议通常承载于TCP协议之上,在HTTP和TCP之间添加一个安全协议层(SSL或TSL),这个时候,就成了我们常说的HTTPS
- 默认HTTP的端口号为80,HTTPS的端口号为443
为什么HTTPS安全
- 因为网络请求需要中间有很多的服务器路由器的转发。中间的节点都可能篡改信息,而如果使用HTTPS,密钥在你和终点站才有。https之所以比http安全,是因为他利用ssl/tls协议传输。它包含证书,卸载,流量转发,负载均衡,页面适配,浏览器适配,refer传递等。保障了传输过程的安全性
关于Http 2.0 你知道多少?
HTTP/2引入了“服务端推(server push)”的概念,它允许服务端在客户端需要数据之前就主动地将数据发送到客户端缓存中,从而提高性能。
HTTP/2提供更多的加密支持
HTTP/2使用多路技术,允许多个消息在一个连接上同时交差。
它增加了头压缩(header compression),因此即使非常小的请求,其请求和响应的header都只会占用很小比例的带宽
GET和POST的区别,何时使用POST?
- GET:一般用于信息获取,使用URL传递参数,对所发送信息的数量也有限制,一般在2000个字符
- POST:一般用于修改服务器上的资源,对所发送的信息没有限制。
- GET方式需要使用Request.QueryString来取得变量的值,而POST方式通过Request.Form来获取变量的值,也就是说Get是通过地址栏来传值,而Post是通过提交表单来传值。
- 然而,在以下情况中,请使用 POST 请求:
无法使用缓存文件(更新服务器上的文件或数据库)
向服务器发送大量数据(POST 没有数据量限制)
发送包含未知字符的用户输入时,POST 比 GET 更稳定也更可靠
说说网络分层里七层模型是哪七层
应用层:应用层、表示层、会话层(从上往下)(HTTP、FTP、SMTP、DNS)
传输层(TCP和UDP)
网络层(IP)
物理和数据链路层(以太网)
每一层的作用如下:
- 物理层:通过媒介传输比特,确定机械及电气规范(比特Bit)
数据链路层:将比特组装成帧和点到点的传递(帧Frame)
- 网络层:负责数据包从源到宿的传递和网际互连(包PackeT)
- 传输层:提供端到端的可靠报文传递和错误恢复(段Segment)
- 会话层:建立、管理和终止会话(会话协议数据单元SPDU)
- 表示层:对数据进行翻译、加密和压缩(表示协议数据单元PPDU)
- 应用层:允许访问OSI环境的手段(应用协议数据单元APDU)
讲讲304缓存的原理
- 服务器首先产生ETag,服务器可在稍后使用它来判断页面是否已经被修改。本质上,客户端通过将该记号传回服务器要求服务器验证其(客户端)缓存
- 304是HTTP状态码,服务器用来标识这个文件没修改,不返回内容,浏览器在接收到个状态码后,会使用浏览器已缓存的文件
- 客户端请求一个页面(A)。 服务器返回页面A,并在给A加上一个ETag。 客户端展现该页面,并将页面连同ETag一起缓存。 客户再次请求页面A,并将上次请求时服务器返回的ETag一起传递给服务器。 服务器检查该ETag,并判断出该页面自上次客户端请求之后还未被修改,直接返回响应304(未修改——Not Modified)和一个空的响应体
HTTP/2 与 HTTP/1.x 的关键区别
- 二进制协议代替文本协议,更加简洁高效
- 针对每个域只使用一个多路复用的连接
- 压缩头部信息减小开销
- 允许服务器主动推送应答到客户端的缓存中
一个页面从输入 URL 到页面加载显示完成,这个过程中都发生了什么?
- 01.浏览器查找域名对应的IP地址(DNS 查询:浏览器缓存->系统缓存->路由器缓存->ISP DNS 缓存->根域名服务器)
- 02.浏览器向 Web 服务器发送一个 HTTP 请求(TCP三次握手)
- 03.服务器 301 重定向(从 http://example.com 重定向到 http://www.example.com)
- 04.浏览器跟踪重定向地址,请求另一个带 www 的网址
- 05.服务器处理请求(通过路由读取资源)
- 06.服务器返回一个 HTTP 响应(报头中把 Content-type 设置为 ‘text/html’)
- 07.浏览器进 DOM 树构建
- 08.浏览器发送请求获取嵌在 HTML 中的资源(如图片、音频、视频、CSS、JS等)
- 09.浏览器显示完成页面
- 10.浏览器发送异步请求
前端工程化相关
什么是单页面应用(SPA)?
单页面应用(SPA)是指用户在浏览器加载单一的HTML页面,后续请求都无需再离开此页
目标:旨在用为用户提供了更接近本地移动APP或桌面应用程序的体验。
流程:第一次请求时,将导航页传输到客户端,其余请求通过 REST API 获取 JSON 数据
实现:数据的传输通过 Web Socket API 或 RPC(远程过程调用)。
优点:用户体验流畅,服务器压力小,前后端职责分离
缺点:关键词布局难度加大,不利于 SEO
什么是“前端路由”? 什么时候适用“前端路由”? 有哪些优点和缺点?
- 前端路由通过 URL 和 History 来实现页面切换
- 应用:前端路由主要适用于“前后端分离”的单页面应用(SPA)项目
- 优点:用户体验好,交互流畅
- 缺点:浏览器“前进”、“后退”会重新请求,无法合理利用缓存
模块化开发怎么做?
- 封装对象作为命名空间 – 内部状态可以被外部改写
- 立即执行函数(IIFE) – 需要依赖多个JS文件,并且严格按顺序加载
- 使用模块加载器 – require.js, sea.js, EC6 模块
通行的 Javascript 模块的规范有哪些?
- CommonJS – 主要用在服务器端 node.js
1 | var math = require('./math'); |
- AMD(异步模块定义) – require.js
1 | require(['./math'], function (math) { |
CMD(通用模块定义) – sea.js
1
2var math = require('./math');
math.add(2,3);ES6 模块
1 | import {math} from './math'; |
AMD 与 CMD 规范的区别?
规范化产出:
- AMD 由 RequireJS 推广产出
- CMD 由 SeaJS 推广产出
模块的依赖:
- AMD 提前执行,推崇依赖前置
- CMD 延迟执行,推崇依赖就近
API 功能:
- AMD 的 API 默认多功能(分全局 require 和局部 require)
- CMD 的 API 推崇职责单一纯粹(没有全局 require)
模块定义规则:
- AMD 默认一开始就载入全部依赖模块
1 | define(['./a', './b'], function(a, b) { |
- CMD 依赖模块在用到时才就近载入
1 | define(function(require, exports, module) { |
requireJS的核心原理是什么?
- 每个模块所依赖模块都会比本模块预先加载
对 Node.js 的优点、缺点提出了自己的看法? Node.js的特点和适用场景?
- Node.js的特点:单线程,非阻塞I/O,事件驱动
- Node.js的优点:擅长处理高并发;适合I/O密集型应用
Node.js的缺点:不适合CPU密集运算;不能充分利用多核CPU;可靠性低,某个环节出错会导致整个系统崩溃
Node.js的适用场景:
- RESTful API
- 实时应用:在线聊天、图文直播
- 工具类应用:前端部署(npm, gulp)
- 表单收集:问卷系统
如何判断当前脚本运行在浏览器还是node环境中?
- 判断 Global 对象是否为 window,如果不为 window,当前脚本没有运行在浏览器中
什么是 npm ?
- npm 是 Node.js 的模块管理和发布工具
什么是 WebKit ?
- WebKit 是一个开源的浏览器内核,由渲染引擎(WebCore)和JS解释引擎(JSCore)组成
- 通常所说的 WebKit 指的是 WebKit(WebCore),主要工作是进行 HTML/CSS 渲染
- WebKit 一直是 Safari 和 Chrome(之前) 使用的浏览器内核,后来 Chrome 改用Blink 内核
如何测试前端代码? 知道 Unit Test,BDD, TDD 么? 怎么测试你的前端工程(mocha, jasmin..)?
- 通过为前端代码编写单元测试(Unit Test)来测试前端代码
- Unit Test:一段用于测试一个模块或接口是否能达到预期结果的代码
- BDD:行为驱动开发 – 业务需求描述产出产品代码的开发方法
- TDD:测试驱动开发 – 单元测试用例代码产出产品代码的开发方法
- 单元测试框架:
1 | // mocha 示例 |
介绍你知道的前端模板引擎?
- artTemplate, underscore, handlebars
什么是 Modernizr? Modernizr 工作原理?
- Modernizr 是一个开源的 JavaScript 库,用于检测用户浏览器对 HTML5 与 CSS3 的支持情况
移动端最小触控区域是多大?
- 44 * 44 px
移动端的点击事件的延迟时间是多长,为什么会有延迟? 如何解决这个延时?
- 移动端 click 有 300ms 延迟,浏览器为了区分“双击”(放大页面)还是“单击”而设计
- 解决方案:
- 禁用缩放(对safari无效)
- 使用指针事件(IE私有特性,且仅IE10+)
- 使用 Zepto 的 tap 事件(有点透BUG)
- 使用 FastClick 插件(体积大[压缩后8k])
什么是函数式编程?
函数式编程是一种”编程范式”,主要思想是把运算过程尽量写成一系列嵌套的函数调用
例如:var result = subtract(multiply(add(1,2), 3), 4);
函数式编程的特点:
- 函数核心化:函数可以作为变量的赋值、另一函数的参数、另一函数的返回值
- 只用“表达式”,不用“语句”:要求每一步都是单纯的运算,都必须有返回值
- 没有”副作用”:所有功能只为返回一个新的值,不修改外部变量
- 引用透明:运行不依赖于外部变量,只依赖于输入的参数
函数式编程的优点:
- 代码简洁,接近自然语言,易于理解
- 便于维护,利于测试、除错、组合
- 易于“并发编程“,不用担心一个线程的数据,被另一个线程修改
- 可“热升级”代码,在运行状态下直接升级代码,不需要重启,也不需要停机
什么是函数柯里化Currying)?
柯里化:
- 通常也称部分求值,含义是给函数分步传递参数,每次递参部分应用参数,并返回一个更具体的函数,继续接受剩余参数
- 期间会连续返回具体函数,直至返回最后结果。因此,函数柯里化是逐步传参,逐步缩小函数的适用范围,逐步求解的过程
- 柯里化的作用:延迟计算;参数复用;动态创建函数
柯里化的缺点:
- 函数柯里化会产生开销(函数嵌套,比普通函数占更多内存),但性能瓶颈首先来自其它原因(DOM 操作等)
什么是依赖注入?
- 当一个类的实例依赖另一个类的实例时,自己不创建该实例,由IOC容器创建并注入给自己,因此称为依赖注入。
- 依赖注入解决的就是如何有效组织代码依赖模块的问题
设计模式:什么是 singleton, factory, strategy, decorator?
- Singleton(单例) 一个类只有唯一实例,这个实例在整个程序中有一个全局的访问点
- Factory (工厂) 解决实列化对象产生重复的问题
- Strategy(策略) 将每一个算法封装起来,使它们还可以相互替换,让算法独立于使用
- Observer(观察者) 多个观察者同时监听一个主体,当主体对象发生改变时,所有观察者都将得到通知
- Prototype(原型) 一个完全初始化的实例,用于拷贝或者克隆
- Adapter(适配器) 将不同类的接口进行匹配调整,尽管内部接口不兼容,不同的类还是可以协同工作
- Proxy(代理模式) 一个充当过滤转发的对象用来代表一个真实的对象
- Iterator(迭代器) 在不需要直到集合内部工作原理的情况下,顺序访问一个集合里面的元素
- Chain of Responsibility(职责连) 处理请求组成的对象一条链,请求链中传递,直到有对象可以处理
什么是前端工程化?
前端工程化就是把一整套前端工作流程使用工具自动化完成
前端开发基本流程:
- 项目初始化:yeoman, FIS
- 引入依赖包:bower, npm
- 模块化管理:npm, browserify, Webpack
- 代码编译:babel, sass, less
- 代码优化(压缩/合并):Gulp, Grunt
- 代码检查:JSHint, ESLint
- 代码测试:Mocha
目前最知名的构建工具:Gulp, Grunt, npm + Webpack
介绍 Yeoman 是什么?
- Yeoman –前端开发脚手架工具,自动将最佳实践和工具整合起来构建项目骨架
- Yeoman 其实是三类工具的合体,三类工具各自独立:
- yo — 脚手架,自动生成工具(相当于一个粘合剂,把 Yeoman 工具粘合在一起)
- Grunt、gulp — 自动化构建工具 (最初只有grunt,之后加入了gulp)
- Bower、npm — 包管理工具 (原来是bower,之后加入了npm)
介绍 WebPack 是什么? 有什么优势?
- WebPack 是一款[模块加载器]兼[打包工具],用于把各种静态资源(js/css/image等)作为模块来使用
- WebPack 的优势:
- WebPack 同时支持 commonJS 和 AMD/CMD,方便代码迁移
- 不仅仅能被模块化 JS ,还包括 CSS、Image 等
- 能替代部分 grunt/gulp 的工作,如打包、压缩混淆、图片base64
- 扩展性强,插件机制完善,特别是支持 React 热插拔的功能
介绍类库和框架的区别?
- 类库是一些函数的集合,帮助开发者写WEB应用,起主导作用的是开发者的代码
- 框架是已实现的特殊WEB应用,开发者只需对它填充具体的业务逻辑,起主导作用是框架
什么是 MVC/MVP/MVVM/Flux?
MVC(Model-View-Controller)
- V->C, C->M, M->V
- 通信都是单向的;C只起路由作用,业务逻辑都部署在V
- Backbone
MVP(Model-View-Presenter)
- V<->P, P<->M
- 通信都是双向的;V和M不发生联系(通过P传);V非常薄,逻辑都部署在P
- Riot.js
MVVM(Model-View-ViewModel)
- V->VM, VM<->M
- 采用双向数据绑定:View 和 ViewModel 的变动都会相互映射到对象上面
- Angular
Flux(Dispatcher-Store-View)
- Action->Dispatcher->Store->View, View->Action
- Facebook 为了解决在 MVC 应用中碰到的工程性问题提出一个架构思想
- 基于一个简单的原则:数据在应用中单向流动(单向数据流)
- React(Flux 中 View,只关注表现层)
Backbone 是什么?
- Backbone 是一个基于 jquery 和 underscore 的前端(MVC)框架
AngularJS 是什么?
- AngularJS 是一个完善的前端 MVVM 框架,包含模板、数据双向绑定、路由、模块化、服务、依赖注入等
- AngularJS 由 Google 维护,用来协助大型单一页面应用开发。
React 是什么?
- React 不是 MV* 框架,用于构建用户界面的 JavaScript 库,侧重于 View 层
- React 主要的原理:
- 虚拟 DOM + diff 算法 -> 不直接操作 DOM 对象
- Components 组件 -> Virtual DOM 的节点
- State 触发视图的渲染 -> 单向数据绑定
- React 解决方案:React + Redux + react-router + Fetch + webpack
react-router 路由系统的实现原理?
- 实现原理:location 与 components 之间的同步
- 路由的职责是保证 UI 和 URL 的同步
- 在 react-router 中,URL 对应 Location 对象,UI 由 react components 决定
- 因此,路由在 react-router 中就转变成 location 与 components 之间的同步
Meteor 是什么
- Meteor 是一个全栈开发框架,基础构架是 Node.JS + MongoDB,并把延伸到了浏览器端。
- Meteor 统一了服务器端和客户端的数据访问,使开发者可以轻松完成全栈式开发工作。
JSON和XML
XML和JSON的区别?
数据体积方面
- JSON相对于XML来讲,数据的体积小,传递的速度更快些。
数据交互方面
- JSON与JavaScript的交互更加方便,更容易解析处理,更好的数据交互
数据描述方面
- JSON对数据的描述性比XML较差
传输速度方面
- JSON的速度要远远快于XML
JSON 的了解?
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式
它是基于JavaScript的一个子集。数据格式简单, 易于读写, 占用带宽小
JSON字符串转换为JSON对象:
1 | var obj =eval('('+ str +')'); |
- JSON对象转换为JSON字符串:
1 | var last=obj.toJSONString(); |
localStorage
浏览器本地存储
- 在较高版本的浏览器中,js提供了sessionStorage和globalStorage。在HTML5中提供了localStorage来取代globalStorage
- html5中的Web Storage包括了两种存储方式:sessionStorage和localStorage
- sessionStorage用于本地存储一个会话(session)中的数据,这些数据只有在同一个会话中的页面才能访问并且当会话结束后数据也随之销毁。因此sessionStorage不是一种持久化的本地存储,仅仅是会话级别的存储
- 而localStorage用于持久化的本地存储,除非主动删除数据,否则数据是永远不会过期的
web storage和cookie的区别
- Web Storage的概念和cookie相似,区别是它是为了更大容量存储设计的。Cookie的大小是受限的,并且每次你请求一个新的页面的时候Cookie都会被发送过去,这样无形中浪费了带宽,另外cookie还需要指定作用域,不可以跨域调用
- 除此之外,WebStorage拥有setItem,getItem,removeItem,clear等方法,不像cookie需要前端开发者自己封装setCookie,getCookie
- 但是cookie也是不可以或缺的:cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生
- 浏览器的支持除了IE7及以下不支持外,其他标准浏览器都完全支持(ie及FF需在web服务器里运行),值得一提的是IE总是办好事,例如IE7、IE6中的userData其实就是javascript本地存储的解决方案。通过简单的代码封装可以统一到所有的浏览器都支持web storage
- localStorage和sessionStorage都具有相同的操作方法,例如setItem、getItem和removeItem等
cookie 和session 的区别:
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
- 考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
- 考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
描述 cookies、sessionStorage 和 localStorage 的区别?
与服务器交互:
- cookie 是网站为了标示用户身份而储存在用户本地终端上的数据(通常经过加密)
- cookie 始终会在同源 http 请求头中携带(即使不需要),在浏览器和服务器间来回传递
- sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存
存储大小:
- cookie 数据根据不同浏览器限制,大小一般不能超过 4k
- sessionStorage 和 localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
- 有期时间:
- localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据
- sessionStorage 数据在当前浏览器窗口关闭后自动删除
- cookie 设置的cookie过期时间之前一直有效,与浏览器是否关闭无关
移动端适配
移动端(Android、IOS)怎么做好用户体验?
- 清晰的视觉纵线
- 信息的分组、极致的减法
- 利用选择代替输入
- 标签及文字的排布方式
- 依靠明文确认密码
- 合理的键盘利用
前端页面有哪三层构成,分别是什么?作用是什么?
- 结构层:由 (X)HTML 标记语言负责,解决页面“内容是什么”的问题
- 表示层:由 CSS 负责,解决页面“如何显示内容”的问题
- 行为层:由 JS 脚本负责,解决页面上“内容应该如何对事件作出反应”的问题
前端模块化
说说你对AMD和Commonjs的理解
- CommonJS是服务器端模块的规范,Node.js采用了这个规范。CommonJS规范加载模块是同步的,也就是说,只有加载完成,才能执行后面的操作。AMD规范则是非同步加载模块,允许指定回调函数
- AMD推荐的风格通过返回一个对象做为模块对象,CommonJS的风格通过对module.exports或exports的属性赋值来达到暴露模块对象的目的
模块化开发怎么做?
- 立即执行函数,不暴露私有成员
1 | var module1 = (function(){ |
AMD(Modules/Asynchronous-Definition)、CMD(Common Module Definition)规范区别?
- Asynchronous Module Definition,异步模块定义,所有的模块将被异步加载,模块加载不影响后面语句运行。所有依赖某些模块的语句均放置在回调函数中
1 | // CMD |
对前端模块化的认识
- AMD 是 RequireJS 在推广过程中对模块定义的规范化产出
- CMD 是 SeaJS 在推广过程中对模块定义的规范化产出
- AMD 是提前执行,CMD 是延迟执行
- AMD推荐的风格通过返回一个对象做为模块对象,CommonJS的风格通过对module.exports或exports的属性赋值来达到暴露模块对象的目的
性能优化
如何进行网站性能优化
content方面
- 减少HTTP请求:合并文件、CSS精灵、inline Image
- 减少DNS查询:DNS查询完成之前浏览器不能从这个主机下载任何任何文件。方法:DNS缓存、将资源分布到恰当数量的主机名,平衡并行下载和DNS查询
- 避免重定向:多余的中间访问
- 使Ajax可缓存
- 非必须组件延迟加载
- 未来所需组件预加载
- 减少DOM元素数量
- 将资源放到不同的域下:浏览器同时从一个域下载资源的数目有限,增加域可以提高并行下载量
- 减少iframe数量
- 不要404
Server方面
- 使用CDN
- 添加Expires或者Cache-Control响应头
- 对组件使用Gzip压缩
- 配置ETag
- Flush Buffer Early
- Ajax使用GET进行请求
- 避免空src的img标签
Cookie方面
- 减小cookie大小
- 引入资源的域名不要包含cookie
css方面
- 将样式表放到页面顶部
- 不使用CSS表达式
- 不使用IE的Filter
Javascript方面
- 将脚本放到页面底部
- 将javascript和css从外部引入
- 压缩javascript和css
- 删除不需要的脚本
- 减少DOM访问
- 合理设计事件监听器
图片方面
- 优化图片:根据实际颜色需要选择色深、压缩
- 优化css精灵
- 不要在HTML中拉伸图片
- 保证favicon.ico小并且可缓存
移动方面
- 保证组件小于25k
Pack Components into a Multipart Document
你有用过哪些前端性能优化的方法?
- 减少http请求次数:CSS Sprites, JS、CSS源码压缩、图片大小控制合适;网页Gzip,CDN托管,data缓存 ,图片服务器。
- 前端模板 JS+数据,减少由于HTML标签导致的带宽浪费,前端用变量保存AJAX请求结果,每次操作本地变量,不用请求,减少请求次数
- 用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能。
- 当需要设置的样式很多时设置className而不是直接操作style
- 少用全局变量、缓存DOM节点查找的结果。减少IO读取操作
- 避免使用CSS Expression(css表达式)又称Dynamic properties(动态属性)
- 图片预加载,将样式表放在顶部,将脚本放在底部 加上时间戳
- 避免在页面的主体布局中使用table,table要等其中的内容完全下载之后才会显示出来,显示比div+css布局慢
谈谈性能优化问题
- 代码层面:避免使用css表达式,避免使用高级选择器,通配选择器
- 缓存利用:缓存Ajax,使用CDN,使用外部js和css文件以便缓存,添加Expires头,服务端配置Etag,减少DNS查找等
- 请求数量:合并样式和脚本,使用css图片精灵,初始首屏之外的图片资源按需加载,静态资源延迟加载
- 请求带宽:压缩文件,开启GZIP
代码层面的优化
用hash-table来优化查找
少用全局变量
用innerHTML代替DOM操作,减少DOM操作次数,优化javascript性能
用setTimeout来避免页面失去响应
缓存DOM节点查找的结果
避免使用CSS Expression
避免全局查询
避免使用with(with会创建自己的作用域,会增加作用域链长度)
多个变量声明合并
避免图片和iFrame等的空Src。空Src会重新加载当前页面,影响速度和效率
尽量避免写在HTML标签中写Style属性
前端性能优化最佳实践?
- 性能评级工具(PageSpeed 或 YSlow)
- 合理设置 HTTP 缓存:Expires 与 Cache-control
- 静态资源打包,开启 Gzip 压缩(节省响应流量)
- CSS3 模拟图像,图标base64(降低请求数)
- 模块延迟(defer)加载/异步(async)加载
- Cookie 隔离(节省请求流量)
- localStorage(本地存储)
- 使用 CDN 加速(访问最近服务器)
- 启用 HTTP/2(多路复用,并行加载)
- 前端自动化(gulp/webpack)
图片相关
PNG,GIF,JPG的区别及如何选
GIF:
- 8位像素,256色
- 无损压缩
- 支持简单动画
- 支持boolean透明
- 适合简单动画
JPEG:
- 颜色限于256
- 有损压缩
- 可控制压缩质量
- 不支持透明
- 适合照片
PNG:
- 有PNG8和truecolor PNG
- PNG8类似GIF颜色上限为256,文件小,支持alpha透明度,无动画
- 适合图标、背景、按钮
SEO
前端需要注意哪些SEO
- 合理的title、description、keywords:搜索对着三项的权重逐个减小,title值强调重点即可,重要关键词出现不要超过2次,而且要靠前,不同页面title要有所不同;description把页面内容高度概括,长度合适,不可过分堆砌关键词,不同页面description有所不同;keywords列举出重要关键词即可
- 语义化的HTML代码,符合W3C规范:语义化代码让搜索引擎容易理解网页
- 重要内容HTML代码放在最前:搜索引擎抓取HTML顺序是从上到下,有的搜索引擎对抓取长度有限制,保证重要内容一定会被抓取
- 重要内容不要用js输出:爬虫不会执行js获取内容
- 少用iframe:搜索引擎不会抓取iframe中的内容
- 非装饰性图片必须加alt
- 提高网站速度:网站速度是搜索引擎排序的一个重要指标
如何做SEO优化?
标题与关键词
- 设置有吸引力切合实际的标题,标题中要包含所做的关键词
网站结构目录
- 最好不要超过三级,每级有“面包屑导航”,使网站成树状结构分布
页面元素
- 给图片标注”Alt”可以让搜索引擎更友好的收录
网站内容
- 每个月每天有规律的更新网站的内容,会使搜索引擎更加喜欢
友情链接
- 对方一定要是正规网站,每天有专业的团队或者个人维护更新
内链的布置
- 使网站形成类似蜘蛛网的结构,不会出现单独连接的页面或链接
流量分析
- 通过统计工具(百度统计,CNZZ)分析流量来源,指导下一步的SEO
ES6
1、ES5、ES6和ES2015有什么区别?
ES2015特指在2015年发布的新一代JS语言标准,ES6泛指下一代JS语言标准,包含ES2015、ES2016、ES2017、ES2018等。现阶段在绝大部分场景下,ES2015默认等同ES6。ES5泛指上一代语言标准。ES2015可以理解为ES5和ES6的时间分界线
2、babel是什么,有什么作用?
babel是一个ES6转码器,可以将ES6代码转为ES5代码,以便兼容那些还没支持ES6的平台
3、let有什么用,有了var为什么还要用let?
在
ES6之前,声明变量只能用var,var方式声明变量其实是很不合理的,准确的说,是因为ES5里面没有块级作用域是很不合理的。没有块级作用域回来带很多难以理解的问题,比如for循环var变量泄露,变量覆盖等问题。let声明的变量拥有自己的块级作用域,且修复了var声明变量带来的变量提升问题。
4、举一些ES6对String字符串类型做的常用升级优化?
优化部分
ES6新增了字符串模板,在拼接大段字符串时,用反斜杠()`取代以往的字符串相加的形式,能保留所有空格和换行,使得字符串拼接看起来更加直观,更加优雅
升级部分
ES6在String原型上新增了includes()方法,用于取代传统的只能用indexOf查找包含字符的方法(indexOf返回-1表示没查到不如includes方法返回false更明确,语义更清晰), 此外还新增了startsWith(),endsWith(),padStart(),padEnd(),repeat()等方法,可方便的用于查找,补全字符串
5、举一些ES6对Array数组类型做的常用升级优化
优化部分
- 数组解构赋值。
ES6可以直接以let [a,b,c] = [1,2,3]形式进行变量赋值,在声明较多变量时,不用再写很多let(var),且映射关系清晰,且支持赋默认值 - 扩展运算符。
ES6新增的扩展运算符(...)(重要),可以轻松的实现数组和松散序列的相互转化,可以取代arguments对象和apply方法,轻松获取未知参数个数情况下的参数集合。(尤其是在ES5中,arguments并不是一个真正的数组,而是一个类数组的对象,但是扩展运算符的逆运算却可以返回一个真正的数组)。扩展运算符还可以轻松方便的实现数组的复制和解构赋值(let a = [2,3,4];let b = [...a])
升级部分
ES6在Array原型上新增了find()方法,用于取代传统的只能用indexOf查找包含数组项目的方法,且修复了indexOf查找不到NaN的bug([NaN].indexOf(NaN) === -1).此外还新增了copyWithin(),includes(),fill(),flat()等方法,可方便的用于字符串的查找,补全,转换等
6、举一些ES6对Number数字类型做的常用升级优化
优化部分
ES6在
Number原型上新增了isFinite(),isNaN()方法,用来取代传统的全局isFinite(),isNaN()方法检测数值是否有限、是否是NaN。ES5的isFinite(),isNaN()方法都会先将非数值类型的参数转化为Number类型再做判断,这其实是不合理的,最造成isNaN('NaN') === true的奇怪行为--'NaN'是一个字符串,但是isNaN却说这就是NaN。而Number.isFinite()和Number.isNaN()则不会有此类问题(Number.isNaN('NaN') === false)。(isFinite()同上)
升级部分
ES6在Math对象上新增了Math.cbrt(),trunc(),hypot()等等较多的科学计数法运算方法,可以更加全面的进行立方根、求和立方根等等科学计算
7、举一些ES6对Object类型做的常用升级优化?(重要)
优化部分
对象属性变量式声明。
ES6可以直接以变量形式声明对象属性或者方法,。比传统的键值对形式声明更加简洁,更加方便,语义更加清晰
1 | let [apple, orange] = ['red appe', 'yellow orange']; |
尤其在对象解构赋值(见优化部分b.)或者模块输出变量时,这种写法的好处体现的最为明显
1 | let {keys, values, entries} = Object; |
可以看到属性变量式声明属性看起来更加简洁明了。方法也可以采用简洁写法
1 | let es5Fun = { |
对象的解构赋值。
ES6对象也可以像数组解构赋值那样,进行变量的解构赋值
1 | let {apple, orange} = {apple: 'red appe', orange: 'yellow orange'}; |
对象的扩展运算符(
...)。 ES6对象的扩展运算符和数组扩展运算符用法本质上差别不大,毕竟数组也就是特殊的对象。对象的扩展运算符一个最常用也最好用的用处就在于可以轻松的取出一个目标对象内部全部或者部分的可遍历属性,从而进行对象的合并和分解
1 | let {apple, orange, ...otherFruits} = {apple: 'red apple', orange: 'yellow orange', grape: 'purple grape', peach: 'sweet peach'}; |
super关键字。ES6在Class类里新增了类似this的关键字super。同this总是指向当前函数所在的对象不同,super关键字总是指向当前函数所在对象的原型对象
升级部分
ES6在Object原型上新增了is()方法,做两个目标对象的相等比较,用来完善'==='方法。'==='方法中NaN === NaN //false其实是不合理的,Object.is修复了这个小bug。(Object.is(NaN, NaN) // true)
ES6在Object原型上新增了assign()方法,用于对象新增属性或者多个对象合并
1 | const target = { a: 1 }; |
注意:
assign合并的对象target只能合并source1、source2中的自身属性,并不会合并source1、source2中的继承属性,也不会合并不可枚举的属性,且无法正确复制get和set属性(会直接执行get/set函数,取return的值)
ES6在Object原型上新增了getOwnPropertyDescriptors()方法,此方法增强了ES5中getOwnPropertyDescriptor()方法,可以获取指定对象所有自身属性的描述对象。结合defineProperties()方法,可以完美复制对象,包括复制get和set属性ES6在Object原型上新增了getPrototypeOf()和setPrototypeOf()方法,用来获取或设置当前对象的prototype对象。这个方法存在的意义在于,ES5中获取设置prototype对像是通过__proto__属性来实现的,然而__proto__属性并不是ES规范中的明文规定的属性,只是浏览器各大产商“私自”加上去的属性,只不过因为适用范围广而被默认使用了,再非浏览器环境中并不一定就可以使用,所以为了稳妥起见,获取或设置当前对象的prototype对象时,都应该采用ES6新增的标准用法ES6在Object原型上还新增了Object.keys(),Object.values(),Object.entries()方法,用来获取对象的所有键、所有值和所有键值对数组
8、举一些ES6对Function函数类型做的常用升级优化?
优化部分
箭头函数(核心)。箭头函数是ES6核心的升级项之一,箭头函数里没有自己的this,这改变了以往JS函数中最让人难以理解的this运行机制。主要优化点
- 箭头函数内的this指向的是函数定义时所在的对象,而不是函数执行时所在的对象。ES5函数里的this总是指向函数执行时所在的对象,这使得在很多情况下
this的指向变得很难理解,尤其是非严格模式情况下,this有时候会指向全局对象,这甚至也可以归结为语言层面的bug之一。ES6的箭头函数优化了这一点,它的内部没有自己的this,这也就导致了this总是指向上一层的this,如果上一层还是箭头函数,则继续向上指,直到指向到有自己this的函数为止,并作为自己的this - 箭头函数不能用作构造函数,因为它没有自己的
this,无法实例化 - 也是因为箭头函数没有自己的this,所以箭头函数 内也不存在
arguments对象。(可以用扩展运算符代替) - 函数默认赋值。
ES6之前,函数的形参是无法给默认值得,只能在函数内部通过变通方法实现。ES6以更简洁更明确的方式进行函数默认赋值
1 | function es6Fuc (x, y = 'default') { |
升级部分
ES6新增了双冒号运算符,用来取代以往的
bind,call,和apply。(浏览器暂不支持,Babel已经支持转码)
1 | foo::bar; |
9、Symbol是什么,有什么作用?
Symbol是ES6引入的第七种原始数据类型(说法不准确,应该是第七种数据类型,Object不是原始数据类型之一,已更正),所有Symbol()生成的值都是独一无二的,可以从根本上解决对象属性太多导致属性名冲突覆盖的问题。对象中Symbol()属性不能被for...in遍历,但是也不是私有属性
10、Set是什么,有什么作用?
Set是ES6引入的一种类似Array的新的数据结构,Set实例的成员类似于数组item成员,区别是Set实例的成员都是唯一,不重复的。这个特性可以轻松地实现数组去重
11、Map是什么,有什么作用?
Map是ES6引入的一种类似Object的新的数据结构,Map可以理解为是Object的超集,打破了以传统键值对形式定义对象,对象的key不再局限于字符串,也可以是Object。可以更加全面的描述对象的属性
12、Proxy是什么,有什么作用?
Proxy是ES6新增的一个构造函数,可以理解为JS语言的一个代理,用来改变JS默认的一些语言行为,包括拦截默认的get/set等底层方法,使得JS的使用自由度更高,可以最大限度的满足开发者的需求。比如通过拦截对象的get/set方法,可以轻松地定制自己想要的key或者value。下面的例子可以看到,随便定义一个myOwnObj的key,都可以变成自己想要的函数`
1 | function createMyOwnObj() { |
13、Reflect是什么,有什么作用?
Reflect是ES6引入的一个新的对象,他的主要作用有两点,一是将原生的一些零散分布在Object、Function或者全局函数里的方法(如apply、delete、get、set等等),统一整合到Reflect上,这样可以更加方便更加统一的管理一些原生API。其次就是因为Proxy可以改写默认的原生API,如果一旦原生API别改写可能就找不到了,所以Reflect也可以起到备份原生API的作用,使得即使原生API被改写了之后,也可以在被改写之后的API用上默认的API
14、Promise是什么,有什么作用?
Promise是ES6引入的一个新的对象,他的主要作用是用来解决JS异步机制里,回调机制产生的“回调地狱”。它并不是什么突破性的API,只是封装了异步回调形式,使得异步回调可以写的更加优雅,可读性更高,而且可以链式调用
15、Iterator是什么,有什么作用?(重要)
Iterator是ES6中一个很重要概念,它并不是对象,也不是任何一种数据类型。因为ES6新增了Set、Map类型,他们和Array、Object类型很像,Array、Object都是可以遍历的,但是Set、Map都不能用for循环遍历,解决这个问题有两种方案,一种是为Set、Map单独新增一个用来遍历的API,另一种是为Set、Map、Array、Object新增一个统一的遍历API,显然,第二种更好,ES6也就顺其自然的需要一种设计标准,来统一所有可遍历类型的遍历方式。Iterator正是这样一种标准。或者说是一种规范理念- 就好像
JavaScript是ECMAScript标准的一种具体实现一样,Iterator标准的具体实现是Iterator遍历器。Iterator标准规定,所有部署了key值为[Symbol.iterator],且[Symbol.iterator]的value是标准的Iterator接口函数(标准的Iterator接口函数: 该函数必须返回一个对象,且对象中包含next方法,且执行next()能返回包含value/done属性的Iterator对象)的对象,都称之为可遍历对象,next()后返回的Iterator对象也就是Iterator遍历器
1 | //obj就是可遍历的,因为它遵循了Iterator标准,且包含[Symbol.iterator]方法,方法函数也符合标准的Iterator接口规范。 |
ES6给Set、Map、Array、String都加上了[Symbol.iterator]方法,且[Symbol.iterator]方法函数也符合标准的Iterator接口规范,所以Set、Map、Array、String默认都是可以遍历的
1 | //Array |
16、for…in 和for…of有什么区别?
如果看到问题十六,那么就很好回答。问题十六提到了ES6统一了遍历标准,制定了可遍历对象,那么用什么方法去遍历呢?答案就是用
for...of。ES6规定,有所部署了载了Iterator接口的对象(可遍历对象)都可以通过for...of去遍历,而for..in仅仅可以遍历对象
- 这也就意味着,数组也可以用
for...of遍历,这极大地方便了数组的取值,且避免了很多程序用for..in去遍历数组的恶习
17、Generator函数是什么,有什么作用?
- 如果说
JavaScript是ECMAScript标准的一种具体实现、Iterator遍历器是Iterator的具体实现,那么Generator函数可以说是Iterator接口的具体实现方式。 - 执行
Generator函数会返回一个遍历器对象,每一次Generator函数里面的yield都相当一次遍历器对象的next()方法,并且可以通过next(value)方法传入自定义的value,来改变Generator函数的行为。 Generator函数可以通过配合Thunk函数更轻松更优雅的实现异步编程和控制流管理。
18、async函数是什么,有什么作用?
async函数可以理解为内置自动执行器的Generator函数语法糖,它配合ES6的Promise近乎完美的实现了异步编程解决方案
19、Class、extends是什么,有什么作用?
ES6的class可以看作只是一个ES5生成实例对象的构造函数的语法糖。它参考了java语言,定义了一个类的概念,让对象原型写法更加清晰,对象实例化更像是一种面向对象编程。Class类可以通过extends实现继承。它和ES5构造函数的不同点
类的内部定义的所有方法,都是不可枚举的
1 | ///ES5 |
ES6的class类必须用new命令操作,而ES5的构造函数不用new也可以执行。ES6的class类不存在变量提升,必须先定义class之后才能实例化,不像ES5中可以将构造函数写在实例化之后。ES5的继承,实质是先创造子类的实例对象this,然后再将父类的方法添加到this上面。ES6的继承机制完全不同,实质是先将父类实例对象的属性和方法,加到this上面(所以必须先调用super方法),然后再用子类的构造函数修改this。
20、module、export、import是什么,有什么作用?
module、export、import是ES6用来统一前端模块化方案的设计思路和实现方案。export、import的出现统一了前端模块化的实现方案,整合规范了浏览器/服务端的模块化方法,用来取代传统的AMD/CMD、requireJS、seaJS、commondJS等等一系列前端模块不同的实现方案,使前端模块化更加统一规范,JS也能更加能实现大型的应用程序开发。import引入的模块是静态加载(编译阶段加载)而不是动态加载(运行时加载)。import引入export导出的接口值是动态绑定关系,即通过该接口,可以取到模块内部实时的值
21、日常前端代码开发中,有哪些值得用ES6去改进的编程优化或者规范?
- 常用箭头函数来取代
var self = this;的做法。 - 常用
let取代var命令。 - 常用数组/对象的结构赋值来命名变量,结构更清晰,语义更明确,可读性更好。
- 在长字符串多变量组合场合,用模板字符串来取代字符串累加,能取得更好地效果和阅读体验。
- 用
Class类取代传统的构造函数,来生成实例化对象。 - 在大型应用开发中,要保持
module模块化开发思维,分清模块之间的关系,常用import、export方法。
22、ES6的了解
新增模板字符串(为JavaScript提供了简单的字符串插值功能)、箭头函数(操作符左边为输入的参数,而右边则是进行的操作以及返回的值Inputs=>outputs。)、for-of(用来遍历数据—例如数组中的值。)arguments对象可被不定参数和默认参数完美代替。ES6将promise对象纳入规范,提供了原生的Promise对象。增加了let和const命令,用来声明变量。增加了块级作用域。let命令实际上就增加了块级作用域。ES6规定,var命令和function命令声明的全局变量,属于全局对象的属性;let命令、const命令、class命令声明的全局变量,不属于全局对象的属性。。还有就是引入module模块的概念
23、说说你对Promise的理解
依照 Promise/A+ 的定义,Promise 有四种状态:
pending: 初始状态, 非 fulfilled 或 rejected.
fulfilled: 成功的操作.
rejected: 失败的操作.
settled: Promise已被fulfilled或rejected,且不是pending
另外, fulfilled 与 rejected 一起合称 settled
Promise 对象用来进行延迟(deferred) 和异步(asynchronous ) 计算
24、Promise 的构造函数
- 构造一个 Promise,最基本的用法如下:
1 | var promise = new Promise(function(resolve, reject) { |
Promise 实例拥有 then 方法(具有 then 方法的对象,通常被称为thenable)。它的使用方法如下:
1
promise.then(onFulfilled, onRejected)
接收两个函数作为参数,一个在 fulfilled 的时候被调用,一个在rejected的时候被调用,接收参数就是 future,onFulfilled 对应 resolve, onRejected 对应 reject
什么是 Promise ?
- Promise 就是一个对象,用来表示并传递异步操作的最终结果
- Promise 最主要的交互方式:将回调函数传入 then 方法来获得最终结果或出错原因
- Promise 代码书写上的表现:以“链式调用”代替回调函数层层嵌套(回调地狱)
25、谈一谈你了解ECMAScript6的新特性?
- 块级作用区域
let a = 1; - 可定义常量
const PI = 3.141592654; - 变量解构赋值
var [a, b, c] = [1, 2, 3]; - 字符串的扩展(模板字符串)
var sum =${a + b}; - 数组的扩展(转换数组类型)
Array.from($('li')); - 函数的扩展(扩展运算符)
[1, 2].push(...[3, 4, 5]); - 对象的扩展(同值相等算法)
Object.is(NaN, NaN); - 新增数据类型(Symbol)
let uid = Symbol('uid'); - 新增数据结构(Map)
let set = new Set([1, 2, 2, 3]); - for…of循环
for(let val of arr){}; - Promise对象
var promise = new Promise(func); - Generator函数
function* foo(x){yield x; return x*x;} - 引入Class(类)
class Foo {} - 引入模块体系
export default func; - 引入async函数[ES7]
1 | async function asyncPrint(value, ms) { |
26、Object.is() 与原来的比较操作符 ===、== 的区别?
- == 相等运算符,比较时会自动进行数据类型转换
- === 严格相等运算符,比较时不进行隐式类型转换
- Object.is 同值相等算法,在 === 基础上对 0 和 NaN 特别处理
1 | +0 === -0 //true |
27、什么是 Babel
- Babel 是一个 JS 编译器,自带一组 ES6 语法转化器,用于转化 JS 代码。
这些转化器让开发者提前使用最新的 JS语法(ES6/ES7),而不用等浏览器全部兼容。 - Babel 默认只转换新的 JS 句法(syntax),而不转换新的API。
如何解决跨域问题
JSONP:
- 原理是:动态插入
script标签,通过script标签引入一个js文件,这个js文件载入成功后会执行我们在url参数中指定的函数,并且会把我们需要的json数据作为参数传入 - 由于同源策略的限制,
XmlHttpRequest只允许请求当前源(域名、协议、端口)的资源,为了实现跨域请求,可以通过script标签实现跨域请求,然后在服务端输出JSON数据并执行回调函数,从而解决了跨域的数据请求 - 优点是兼容性好,简单易用,支持浏览器与服务器双向通信。缺点是只支持GET请求
JSONP:json+padding(内填充),顾名思义,就是把JSON填充到一个盒子里
1 | function createJs(sUrl){ |
CORS
- 服务器端对于
CORS的支持,主要就是通过设置Access-Control-Allow-Origin来进行的。如果浏览器检测到相应的设置,就可以允许Ajax进行跨域的访问
通过修改document.domain来跨子域
- 将子域和主域的
document.domain设为同一个主域.前提条件:这两个域名必须属于同一个基础域名!而且所用的协议,端口都要一致,否则无法利用document.domain进行跨域。主域相同的使用document.domain
使用window.name来进行跨域
window对象有个name属性,该属性有个特征:即在一个窗口(window)的生命周期内,窗口载入的所有的页面都是共享一个window.name的,每个页面对window.name都有读写的权限,window.name是持久存在一个窗口载入过的所有页面中的
使用HTML5中新引进的window.postMessage方法来跨域传送数据
- 还有
flash、在服务器上设置代理页面等跨域方式。个人认为window.name的方法既不复杂,也能兼容到几乎所有浏览器,这真是极好的一种跨域方法
如何解决跨域问题?
jsonp、iframe、window.name、window.postMessage、服务器上设置代理页面如何解决跨域问题?
document.domain + iframe:要求主域名相同 //只能跨子域JSONP(JSON with Padding)``:response: callback(data)`` //只支持 GET 请求- 跨域资源共享
CORS(XHR2)``:Access-Control-Allow` //兼容性 IE10+ - 跨文档消息传输(HTML5):
postMessage + onmessage//兼容性 IE8+ WebSocket(HTML5):new WebSocket(url) + onmessage//兼容性 IE10+- 服务器端设置代理请求:服务器端不受同源策略限制
Cookie
请你谈谈Cookie的弊端
cookie虽然在持久保存客户端数据提供了方便,分担了服务器存储的负担,但还是有很多局限性的
第一:每个特定的域名下最多生成20个cookie
1.IE6或更低版本最多20个cookie
2.IE7和之后的版本最后可以有50个cookie。
3.Firefox最多50个cookie
4.chrome和Safari没有做硬性限制
请你谈谈Cookie的弊端?
- 每个特定的域名下最多生成的 cookie 个数有限制
- IE 和 Opera 会清理近期最少使用的 cookie,Firefox 会随机清理 cookie
- cookie 的最大大约为 4096 字节,为了兼容性,一般设置不超过 4095 字节
- 如果 cookie 被人拦截了,就可以取得所有的 session 信息
MVC
说说你对MVC和MVVM的理解
- MVC
View 传送指令到 Controller
Controller 完成业务逻辑后,要求 Model 改变状态
Model 将新的数据发送到 View,用户得到反馈
所有通信都是单向的
Git
git fetch和git pull的区别
- git pull:相当于是从远程获取最新版本并merge到本地
- git fetch:相当于是从远程获取最新版本到本地,不会自动merge
数据结构
栈和队列的区别?
- 栈的插入和删除操作都是在一端进行的,而队列的操作却是在两端进行的。
- 队列先进先出,栈先进后出。
- 栈只允许在表尾一端进行插入和删除,而队列只允许在表尾一端进行插入,在表头一端进行删除
栈和堆的区别?
- 栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。
- 堆区(heap) — 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收。
- 堆(数据结构):堆可以被看成是一棵树,如:堆排序;
- 栈(数据结构):一种先进后出的数据结构
快速 排序的思想并实现一个快排?
“快速排序”的思想很简单,整个排序过程只需要三步:
- (1)在数据集之中,找一个基准点
- (2)建立两个数组,分别存储左边和右边的数组
- (3)利用递归进行下次比较
1 | function quickSort(arr){ |
数据库
说说mongoDB和MySQL的区别
MySQL是传统的关系型数据库,MongoDB则是非关系型数据库mongodb以BSON结构(二进制)进行存储,对海量数据存储有着很明显的优势。- 对比传统关系型数据库,NoSQL有着非常显著的性能和扩展性优势,与关系型数据库相比,MongoDB的优点有: ①弱一致性(最终一致),更能保证用户的访问速度: ②文档结构的存储方式,能够更便捷的获取数据
手写代码
手写事件侦听器,并要求兼容浏览器
1 | var eventUtil = { |
手写事件模型
1 | var Event = (function () { |
手写事件代理,并要求兼容浏览器
1 | function delegateEvent(parentEl, selector, type, fn) { |
手写事件触发器,并要求兼容浏览器
1 | var fireEvent = function(element, event){ |
手写 Function.bind 函数
1 | if (!Function.prototype.bind) { |
手写数组快速排序
1 | var quickSort = function(arr) { |
手写数组冒泡排序
1 | var bubble = function(arr){ |
手写数组去重
1 | Array.prototype.unique = function() { return [...new Set(this)];}; |
将url的查询参数解析成字典对象
1 | function parseQuery(url) { |
封装函数节流函数
1 | var throttle = function(fn, delay, mustRunDelay){ |
用JS实现千位分隔符
1 | function test1(num){ |
线程与进程的区别
- 一个程序至少有一个进程,一个进程至少有一个线程
- 线程的划分尺度小于进程,使得多线程程序的并发性高
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存
- 线程不能够独立执行,必须应用程序提供多个线程执行控制
其他
如何评价AngularJS和BackboneJS
backbone具有依赖性,依赖underscore.js。Backbone + Underscore + jQuery(or Zepto)就比一个AngularJS 多出了2 次HTTP请求.
Backbone的Model没有与UI视图数据绑定,而是需要在View中自行操作DOM来更新或读取UI数据。AngularJS与此相反,Model直接与UI视图绑定,Model与UI视图的关系,通过directive封装,AngularJS内置的通用directive,就能实现大部分操作了,也就是说,基本不必关心Model与UI视图的关系,直接操作Model就行了,UI视图自动更新
AngularJS的directive,你输入特定数据,他就能输出相应UI视图。是一个比较完善的前端MVW框架,包含模板,数据双向绑定,路由,模块化,服务,依赖注入等所有功能,模板功能强大丰富,并且是声明式的,自带了丰富的 Angular 指令
谈谈你对重构的理解
网站重构:在不改变外部行为的前提下,简化结构、添加可读性,而在网站前端保持一致的行为。也就是说是在不改变UI的情况下,对网站进行优化, 在扩展的同时保持一致的UI
对于传统的网站来说重构通常是:
表格(table)布局改为DIV+CSS
使网站前端兼容于现代浏览器(针对于不合规范的CSS、如对IE6有效的)
对于移动平台的优化
针对于SEO进行优化
深层次的网站重构应该考虑的方面
说说你对前端架构师的理解
- 负责前端团队的管理及与其他团队的协调工作,提升团队成员能力和整体效率;带领团队完成研发工具及平台前端部分的设计、研发和维护; 带领团队进行前端领域前沿技术研究及新技术调研,保证团队的技术领先负责前端开发规范制定、功能模块化设计、公共组件搭建等工作,并组织培训
什么样的前端代码是好的
- 高复用低耦合,这样文件小,好维护,而且好扩展。
谈谈你对webpack的看法
WebPack 是一个模块打包工具,你可以使用WebPack管理你的模块依赖,并编绎输出模块们所需的静态文件。它能够很好地管理、打包Web开发中所用到的HTML、Javascript、CSS以及各种静态文件(图片、字体等),让开发过程更加高效。对于不同类型的资源,webpack有对应的模块加载器。webpack模块打包器会分析模块间的依赖关系,最后 生成了优化且合并后的静态资源
页面重构怎么操作?
网站重构:不改变UI的情况下,对网站进行优化,在扩展的同时保持一致的UI。
页面重构可以考虑的方面:
- 升级第三方依赖
- 使用HTML5、CSS3、ES6 新特性
- 加入响应式布局
- 统一代码风格规范
- 减少代码间的耦合
- 压缩/合并静态资源
- 程序的性能优化
- 采用CDN来加速资源加载
- 对于JS DOM的优化
- HTTP服务器的文件缓存
列举IE与其他浏览器不一样的特性?
- IE 的渲染引擎是 Trident 与 W3C 标准差异较大:例如盒子模型的怪异模式
- JS 方面有很多独立的方法,例如事件处理不同:绑定/删除事件,阻止冒泡,阻止默认事件等
- CSS 方面也有自己独有的处理方式,例如设置透明,低版本IE中使用滤镜的方式
是否了解公钥加密和私钥加密?
- 私钥用于对数据进行签名,公钥用于对签名进行验证
- 网站在浏览器端用公钥加密敏感数据,然后在服务器端再用私钥解密
WEB应用从服务器主动推送Data到客户端有那些方式?
- AJAX 轮询
- html5 服务器推送事件
(new EventSource(SERVER_URL)).addEventListener("message", func); - html5 Websocket
(new WebSocket(SERVER_URL)).addEventListener("message", func);
你怎么看待 Web App/hybrid App/Native App?(移动端前端 和 Web 前端区别?)
Web App(HTML5):采用HTML5生存在浏览器中的应用,不需要下载安装
- 优点:开发成本低,迭代更新容易,不需用户升级,跨多个平台和终端
- 缺点:消息推送不够及时,支持图形和动画效果较差,功能使用限制(相机、GPS等)
Hybrid App(混合开发):UI WebView,需要下载安装
- 优点:接近 Native App 的体验,部分支持离线功能
- 缺点:性能速度较慢,未知的部署时间,受限于技术尚不成熟
Native App(原生开发):依托于操作系统,有很强的交互,需要用户下载安装使用
- 优点:用户体验完美,支持离线工作,可访问本地资源(通讯录,相册)
- 缺点:开发成本高(多系统),开发成本高(版本更新),需要应用商店的审核
Web 前端开发的注意事项?
- 特别设置 meta 标签 viewport
- 百分比布局宽度,结合 box-sizing: border-box;
- 使用 rem 作为计算单位。rem 只参照跟节点 html 的字体大小计算
- 使用 css3 新特性。弹性盒模型、多列布局、媒体查询等
- 多机型、多尺寸、多系统覆盖测试
在设计 Web APP 时,应当遵循以下几点
- 简化不重要的动画/动效/图形文字样式
- 少用手势,避免与浏览器手势冲突
- 减少页面内容,页面跳转次数,尽量在当前页面显示
- 增强 Loading 趣味性,增强页面主次关系
平时如何管理你的项目?
- 规定全局样式、公共脚本
- 严格要求代码注释(html/js/css)
- 严格要求静态资源存放路径
- Git 提交必须填写说明
如何设计突发大规模并发架构?
- 及时响应(NoSQL缓存)
- 数据安全(数据备份)
- 负载均衡
说说最近最流行的一些东西吧?
- ES6、Node、React、Webpack
开放性的题目
对前端工程师这个职位是怎么样理解的?它的前景会怎么样?
- 前端是最贴近用户的程序员,比后端、数据库、产品经理、运营、安全都近
- 实现界面交互
- 提升用户体验
- 有了
Node.js,前端可以实现服务端的一些事情
- 前端是最贴近用户的程序员,前端的能力就是能让产品从
90分进化到100分,甚至更好, - 参与项目,快速高质量完成实现效果图,精确到
1px - 与团队成员,
UI设计,产品经理的沟通; - 做好的页面结构,页面重构和用户体验;
- 处理
hack,兼容、写出优美的代码格式; - 针对服务器的优化、拥抱最新前端技术。
平时如何管理你的项目?
- 先期团队必须确定好全局样式(
globe.css),编码模式(utf-8) 等; - 编写习惯必须一致(例如都是采用继承式的写法,单样式都写成一行);
- 标注样式编写人,各模块都及时标注(标注关键样式调用的地方);
- 页面进行标注(例如 页面 模块 开始和结束);
CSS跟HTML分文件夹并行存放,命名都得统一(例如style.css);JS分文件夹存放 命名以该JS功能为准的英文翻译- 图片采用整合的
images.pngpng8格式文件使用 - 尽量整合在一起使用方便将来的管理
一些开放性题目
- 自我介绍:除了基本个人信息以外,面试官更想听的是你与众不同的地方和你的优势
- 项目介绍
- 如何看待前端开发?
- 平时是如何学习前端开发的?
- 未来三到五年的规划是怎样的?
你觉得前端工程的价值体现在哪
- 为简化用户使用提供技术支持(交互部分)
- 为多个浏览器兼容性提供支持
- 为提高用户浏览速度(浏览器性能)提供支持
- 为跨平台或者其他基于
webkit或其他渲染引擎的应用提供支持 - 为展示数据提供支持(数据接口)
数据结构与算法之美
《数据结构与算法之美》是极客时间上的一个算法学习系列,在学习之后特在此做记录和总结。
数据结构和算法是相辅相成的,数据结构是为算法服务的,算法要作用在特定的数据结构之上。
- 从广义上讲,数据结构就是指一组数据的存储结构。算法就是操作数据的一组方法。
- 从狭义上讲,是指某些著名的数据结构和算法,比如队列、栈、堆、二分查找、动态规划等。
一、时间复杂度分析
大 O 复杂度表示法,实际上并不具体表示代码真正的执行时间,而是表示代码执行时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度。
分析一段代码的时间复杂度有三个比较实用的方法:
- 只关注循环执行次数最多的一段代码。例如代码被执行了 n 次,所以总的时间复杂度就是 O(n)。
- 加法法则:总复杂度等于量级最大的那段代码的复杂度。例如两段代码的复杂度分别为O(n) 和 O(n^2),那么整段代码的时间复杂度就为 O(n^2)。
- 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积。假设 T1(n) = O(n),T2(n) = O(n^2),则 T1(n) * T2(n) = O(n^3)
1)多项式量级
非多项式量级只有两个:O(2^n) 和 O(n!)。接下来主要来看几种常见的多项式时间复杂度。
- O(1),并不是指只执行了一行代码,只要算法中不存在循环语句、递归语句,即使有成千上万行的代码,其时间复杂度也是Ο(1)。
- O(logn)、O(nlogn),假设代码的执行次数是2^x=n,那么x=x=log2^n,因此这段代码的时间复杂度就是 O(log2^n)。
- O(m+n)、O(m*n),因为无法事先评估 m 和 n 谁的量级大,所以在表示复杂度的时候,就不能简单地利用加法法则,省略掉其中一个。
2)最好和最坏
最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。例如在最理想的情况下,要查找的变量 x 正好是数组的第一个元素。
最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。如果数组中没有要查找的变量 x,那么需要把整个数组都遍历一遍才行。
二、数据结构
1)数组
数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
- 线性表(Linear List)就是数据排成像一条线一样的结构。每个线性表上的数据最多只有前和后两个方向。比如数组、链表、队列、栈等。
- 在非线性表中,数据之间并不是简单的前后关系。比如二叉树、堆、图等。
在面试的时候,常常会问数组和链表的区别,很多人都回答说,“链表适合插入、删除,时间复杂度 O(1);数组适合查找,查找时间复杂度为 O(1)”。
实际上,这种表述是不准确的。数组是适合查找操作,但是查找的时间复杂度并不为 O(1)。即便是排好序的数组,你用二分查找,时间复杂度也是 O(logn)。
所以,正确的表述应该是,数组支持随机访问,根据下标随机访问的时间复杂度为 O(1)。
2)链表
数组和链表的区别如下:
- 数组需要一块连续的内存空间来存储,对内存的要求比较高。链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
- 链表删除一个数据是非常快速的,只需考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。而链表随机访问的性能没有数组好,需要 O(n) 的时间复杂度。
三种最常见的链表结构,它们分别是:单链表、双向链表和循环链表。
- 单链表通过指针将一组零散的内存块串联在一起。其中,把内存块称为链表的“结点”。为了将所有的结点串起来,每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址。把这个记录下个结点地址的指针叫作后继指针 next。
- 循环链表是一种特殊的单链表。其优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。
- 双向链表支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
检查链表代码是否正确的边界条件有这样几个:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
5 个常见的链表操作。
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
3)栈
后进者先出,先进者后出,这就是典型的“栈”结构。从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
栈既可以用数组来实现(顺序栈),也可以用链表来实现(链式栈)。
比较经典的一个应用场景就是函数调用栈。另一个常见的应用场景,编译器如何利用栈来实现表达式求值。
除了用栈来实现表达式求值,还可以借助栈来检查表达式中的括号是否匹配。比如,{[] ()[{}]}或[{()}([])]等都为合法格式,而{[}()]或[({)]为不合法的格式。
4)队列
先进者先出,这就是典型的“队列”。队列跟栈非常相似,支持的操作也很有限
对于栈来说,只需要一个栈顶指针就可以了。但是队列需要两个指针:一个是 head 指针,指向队头;一个是 tail 指针,指向队尾。
作为一种非常基础的数据结构,队列的应用也非常广泛。
- 循环队列长得像一个环。原本数组是有头有尾的,是一条直线。现在把首尾相连,扳成了一个环。
- 阻塞队列是在队列为空的时候,从队头取数据会被阻塞。如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据。
- 并发队列最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。
5)跳表
跳表(Skip List)是一种各方面性能都比较优秀的动态数据结构,可以支持快速地插入、删除、查找操作,可以替代红黑树(Red-black Tree)。
在链表上加一层索引之后,查找一个结点需要遍历的结点个数减少了,也就是说查找效率提高了。这种链表加多级索引的结构,就是跳表。
在一个单链表中查询某个数据的时间复杂度是 O(n),在跳表中查询任意数据的时间复杂度就是 O(logn),空间复杂度是 O(n)。
6)散列表
散列表(Hash Table)平时也叫“哈希表”或者“Hash 表”。散列表用的是数组支持的按照下标随机访问数据的特性,时间复杂度是 O(1) ,所以散列表其实就是数组的一种扩展,由数组演化而来。
散列函数定义成 hash(key),其中 key 表示元素的键值,hash(key) 的值表示经过散列函数计算得到的散列值。其设计的基本要求:
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
- 开放寻址法的核心思想是,如果出现了散列冲突,就重新探测一个空闲位置,将其插入。
- 在散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
7)二叉树
树(Tree)有三个比较相似的概念:高度(Height)、深度(Depth)、层(Level)。
除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树。
二叉树的遍历有三种,前序遍历、中序遍历和后序遍历。遍历的时间复杂度是 O(n)。
- 前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
- 中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身。
二叉查找树(Binary Search Tree,BST)要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是 O(n),非常高效。
8)红黑树
平衡二叉树的严格定义是这样的:二叉树中任意一个节点的左右子树的高度相差不能大于 1。
红黑树的英文是“Red-Black Tree”,简称 R-B Tree。它是一种不严格的平衡二叉查找树。
红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点;
9)堆
堆(Heap)是一种特殊的树。
- 堆是一个完全二叉树;
- 堆中每一个节点的值都必须大于等于或小于等于其子树中每个节点的值,前者叫大顶堆,后者叫小顶堆。
完全二叉树比较适合用数组来存储。数组中下标为 i 的节点的左子节点,就是下标为 i2 的节点,右子节点就是下标为 i2+1 的节点,父节点就是下标为 2/i 的节点。
将堆进行调整,让其重新满足堆的特性,这个过程叫做堆化(heapify)。堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。
堆这种数据结构几个非常重要的应用:优先级队列、求 Top K 和求中位数。
10)图
图(Graph)和树比起来,这是一种更加复杂的非线性表结构。
树中的元素称为节点,图中的元素就叫做顶点(vertex)。图中的一个顶点可以与任意其他顶点建立连接关系。把这种建立的关系叫做边(edge)。度(degree)就是跟顶点相连接的边的条数。
把这种边有方向的图叫做“有向图”。以此类推,把边没有方向的图就叫做“无向图”。在有向图中,把度分为入度(In-degree)和出度(Out-degree)。
11)Trie树
Trie 树,也叫“字典树”。它是一个树形结构,一种专门处理字符串匹配的数据结构,可解决在一组字符串集合中快速查找某个字符串的问题。
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
每次查询时,如果要查询的字符串长度是 k,那只需要比对大约 k 个节点,就能完成查询操作。
跟原本那组字符串的长度和个数没有任何关系。所以说,构建好 Trie 树后,在其中查找字符串的时间复杂度是 O(k),k 表示要查找的字符串的长度。
三、算法
1)递归
只要同时满足以下三个条件,就可以用递归来解决。
- 一个问题的解可以分解为几个子问题的解。
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样。
- 存在递归终止条件。
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区。很多时候,我们理解起来比较吃力,主要原因就是自己给自己制造了这种理解障碍。
因此,编写递归代码的关键是,只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
2)排序
分析一个排序算法,要从几个方面入手:
- 排序算法的执行效率,衡量方面:
- 最好情况、最坏情况、平均情况时间复杂度。
- 时间复杂度的系数、常数 、低阶。
- 比较次数和交换(或移动)次数。
- 排序算法的内存消耗,针对排序算法的空间复杂度,我们还引入了一个新的概念,原地排序(Sorted in place),特指空间复杂度是 O(1) 的排序算法。
- 排序算法的稳定性,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
常见的排序算法有:
- 冒泡排序(Bubble Sort),只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。
- 插入排序(Insertion Sort),取未排序区间中的元素,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间数据一直有序。
- 选择排序(Selection Sort),思路有点类似插入排序,也分已排序区间和未排序区间,但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
- 归并排序(Merge Sort),如果要排序一个数组,先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
- 快速排序(Quick Sort),利用的也是分治思想,如果要排序数组中下标从 p 到 r 之间的一组数据,选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。归并排序和快速排序的区别:
- 归并排序的处理过程是由下到上的,先处理子问题,然后再合并。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。
- 快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。快速排序通过设计巧妙的原地分区函数,可以实现原地排序。
- 桶排序(Bucket Sort),将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。
- 计数排序(Counting Sort),桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
- 堆排序,堆排序的过程大致分解成两个大的步骤,首先将数组原地建成一个堆,建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。
3)二分查找
二分查找(Binary Search)针对的是一个有序的数据集合,查找思想有点类似分治思想。每次都通过跟区间的中间元素对比,将待查找的区间缩小为之前的一半,直到找到要查找的元素,或者区间被缩小为 0。
容易出错的 3 个地方
- 循环退出条件,注意是 low<=high,而不是 low。
- mid 的取值,如果 low 和 high 比较大的话,两者之和就有可能会溢出。改成 low + ((high - low) >> 1) 即可。
- low 和 high 的更新,low=mid+1,high=mid-1。注意这里的 +1 和 -1。
二分查找的时间复杂度是 O(logn),查找数据的效率非常高。不过,并不是什么情况下都可以用二分查找,它的应用场景是有很大局限性的。
- 二分查找依赖的是顺序表结构,简单点说就是数组。
- 二分查找针对的是有序数据。
- 数据量太小不适合二分查找。
- 数据量太大也不适合二分查找。
变形问题:
- 查找第一个值等于给定值的元素。
- 查找最后一个值等于给定值的元素。
- 查找第一个大于等于给定值的元素。
- 查找最后一个小于等于给定值的元素。
4)哈希算法
哈希算法历史悠久,业界著名的哈希算法也有很多,比如 MD5、SHA 等。
将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值。
设计一个优秀的哈希算法需要满足的几点要求:
- 从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法);
- 对输入数据非常敏感,哪怕原始数据只修改了一个 Bit,最后得到的哈希值也大不相同;
- 散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小;
- 哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值。
哈希算法的应用选了最常见的七个,分别是安全加密、唯一标识、数据校验、散列函数、负载均衡、数据分片、分布式存储。
5)字符串匹配
- BF 算法是Brute Force的简称,中文叫作暴力匹配算法,也叫朴素匹配算法。在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。把主串的长度记作 n,模式串的长度记作 m。
- RK 算法全称叫 Rabin-Karp 算法,每次检查主串与子串是否匹配,需要依次比对每个字符。通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。
- BM 算法全称叫 Boyer-Moore 算法, 其性能是著名的KMP 算法的 3 到 4 倍。在模式串与主串匹配的过程中,当模式串和主串某个字符不匹配的时候,能够跳过一些肯定不会匹配的情况,将模式串往后多滑动几位。
- KMP 算法的核心思想和 BM 算法非常相近。假设主串是 a,模式串是 b。在模式串与主串匹配的过程中,当遇到不可匹配的字符的时候,希望找到一些规律,可以将模式串往后多滑动几位,跳过那些肯定不会匹配的情况。
- 多模式串匹配算法只需要扫描一遍主串,就能在主串中一次性查找多个模式串是否存在,从而大大提高匹配效率。对敏感词字典进行预处理,构建成 Trie 树结构。经典的多模式串匹配算法:AC 自动机。
6)贪心算法
贪心算法(greedy algorithm)有很多经典的应用,比如霍夫曼编码(Huffman Coding)、Prim 和 Kruskal 最小生成树算法、还有 Dijkstra 单源最短路径算法。
贪心算法解决问题的步骤:
- 第一步,当看到这类问题的时候,首先要联想到贪心算法:针对一组数据,定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
- 第二步,尝试看下这个问题是否可以用贪心算法解决:每次选择当前情况下,在对限制值同等贡献量的情况下,对期望值贡献最大的数据。
- 第三步,举几个例子看下贪心算法产生的结果是否是最优的。
实际上,用贪心算法解决问题的思路,并不总能给出最优解。贪心算法的题目包括分糖果、钱币找零、区间覆盖等。
7)分治算法
分治算法(divide and conquer)的核心思想其实就是四个字,分而治之 ,也就是将原问题划分成 n 个规模较小,并且结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
分治算法的递归实现中,每一层递归都会涉及这样三个操作:
- 分解:将原问题分解成一系列子问题;
- 解决:递归地求解各个子问题,若子问题足够小,则直接求解;
- 合并:将子问题的结果合并成原问题。
分治算法能解决的问题,一般需要满足下面这几个条件:
- 原问题与分解成的小问题具有相同的模式;
- 原问题分解成的子问题可以独立求解,子问题之间没有相关性,这一点是分治算法跟动态规划的明显区别;
- 具有分解终止条件,也就是说,当问题足够小时,可以直接求解;
- 可以将子问题合并成原问题,而这个合并操作的复杂度不能太高,否则就起不到减小算法总体复杂度的效果了。
8)回溯算法
回溯的处理思想,有点类似枚举搜索。枚举所有的解,找到满足期望的解。为了有规律地枚举所有可能的解,避免遗漏和重复,把问题求解的过程分为多个阶段。
每个阶段,都会面对一个岔路口,先随意选一条路走,当发现这条路走不通的时候(不符合期望的解),就回退到上一个岔路口,另选一种走法继续走。
回溯算法的应用包括深度优先搜索、八皇后、0-1 背包问题、图的着色、旅行商问题、数独、全排列、正则表达式匹配等。
9)动态规划
动态规划(Dynamic Programming)比较适合用来求解最优问题,比如求最大值、最小值等等。
它的主要学习难点跟递归类似,那就是,求解问题的过程不太符合人类常规的思维方式。
把问题分解为多个阶段,每个阶段对应一个决策。记录每一个阶段可达的状态集合(去掉重复的),然后通过当前阶段的状态集合,来推导下一个阶段的状态集合,动态地往前推进。
一个模型”指的是动态规划适合解决的问题的模型。这个模型定义为“多阶段决策最优解模型”。“三个特征”分别是最优子结构、无后效性和重复子问题。
- 最优子结构指的是,问题的最优解包含子问题的最优解。反过来说就是,可以通过子问题的最优解,推导出问题的最优解。
- 无后效性有两层含义,第一层含义是,在推导后面阶段的状态的时候,只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。
- 重复子问题。如果用一句话概括一下,那就是,不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态。
解决动态规划问题,一般有两种思路。
- 状态转移表法。状态表一般都是二维的,所以你可以把它想象成二维数组。其中,每个状态包含三个变量,行、列、数组值。根据决策的先后过程,从前往后递推关系,分阶段填充状态表中的每个状态。
- 状态转移方程法。根据最优子结构,写出递归公式,也就是所谓的状态转移方程。
说说TS和ES的区别,以及TS带来的好处?
目标:生命周期较长(常常持续几年)的复杂SPA应用,保障开发效率的同时提升代码的可维护性和线上运行时质量。
- 从开发效率上看,虽然需要多写一些类型定义代码,但TS在VSCode、WebStorm等IDE下可以做到智能提示,智能感知bug,同时我们项目常用的一些第三方类库框架都有TS类型声明,我们也可以给那些没有TS类型声明的稳定模块写声明文件,如我们的前端KOP框架(目前还是蚂蚁内部框架,类比dva),这在团队协作项目中可以提升整体的开发效率。
- 从可维护性上看,长期迭代维护的项目开发和维护的成员会有很多,团队成员水平会有差异,而软件具有熵的特质,长期迭代维护的项目总会遇到可维护性逐渐降低的问题,有了强类型约束和静态检查,以及智能IDE的帮助下,可以降低软件腐化的速度,提升可维护性,且在重构时,强类型和静态类型检查会帮上大忙,甚至有了类型定义,会不经意间增加重构的频率(更安全、放心)。
- 从线上运行时质量上看,我们现在的SPA项目的很多bug都是由于一些调用方和被调用方(如组件模块间的协作、接口或函数的调用)的数据格式不匹配引起的,由于TS有编译期的静态检查,让我们的bug尽可能消灭在编译器,加上IDE有智能纠错,编码时就能提前感知bug的存在,我们的线上运行时质量会更为稳定可控。
TS适合大规模JavaScript应用,正如他的官方宣传语JavaScript that scales。从以下几点可以看到TS在团队协作、可维护性、易读性、稳定性(编译期提前暴露bug)等方面上有着明显的好处:
- 加上了类型系统,对于阅读代码的人和编译器都是友好的。对阅读者来说,类型定义加上IDE的智能提示,增强了代码的易读型;对于编译器来说,类型定义可以让编译器揪出隐藏的bug。
- 类型系统+静态分析检查+智能感知/提示,使大规模的应用代码质量更高,运行时bug更少,更方便维护。
- 有类似VSCode这样配套的IDE支持,方便的查看类型推断和引用关系,可以更方便和安全的进行重构,再也不用全局搜索,一个个修改了。
- 给应用配置、应用状态、前后端接口及各种模块定义类型,整个应用都是一个个的类型定义,使协作更为方便、高效和安全。
TypeScript 简介及优缺点
TypeScript 是 JavaScript 的一个超集,提供了类型系统和对ES6的支持,可编译成纯 JavaScript,可以运行在任何浏览器上,TS编译工具也可运行在任何服务器和系统上
优点
- (1)增强代码的可读性和可维护性,强类型的系统相当于最好的文档,在编译时即可发现大部分的错误,增强编辑器的功能。
- (2)包容性,js文件可以直接改成 ts 文件,不定义类型可自动推论类型,可以定义几乎一切类型,ts 编译报错时也可以生成 js 文件,兼容第三方库,即使不是用ts编写的
- (3)有活跃的社区,大多数的第三方库都可提供给 ts 的类型定义文件,完全支持 es6 规范
缺点
- (1)增加学习成本,需要理解接口(Interfaces)和泛型(Generics),类(class),枚举类型(Enums)
- (2)短期增加开发成本,增加类型定义,但减少维护成本
- (3)ts 集成到构建流程需要一定的工作量
- (4)和有些库结合时不是很完美
TypeScript中的void和null与undefined两种类型的区别是什么?
ts中的null和undefined是其他类型的子类型,可以赋值给其他类型:
1 | // 方式1 |
但是void和其他类型是平等关系,不能直接赋值:
1 | let a: void; |
严格模式中
严格模式通过tsconfig.json配置,配置如下:
1 | { |
严格模式下,undefined和null不能给其他类型赋值,只能给他们自己的类型赋值。
1 | let a: null = null; |
但是undefined可以给void赋值:
1 | let c: void = undefined; |
TypeScript的类型推论
类型推论
如果没有明确的指定类型,那么 TypeScript 会依照类型推论(Type Inference)的规则推断出一个类型。
什么是类型推论
以下代码虽然没有指定类型,但是会在编译的时候报错:
1 | let myFavoriteNumber = 'seven'; |
事实上,它等价于:
1 | let myFavoriteNumber: string = 'seven'; |
TypeScript 会在没有明确的指定类型的时候推测出一个类型,这就是类型推论。
如果定义的时候没有赋值,不管之后有没有赋值,都会被推断成 any 类型而完全不被类型检查:
1 | let myFavoriteNumber; |
在TypeScript中,readonly和const两个关键字有什么区别?
相同点
readonly和const这二者都是常量,一旦初始化就不能在改变
不同点
- const只能在声明时初始化,而readonly既可以在声明中初始化,又可以在构造函数中初始化;
- const隐含static,不可以再写static const;readonly则不默认static,如需要可以写static readonly;
- const是编译期静态解析的常量(因此其表达式必须在编译时就可以求值);readonly则是运行期动态解析的常量;
- const既可用来修饰类中的成员,也可修饰函数体内的局部变量;readonly只可以用于修饰类中的成员。
什么是泛型?
泛型是程序设计语言中的一种风格或范式,相当于类型模板,允许在声明类、接口或函数等成员时忽略类型,而在未来使用时再指定类型,其主要目的是为它们提供有意义的约束,提升代码的可重用性。
一、泛型参数
当一个函数需要能处理多种类型的参数和返回值,并且还得约束它们之间的关系(例如类型要相同)时,就可以采用泛型的语法,如下所示。
1 | function send<T>(data: T): T { |
函数名称后面跟了,其中把T称为泛型参数或泛型变量,表示某种数据类型。注意,T只是个占位符,可以命名的更含语义,例如TKey、TValue等。在使用时,既可以指定类型,也可以利用类型推论自动确定类型,如下所示。
1 | send<number>(10); //指定类型 |
当需要处理T类型的数组时,可以像下面这么写。
1 | function send<T>(data: T[]): T[] { |
当指定一个泛型函数的类型时,需要包含泛型参数,如下所示,其中泛型参数和函数参数的名称都可与定义时的不同。
1 | let func: (<U>(data: U) => U) = send; |
泛型参数还支持传递多个,只需在声明时增加类型占位符即可。在下面的示例中,将T和U合并成了一个元组类型,还有许多其它用法,将在后面讲解。
1 | function send<T, U>(data: [T, U]): [T, U] { |
二、泛型接口
在接口中,可利用泛型来约束函数的结构,如下所示,接口中声明的调用签名包含泛型参数。
1 | interface Func { |
泛型参数还可以作为接口的一个参数存在,即把用尖括号包裹的泛型参数移到接口名称之后,如下所示。
1 | interface Func<T> { |
当把Func接口作为类型使用时,需要向其传入一个类型,例如上面赋值语句中的string。
三、泛型类
泛型类与泛型接口类似,也是在名称后添加泛型参数,如下所示,其中send属性中的“=>”符号不表示箭头函数,而是用来定义方法的返回值类型。
1 | class Person<T> { |
在实例化泛型类时,需要为其指定一种类型,如下所示。
1 | let person = new Person<string>(); |
注意,类的静态部分不能使用泛型参数。
四、泛型约束
在使用泛型时,由于事先不清楚参数的数据类型,因此不能随意调用它的属性或方法,甚至无法对其使用运算符。在下面的示例中,访问了data的length属性,但由于编译器无法确定它的类型,因此就会报错。
1 | function send<T>(data: T): T { |
TypeScript允许为泛型参数添加约束条件,从而就能调用相应的属性或方法了,如下所示,通过extends关键字约束T必须是string的子类型。
1 | function send<T extends string>(data: T): T { |
在添加了这个约束之后,send()函数就无法接收数字类型的参数了,如下所示。
1 | send("10"); //正确 |
1)创建类的实例
在使用泛型创建类的工厂函数时,需要声明T类型拥有构造函数,如下所示。
1 | class Programmer {} |
用“{new(): T}”替代原先的类型占位符,表示可以被new运算符实例化,并且得到的是T类型,另一种相同作用的写法如下所示。
1 | function create<T>(ctor: new()=>T): T { |
2)多个泛型参数
在TypeScript中,多个泛型参数之间也可以相互约束,如下所示,创建了基类Person和派生类Programmer,并将create()函数中的T约束为U的子类型。
1 | class Person { } |
当传递给create()函数的参数不符合约束条件时,就会在编译阶段报错,如下所示。
1 | create(Programmer, Person); //正确 |
TypeScript 类型兼容性整理
一、介绍
TypeScript里的类型兼容性是基于结构子类型的。结构类型是一种只使用其成员来描述类型的方式。
它正好与名义(nominal)类型形成对比。
TypeScript的结构性子类型是根据JavaScript代码的典型写法来设计的。因为JavaScript里广泛的使用匿名对象,例如函数表达式和对象字面量,所以使用结构类型系统来描述类型比名义类型系统更好。
1.基本规则,具有相同的属性
1 | // 基本规则是具有相同的属性 |
二、函数兼容性
1. 形参
1 | // 函数兼容性比较 |
2. 返回类型
1 | // 返回类型,需要被包含关系 |
3. 可选参数及剩余参数
比较函数兼容性的时候,可选参数与必须参数是可互换的。 源类型上有额外的可选参数不是错误,目标类型的可选参数在源类型里没有对应的参数也不是错误。
当一个函数有剩余参数时,它被当做无限个可选参数。
这对于类型系统来说是不稳定的,但从运行时的角度来看,可选参数一般来说是不强制的,因为对于大多数函数来说相当于传递了一些undefinded。
三、枚举
枚举类型与数字类型兼容,并且数字类型与枚举类型兼容。不同枚举类型之间是不兼容的。
1 | // 枚举 |
四、类
类与对象字面量和接口差不多,但有一点不同:类有静态部分和实例部分的类型。 比较两个类类型的对象时,只有实例的成员会被比较。 静态成员和构造函数不在比较的范围内。
1 | class Animal { |
私有成员会影响兼容性判断。 当类的实例用来检查兼容时,如果目标类型包含一个私有成员,那么源类型必须包含来自同一个类的这个私有成员。 这允许子类赋值给父类,但是不能赋值给其它有同样类型的类。
五、泛型
因为TypeScript是结构性的类型系统,类型参数只影响使用其做为类型一部分的结果类型。
1 | interface Empty<T> { |
六、高级注册
目前为止,我们使用了兼容性,它在语言规范里没有定义。 在TypeScript里,有两种类型的兼容性:子类型与赋值。 它们的不同点在于,赋值扩展了子类型兼容,允许给 any 赋值或从any取值和允许数字赋值给枚举类型或枚举类型赋值给数字。
语言里的不同地方分别使用了它们之中的机制。 实际上,类型兼容性是由赋值兼容性来控制的甚至在 implements 和 extends 语句里。
接口interface和类型别名type的用法区别
定义对象类型
接口interface和类型别名type用来定义对象类型时,都可以支持,而且泛型也可以使用。
1 | interface IPerson<T> { |
定义简单(基本数据)类型
类型别名type可以用来定义简单类型时,接口interface不支持定义简单类型
1 | type Name = string | number; |
定义函数类型
接口interface和类型别名type都支持用来定义函数类型,具体写法会存在区别,
1 | interface ISetPerson { |
被类实现
接口interface可以被类实现(implements),类型别名无法被类实现
1 | interface ISetPerson { |
自己能否继承(extends)
接口interface能继承(extends)其他的的接口,但是类型别名无法继承(extends)其他的类型别名,但可以使用交叉类型代替extends来达到同样的效果
1 | interface ICommon { |
类型别名type可以使用联合类型、交叉类型还有元组等类型
1 |
|
结合typeof使用
类型别名type最大的特点是可以结合typeof使用
1 | class Person { |
TypeScript 中的 d.ts 文件有什么作用
TypeScript 相比 JavaScript 增加了类型声明。这些类型声明帮助编译器识别类型,从而帮助开发者在编译阶段就能发现错误。
d.ts类型定义文件,我感觉现在对我的用处就是编辑器的智能提示
TypeScript 命名空间和模块
命名空间和模块
关于术语的说明:值得注意的是,在TypeScript 1.5中,命名法已经改变。
“内部模块”现在是”命名空间”。
“外部模块”现在只是”模块”,以便与ECMAScript 2015的术语保持一致(即module X {相当于现在首选的namespace X {)。
使用命名空间
命名空间只是全局命名空间中的JavaScript对象。
这使命名空间成为一个非常简单的构造。
它们可以跨多个文件,并且可以使用–outFile连接。
命名空间可以是在Web应用程序中构建代码的好方法,所有依赖项都包含在HTML页面中的<script>标记中。
就像所有全局命名空间污染一样,很难识别组件依赖性,尤其是在大型应用程序中。
使用模块
就像命名空间一样,模块可以包含代码和声明。
主要区别在于模块声明了它们的依赖关系。
模块还依赖于模块加载器(例如CommonJs/Require.js)。
对于小型JS应用程序而言,这可能不是最佳选择,但对于大型应用程序,成本具有长期模块化和可维护性优势。
模块为捆绑提供了更好的代码重用,更强的隔离和更好的工具支持。
值得注意的是,对于Node.js应用程序,模块是构造代码的默认方法和推荐方法。
从ECMAScript 2015开始,模块是该语言的本机部分,并且应该受到所有兼容引擎实现的支持。
因此,对于新项目,模块将是推荐的代码组织机制。
命名空间和模块的缺陷
下面我们将描述使用命名空间和模块时的各种常见缺陷,以及如何避免它们。
1 | /// <reference>-ing a module |
一个常见的错误是尝试使用/// <reference … />语法来引用模块文件,而不是使用import语句。
为了理解这种区别,我们首先需要了解编译器如何根据导入的路径找到模块的类型信息(例如…在,import x from “…”;const x = require(“…”);等等。路径。
编译器将尝试使用适当的路径查找.ts,.tsx和.d.ts。
如果找不到特定文件,则编译器将查找环境模块声明。
回想一下,这些需要在.d.ts文件中声明。
myModules.d.ts
1 | // In a .d.ts file or .ts file that is not a module: |
myOtherModule.ts
1 | /// <reference path="myModules.d.ts" /> |
这里的引用标记允许我们找到包含环境模块声明的声明文件。
这就是使用几个TypeScript示例使用的node.d.ts文件的方式。
无需命名空间
如果您要将程序从命名空间转换为模块,则可以很容易地得到如下所示的文件:
shapes.ts
1 | export namespace Shapes { |
这里的顶级模块Shapes无缘无故地包装了Triangle和Square。
这对您的模块的消费者来说是令人困惑和恼人的:
shapeConsumer.ts
1 | import * as shapes from "./shapes"; |
TypeScript中模块的一个关键特性是两个不同的模块永远不会为同一范围提供名称。
因为模块的使用者决定分配它的名称,所以不需要主动地将命名空间中的导出符号包装起来。
为了重申您不应该尝试命名模块内容的原因,命名空间的一般概念是提供构造的逻辑分组并防止名称冲突。
由于模块文件本身已经是逻辑分组,并且其顶级名称由导入它的代码定义,因此不必为导出的对象使用其他模块层。
这是一个修改过的例子:
shapes.ts
1 | export class Triangle { /* ... */ } |
shapeConsumer.ts
1 | import * as shapes from "./shapes"; |
模块的权衡
正如JS文件和模块之间存在一对一的对应关系一样,TypeScript在模块源文件与其发出的JS文件之间具有一对一的对应关系。
这样做的一个结果是,根据您定位的模块系统,无法连接多个模块源文件。
例如,在定位commonjs或umd时不能使用outFile选项,但使用TypeScript 1.8及更高版本时,可以在定位amd或system时使用outFile。
TypeScript 装饰器
- 装饰器是一种特殊类型的声明,本质上就是一个方法,可以注入到类、方法、属性、参数上,扩展其功能;
- 常见的装饰器:类装饰器、属性装饰器、方法装饰器、参数装饰器…
- 装饰器在写法上有:普通装饰器(无法传参)、装饰器工厂(可传参)
- 装饰器已是ES7的标准特性之一,是过去几年JS最大的成就之一!
- 启用装饰器:
1 | "compilerOptions": { |
类装饰器
类装饰器在类声明之前被声明,应用于类构造函数,可以监视、修改、替换类的定义,传入一个参数;
1 | function logClz(params: Function) { |
装饰器工厂:闭包,返回的函数才是真正的装饰器。
1 | function logClz(params: string) { |
重载构造函数
- 类装饰器表达式会在运行时当作函数被调用,类的构造函数作为其唯一的参数;
- 如果类装饰器返回一个值,它会使用提供的构造函数来替换类的声明;
1 | function logClz(target:any) { |
修改类的定义
1 | function fn(v: number) { |
T extends {new(...args: any[]): {}}:{new(...args: any[]): {}} 是对象字面量,等效于 new(...args: any[]) => {},意思是一个能 new 的函数,返回值类型是 {}
1 | function identity<T>(arg: T): T { |
属性装饰器
属性装饰器表达式会在运行时当作函数被调用,传入两个参数:
- 对于静态成员来说是类的构造函数,对于实例成员来说是类的原型对象;
- 成员的名字;
1 | function logProp(params: string) { |
方法装饰器
- 方法装饰器被应用到方法的属性描述符上,可以用来监视、修改、替换方法的定义;
- 方法装饰器会在运行时传入3个参数:
- 对于静态成员来说是类的构造函数,对于实例成员来说是类的原型对象;
- 成员的名字;
- 成员的属性描述符;
1 | function get(params: string) { |
方法参数装饰器
- 参数装饰器表达式会在运行时被调用,可以为类的原型增加一些元素数据,传入3个参数:
- 对于静态成员来说是类的构造函数,对于实例成员来说是类的原型对象;
- 方法名称,如果装饰的是构造函数的参数,则值为undefined
- 参数在函数参数列表中的索引;
1 | function logParams(params:any) { |
- 注意:参数装饰器只能用来监视一个方法的参数是否被传入;
- 参数装饰器在Angular中被广泛使用,特别是结合reflect-metadata库来支持实验性的Metadata API;
- 参数装饰器的返回值会被忽略。
装饰器的执行顺序
装饰器组合:TS支持多个装饰器同时装饰到一个声明上,语法支持从左到右,或从上到下书写;
1
2
3
4
5x
x在TypeScript里,当多个装饰器应用在一个声明上时会进行如下步骤的操作:
- 由上至下依次对装饰器表达式求值;
- 求值的结果会被当作函数,由下至上依次调用.
不同装饰器的执行顺序:属性装饰器 > 方法装饰器 > 参数装饰器 > 类装饰器
1 | function logClz11(params:string) { |
简单描述下微信小程序的相关文件类型?
微信小程序项目结构主要有四个文件类型, 如下
WXML (WeiXin Markup Language)是框架设计的一套标签语言,结合基础组件. 事件系统,可以构建出页面的结构。内部主要是微信自己定义的一套组件。
WXSS (WeiXin Style Sheets)是一套样式语言,用于描述 WXML 的组件样式,
js 逻辑处理,网络请求
json 小程序设置,如页面注册,页面标题及tabBar。
你是怎么封装微信小程序的数据请求的?
将所有的接口放在统一的js文件中并导出
在app. js中创建封装请求数据的方法
在子页面中调用封装的方法请求数据
有哪些参数传值的方法?
给HTML元素添加data-*属性来传递我们需要的值,然后通过e. currentTarget. dataset或onload的param参数获取。但data-名称不能有大写字母和不可以存放对象
设置id 的方法标识来传值通过e. currentTarget. id获取设置的id的值, 然后通过设置全局对象的方式来传递数值
在navigator中添加参数传值
你使用过哪些方法,来提高微信小程序的应用速度?
提高页面加载速度
用户行为预测
减少默认data的大小
组件化方案
小程序与原生App哪个好?
小程序除了拥有公众号的低开发成本. 低获客成本低以及无需下载等优势,在服务请求延时与用户使用体验是都得到了较大幅度 的提升,使得其能够承载跟复杂的服务功能以及使用户获得更好的用户体验
简述微信小程序原理?
微信小程序采用JavaScript. WXML. WXSS三种技术进行开发,从技术讲和现有的前端开发差不多,但深入挖掘的话却又有所不同。
JavaScript:首先JavaScript的代码是运行在微信App中的,并不是运行在浏览器中,因此一些H5技术的应用,需要微信App提供对应的API支持,而这限制住了H5技术的应用,且其不能称为严格的H5,可以称其为伪H5,同理,微信提供的独有的某些API,H5也不支持或支持的不是特别好。
WXML:WXML微信自己基于XML语法开发的,因此开发时,只能使用微信提供的现有标签,HTML的标签是无法使用的。
WXSS:WXSS具有CSS的大部分特性,但并不是所有的都支持,而且支持哪些,不支持哪些并没有详细的文档。
微信的架构,是数据驱动的架构模式,它的UI和数据是分离的,所有的页面更新,都需要通过对数据的更改来实现。
小程序分为两个部分webview和appService。其中webview主要用来展现UI,appService有来处理业务逻辑. 数据及接口调用。它们在两个进程中运行,通过系统层JSBridge实现通信,实现UI的渲染. 事件的处理
分析下微信小程序的优劣势?
优势:
无需下载,通过搜索和扫一扫就可以打开。
良好的用户体验:打开速度快。
开发成本要比App要低。
安卓上可以添加到桌面,与原生App差不多。
为用户提供良好的安全保障。小程序的发布,微信拥有一套严格的审查流程, 不能通过审查的小程序是无法发布到线上的。
劣势:
限制较多。页面大小不能超过1M。不能打开超过5个层级的页面。
样式单一。小程序的部分组件已经是成型的了,样式不可以修改。例如:幻灯片. 导航。
推广面窄,不能分享朋友圈,只能通过分享给朋友,附近小程序推广。其中附近小程序也受到微信的限制。
依托于微信,无法开发后台管理功能。
微信小程序与H5的区别?
- 运行环境的不同
传统的HTML5的运行环境是浏览器,包括webview,而微信小程序的运行环境并非完整的浏览器,是微信开发团队基于浏览器内核完全重构的一个内置解析器,针对小程序专门做了优化,配合自己定义的开发语言标准,提升了小程序的性能。
- 开发成本的不同
只在微信中运行,所以不用再去顾虑浏览器兼容性,不用担心生产环境中出现不可预料的奇妙BUG
- 获取系统级权限的不同
系统级权限都可以和微信小程序无缝衔接
- 应用在生产环境的运行流畅度
长久以来,当HTML5应用面对复杂的业务逻辑或者丰富的页面交互时,它的体验总是不尽人意,需要不断的对项目优化来提升用户体验。但是由于微信小程序运行环境独立
怎么解决小程序的异步请求问题?
在回调函数中调用下一个组件的函数:
app. js
1 | success: function(info) { |
index. js
1 | onLoad: function() { |
小程序的双向绑定和vue哪里不一样?
小程序直接this. data的属性是不可以同步到视图的,必须调用
1 | this.setData({ |
小程序的wxss和css有哪些不一样的地方?
wxss的图片引入需使用外链地址;
没有Body, 样式可直接使用import导入;
webview中的页面怎么跳回小程序中?
首先要引入最新版的jweixin-1.3.2.js,然后
1 | wx.miniProgram.navigateTo({ |
小程序关联微信公众号如何确定用户的唯一性?
使用wx. getUserInfo方法withCredentials为 true 时 可获取encryptedData,里面有 union_id。后端需要进行对称解密
如何实现下拉刷新?
用view代替scroll-view, , 设置onPullDownRefresh函数实现
使用webview直接加载要注意哪些事项?
必须要在小程序后台使用管理员添加业务域名;
h5页面跳转至小程序的脚本必须是jweixin-1.3.2.js及以上;
微信分享只可以都是小程序的主名称了,如果要自定义分享的内容,需小程序版本在1.7.1以上;
h5的支付不可以是微信公众号的appid,必须是小程序的appid,而且用户的openid也必须是用户和小程序的。
小程序调用后台接口遇到哪些问题?
数据的大小有限制,超过范围会直接导致整个小程序崩溃,除非重启小程序;
小程序不可以直接渲染文章内容页这类型的html文本内容,若需显示要借住插件,但插件渲染会导致页面加载变慢,所以最好在后台对文章内容的html进行过滤,后台直接处理批量替换p标签div标签为view标签,然后其它的标签让插件来做,减轻前端的时间。
webview的页面怎么跳转到小程序导航的页面?
小程序导航的页面可以通过switchTab,但默认情况是不会重新加载数据的。 若需加载新数据,则在success属性中加入以下代码即可:
1 | success: function(e) { |
webview的页面,则通过
1 | wx.miniProgram.switchTab({ |
小程序和Vue写法的区别?
循环遍历的时候:小程序是wx:for=”list”,而Vue是v-for=”(item, index) in list”
调用data模型的时候:小程序是this.data.uinfo,而Vue是this.uinfo;给模型赋值也不一样,小程序是this.setData({uinfo:1}),而Vue是直接this.uinfo=1
小程序生命周期
1 | // app.js |
1 | //index.js |
url构成
- protocol 协议,常用的协议是http
- hostname 主机地址,可以是域名,也可以是IP地址
- port 端口 http协议默认端口是:80端口,如果不写默认就是:80端口
- path 路径 网络资源在服务器中的指定路径
- parameter 参数 如果要向服务器传入参数,在这部分输入
- query 查询字符串 如果需要从服务器那里查询内容,在这里编辑
- fragment 片段 网页中可能会分为不同的片段,如果想访问网页后直接到达指定位置,可以在这部分设置
hash和history
hash
http://xxx.abc.com/#/xx。 有带#号,后面就是hash值的变化。改变后面的hash值,它不会向服务器发出请求,因此也就不会刷新页面。并且每次hash值发生改变的时候,会触发hashchange事件。因此我们可以通过监听该事件,来知道hash值发生了哪些变化。
history
HTML5的History API为浏览器的全局history对象增加了该扩展方法。它是一个浏览器的一个接口,在window对象中提供了onpopstate事件来监听历史栈的改变,只要历史栈有信息发生改变的话,就会触发该事件。提供了如下事件:
- history,go(-1); //
- history.back(); // 回退一条记录
- history.forward(); // 前进一条记录
- history.pushState(data[,title][,url]); // 向历史记录中追加一条记录
- history.replaceState(data[,title][,url]); // 替换当前页在历史记录中的信息。
vue3带来的新特性/亮点
Performance
Proxytree sharking
composition api
defineComponent, onMounted, onUnmounted, ref, setup 类似react hocks,代替mixinFragment, Teleport, Suspense
类似ReactFragment,Portal,SuspenseTypescript
Custom Render API
这个api定义了虚拟DOM的渲染规则,这意味着使用自定义API可以达到跨平台的目的。
尾递归优化递归
1 | function factorial(n) |
1 | function factorialTailRecursion(n, acc) |
揭秘React形成合成事件的过程
React的事件处理使用合成事件(SyntheticEvent),不是原生事件。
- 合成事件的异步访问
合适事件为了节约性能,使用对象池。当一个合成事件对象被使用完毕,即调用该对象的同步代码执行完毕,该对象会被再次利用。
其属性会被重置为null。所以异步访问合适事件的属性,是无效的。
解决方法有两种:
1.1 用变量记录事件属性值
用变量记录合成事件的属性值,在异步程序中访问,就没有任何问题了。
1 | function onClick(event) { |
1.2 用e.persist()方法
e.persist()方法,会将当前的合成事件对象,从对象池中移除,就不会回收该对象了。对象可以被异步程序访问到。
- 合成事件阻止冒泡
2.1 e.stopPropagation
只能阻止合成事件间冒泡,即下层的合成事件,不会冒泡到上层的合成事件。事件本身还都是在document上执行。最多只能阻止document事件不能再冒泡到window上。
2.2 e.nativeEvent.stopImmediatePropagation
能阻止合成事件不会冒泡到document上。
可以实现点击空白处关闭菜单的功能:
- 在菜单打开的一刻,在document上动态注册事件,用来关闭菜单。
- 点击菜单内部,由于不冒泡,会正常执行菜单点击。
- 点击菜单外部,执行document上事件,关闭菜单。
- 在菜单关闭的一刻,在document上移除该事件,这样就不会重复执行该事件,浪费性能。
也可以在window上注册事件,这样可以避开document。
px rem em vh vw的区别
px:指像素,相对长度单位,网页设计常用的基本单位。像素px是相对于显示器分辨率而言的。
em:相对长度单位。相对当前对象内文本的字体尺寸(参考物是父元素的font-size)
如果当前父元素的字体尺寸未设置,则相对于浏览器的默认字体尺寸。
特点:1、em的值并不是固定的;2、em会继承父级元素的字体大小。
rem:css3新增的一个相对单位,rem是相对于HTML根元素的字体大小(font-size)来计算的长度单位。
没有设置HTML的字体大小,就会以浏览器默认字体大小(16px)。
em与rem的区别:rem是相对于根元素(html)的字体大小,而em是相对于其父元素的字体大小。
两者使用规则:
1、如果这个属性根据它的font-size进行测量,则使用em
2、其他的一切事物属性均使用rem .
vw、vh、vmax、vmin这四个单位都是基于视口,
vw是相对视口(viewport)的宽度而定的,长度等于视口宽度的1/100
假如浏览器的宽度为200px,那么1vw就等于2px(200px/100)
vh是相对视口(viewport)的高度而定的。。。。
vmin和vmax是相对视口的高度和宽度两者之间的最小值或最大值。
LRU
内存管理的一种页面置换算法,对于在内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存而腾出空间来加载另外的数据。
keep-alive实现原理
keep-alive是Vue.js的一个内置组件。它能够不活动的组件实例保存在内存中,而不是直接将其销毁,它是一个抽象组件,不会被渲染到真实DOM中,也不会出现在父组件链中。
它提供了include与exclude两个属性,允许组件有条件地进行缓存。
深入keep-alive组件实现
说完了keep-alive组件的使用,我们从源码角度看一下keep-alive组件究竟是如何实现组件的缓存的呢?
created与destroyed钩子
created钩子会创建一个cache对象,用来作为缓存容器,保存vnode节点。
1 | created () { |
destroyed钩子则在组件被销毁的时候清除cache缓存中的所有组件实例。
1 | /* destroyed钩子中销毁所有cache中的组件实例 */ |
render
1 | render () { |
watch
用watch来监听include与exclude这两个属性的改变,在改变的时候修改cache缓存中的缓存数据。
1 | watch: { |
JSBridge
// WebViewJavascriptBridge是提前注入的一个全局变量用于javascript调用native提供的函数
This lib will inject a WebViewJavascriptBridge Object to window object. You can listen to WebViewJavascriptBridgeReady event to ensure window.WebViewJavascriptBridge is exist, as the blow code shows:
1 | if (window.WebViewJavascriptBridge) { |
Or put all JsBridge function call into window.WVJBCallbacks array if window.WebViewJavascriptBridge is undefined, this taks queue will be flushed when WebViewJavascriptBridgeReady event triggered.
Copy and paste setupWebViewJavascriptBridge into your JS:
1 | function setupWebViewJavascriptBridge(callback) { |
Call setupWebViewJavascriptBridge and then use the bridge to register handlers or call Java handlers:
1 | setupWebViewJavascriptBridge(function(bridge) { |
It same with https://github.com/marcuswestin/WebViewJavascriptBridge, that would be easier for you to define same behavior in different platform between Android and iOS. Meanwhile, writing concise code.
注册监听事件
这段代码是固定的,必须要放到js中
1 | /*这段代码是固定的,必须要放到js中*/ |
原生调用js
在 setupWebViewJavascriptBridge 中注册原生调用的js
1 | //在改function 中添加原生调起js方法 |
js 调用原生方法
1 | setupWebViewJavascriptBridge(function(bridge) { |
script阻塞DOM解析
浏览器解析html文件时,从上向下解析构建DOM树。当解析到script标签时,会暂停DOM构建。先把脚本加载并执行完毕,才会继续向下解析。js脚本的存在会阻塞DOM解析,进而影响页面渲染速度。
我们可以做以下处理:
将script标签放在html文件底部,避免解析DOM时被其阻塞
延迟脚本
在script标签上设置defer属性
1 | <script type="text/javascript" defer src="1.js"></script> |
告知浏览器立即下载脚本,但延迟执行。当浏览器解析完html文档时,再执行脚本。
- 异步脚本
1 | <script type="text/javascript" async src="1.js"></script> |
和defer功能类似,区别在于不会严格按照script标签顺序执行脚本,也就是说脚本2可能先于脚本1执行。脚本都会在onload事件前执行,但可能会在 DOMContentLoaded 事件触发前后执行。
注意:defer和async都只适用于外部脚本
babel原理
核心成员
- babel-core:babel转译器本身,提供了babel的转译API,如babel.transform等,用于对代码进行转译。像webpack的babel-loader 就是调用这些API来完成转译过程的。
- babylon:js的词法解析器
- babel-traverse:用于对AST(抽象语法树,想了解的请自行查询编译原理)的遍历,主要给plugin用
- babel-generator:根据AST生成代码
(1)babel的转译过程分为三个阶段:parsing、transforming、generating,以ES6代码转译为ES5代码为例,babel转译的具体过程如下:
ES6代码输入
babylon进行解析得到AST
plugin用babel-traverse对AST树进行遍历转译,得到新的AST树
用babel-generator通过AST树生成ES5代码
ES6代码输入 ==》 babylon进行解析 ==》 得到AST
==》 plugin用babel-traverse对AST树进行遍历转译 ==》 得到新的AST树
==》 用babel-generator通过AST树生成ES5代码
注:
babel只是转译新标准引入的语法,比如ES6的箭头函数转译成ES5的函数;而新标准引入的新的原生对象,部分原生对象新增的原型方法,新增的API等(如Proxy、Set等),这些babel是不会转译的。需要用户自行引入polyfill来解决
git rebase 和 git merge 有啥区别?
rebase会把你当前分支的 commit 放到公共分支的最后面,所以叫变基。
merge 会把公共分支和你当前的commit 合并在一起,形成一个新的 commit 提交
IntersectionObserver
IntersectionObserver接口(从属于Intersection Observer API)为开发者提供了一种可以异步监听目标元素与其祖先或视窗(viewport)交叉状态的手段。祖先元素与视窗(viewport)被称为根(root)。
API
1 | var io = new IntersectionObserver(callback, options) |
options
- root
用于观察的根元素,默认是浏览器的视口,也可以指定具体元素,指定元素的时候用于观察的元素必须是指定元素的子元素
- threshold
用来指定交叉比例,决定什么时候触发回调函数,是一个数组,默认是[0]。
1 | const options = { |
- rootMargin
用来扩大或者缩小视窗的的大小,使用css的定义方法,10px 10px 30px 20px表示top、right、bottom 和 left的值
callback
callback函数会触发两次,元素进入视窗(开始可见时)和元素离开视窗(开始不可见时)都会触发
1 | callback: (entries: IntersectionObserverEntry[]) => void; |
IntersectionObserverEntry
IntersectionObserverEntry提供观察元素的信息,有七个属性。
- boundingClientRect 目标元素的矩形信息
- intersectionRatio 相交区域和目标元素的比例值 intersectionRect/boundingClientRect 不可见时小于等于0
- intersectionRect 目标元素和视窗(根)相交的矩形信息 可以称为相交区域
- isIntersecting 目标元素当前是否可见 Boolean值 可见为true
- rootBounds 根元素的矩形信息,没有指定根元素就是当前视窗的矩形信息
- target 观察的目标元素
- time 返回一个记录从IntersectionObserver的时间到交叉被触发的时间的时间戳
懒加载
1 |
|
反向代理和正向代理
正向代理
正向代理类似一个跳板机,代理访问外部资源
比如我们国内访问谷歌,直接访问访问不到,我们可以通过一个正向代理服务器,请求发到代理服,代理服务器能够访问谷歌,这样由代理去谷歌取到返回数据,再返回给我们,这样我们就能访问谷歌了
用途:
访问原来无法访问的资源,如google
可以做缓存,加速访问资源
对客户端访问授权,上网进行认证
代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理
反向代理(Reverse Proxy)实际运行方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器
用途:
保证内网的安全,阻止web攻击,大型网站,通常将反向代理作为公网访问地址,Web服务器是内网
负载均衡,通过反向代理服务器来优化网站的负载
总结
正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端.
反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端
Chrome打开一个页面需要启动多少进程
最新的Chrome浏览器包括;1个浏览器主进程(Browser)、1个GPU进程、一个网络(NetWork)进程和多个插件进程。
浏览器进程:主要负责界面显示、用户交互、子进程管理,同时提供存储功能;
渲染进程:核心人物是将HTML、CSS和JavaScript引擎V8都是及逆行在该进程中,漠然情况下,Chrome会为每个Ta标签创建一个渲染进程。出于安全考虑;显然进程都是运行在沙箱模式下。
GPU进程:其实,Chrome刚开始发布的时候是没有GPU进程的。而GPU的使用初衷是为了实现3DCSS的效果,只是随后网页、Chrome的UI界面都选择采取GPU来绘制,这使得GPU成为浏览器普遍的需求。最后,Chrome在奇多进程架构上也引入了GPU进程。
网络进程:主要负责网页的网络资源加载,之前是作为一个模块运行在浏览器进程在里面的,直至最近才独立出来,成为一个单独的进程。
插件进程:主要是负责插件的运行,因插件容易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响
E2E
E2E(End To End)即端对端测试,属于黑盒测试,通过编写测试用例,自动化模拟用户操作,确保组件间通信正常,程序流数据传递如预期。
典型E2E测试框架对比
| 名称 | 断言 | 是否跨浏览器支持 | 实现 | 官网 | 是否开源 |
| —- | —- | —- | —- | —- |
| nightwatch | assert 和 Chai Expect | 是 | selenium | http://nightwatchjs.org/ | 是 |
| cypress | Chai、Chai-jQuery 等 | 否 | Chrome | https://www.cypress.io/ | 是 |
| testcafe | 自定义的断言 | 是 | 不是基于 selenium 实现 | https://devexpress.github.io/testcafe/ | 是 |
| katalon | TDD/BDD | 是 | 未知 | https://www.katalon.com/katalon-studio/ | 否 |
REST
REST就是用URL定位资源,用HTTP描述操作。
URI使用名词而不是动词,且推荐用复数。
BAD
- /getProducts
- /listOrders
- /retrieveClientByOrder?orderId=1
GOOD
- GET /products : will return the list of all products
- POST /products : will add a product to the collection
- GET /products/4 : will retrieve product #4
- PATCH/PUT /products/4 : will update profduct #4
Promise、Generator、Async三者的区别
Promise
Promise有三种状态:pending(进行中)、resolved(成功)、rejected(失败)
缺点
无法取消Promise,一旦新建它就会立即执行,无法中途取消。
如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以 Promise 的报错堆栈上下文不太友好。
Generator
Generator 是ES6引入的新语法,Generator是一个可以暂停和继续执行的函数。
简单的用法,可以当做一个Iterator来用,进行一些遍历操作。复杂一些的用法,他可以在内部保存一些状态,成为一个状态机。
Generator 基本语法包含两部分:函数名前要加一个星号;函数内部用 yield 关键字返回值。
yield,表达式本身没有返回值,或者说总是返回undefined。
next,方法可以带一个参数,该参数就会被当作上一个yield表达式的返回值。
1 | function * foo(x) { |
Async(推荐使用~~)
Async 是 Generator 的一个语法糖。
async 对应的是 * 。
await 对应的是 yield 。
async/await 自动进行了 Generator 的流程控制。
1 | async function fetchUser() { |
- 注意:若明确是当前函数内部需要异步转同步执行,再使用async。原因:babel会识别并将async编译成promise,造成编译后代码量增加。
webpack hash chunkhash contenthash
Webpack里面有三种hash,分别是:hash, chunkhash, contenthash
我们的浏览器会缓存我们的文件。缓存是把双刃剑,好处是浏览器读取缓存的文件,能带来更佳的用户体验(不需要额外流量,速度更快);坏处是有时候我们修改了文件内容,但是浏览器依然读取缓存的文件(也就是旧文件),导致用户看到的文件不是最新的。
hash能够帮助我们缓存已经及时的更新缓存文件。
hash
hash是项目级别的,多个入口文件输出的所有构建的文件是使用同一个hash。
缺点是假如我只改了其中一个文件,但是所有文件的文件名里面的hash都是一样的。这样会导致本来应该被浏览器缓存的文件,强制要去服务器读取一遍,但是这个文件又和之前的旧文件并没有区别,这样就很不好了。那能不能做到只有改变了文件,hash值才变,而没有改变的文件,文件名里面的hash值就不变呢?答案就是chunkhash。
chunkhash
chunkhash是模块级别的,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的hash值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成hash值,那么只要我们不改动公共库的代码,就可以保证其hash值不会受影响。
缺点就是一般我们会将css单独提取到一个文件中,当我们改变依赖的css文件的js文件的时候,依赖他的其它们文件构建的文件的hash值也会发送改变,即使我们的css文件并没有任何的改变,单独提取出来的css文件的hash值也发生了改变。
contenthash
contenthash是文件级别的。
contenthash表示由文件内容产生的hash值,内容不同产生的contenthash值也不一样。在项目中,通常做法是把项目中css都抽离出对应的css文件来加以引用。
对称加密和非对称加密
对称加密:
在对称加密算法中,加密和解密使用的是同一把钥匙,即:使用相同的密匙对同一密码进行加密和解密;
优点:算法简单,加密解密容易,效率高,执行快。
缺点:相对来说不算特别安全,只有一把钥匙,密文如果被拦截,且密钥也被劫持,那么,信息很容易被破译。
非对称加密:
在非对称加密算法中,公钥和私钥不是同一把密钥,用户A会将公钥公开,发送给用户B,保留住自己的私钥,用户B发送数据给A时,用A的公钥加密数据,然后发送给A,A收到加密数据后用自己的私钥解密数据。
优点:安全,即使密文被拦截、公钥被获取,但是无法获取到私钥,也就无法破译密文。作为接收方,务必要保管好自己的密钥。
缺点:加密算法及其复杂,安全性依赖算法与密钥,而且加密和解密效率很低。
devicePixelRatio
物理像素和css像素比例
vue修饰符
- .capture
添加事件监听器时使用事件捕获模式
- .passive
默认行为将会立即触发
修饰符尤其能够提升移动端的性能。
1 | <!-- 滚动事件的默认行为 (即滚动行为) 将会立即触发 --> |
- .self
添加事件监听器时使用事件捕获模式
v-model的实现原理
你可以用 v-model 指令在表单 <input>、<textarea> 及 <select> 元素上创建双向数据绑定。它会根据控件类型自动选取正确的方法来更新元素。尽管有些神奇,但 v-model 本质上不过是语法糖。它负责监听用户的输入事件以更新数据,并对一些极端场景进行一些特殊处理。
v-model 在内部为不同的输入元素使用不同的 property 并抛出不同的事件:
text和textarea元素使用valueproperty 和input事件;checkbox和radio使用checkedproperty 和change事件;select字段将value作为 property 并将change作为事件。
1 | <input v-model="msg" /> |
vm.$isServer
当前 Vue 实例是否运行于服务器。
vm.$attrs
包含了父作用域中不作为 prop 被识别 (且获取) 的 attribute 绑定 (class 和 style 除外)。当一个组件没有声明任何 prop 时,这里会包含所有父作用域的绑定 (class 和 style 除外),并且可以通过 v-bind=”$attrs” 传入内部组件——在创建高级别的组件时非常有用。
vm.$listeners
包含了父作用域中的 (不含 .native 修饰器的) v-on 事件监听器。它可以通过 v-on=”$listeners” 传入内部组件——在创建更高层次的组件时非常有用。
WeakSet
对象是一些对象值的集合, 并且其中的每个对象值都只能出现一次。在WeakSet的集合中是唯一的
它和 Set 对象的区别有两点:
- 与Set相比,WeakSet 只能是对象的集合,而不能是任何类型的任意值。
- WeakSet持弱引用:集合中对象的引用为弱引用。 如果没有其他的对WeakSet中对象的引用,那么这些对象会被当成垃圾回收掉。 这也意味着WeakSet中没有存储当前对象的列表。 正因为这样,WeakSet 是不可枚举的。
WeakMap
对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值可以是任意的。
它和 Map 对象的区别有两点:
原生的 WeakMap 持有的是每个键对象的“弱引用”,这意味着在没有其他引用存在时垃圾回收能正确进行。原生 WeakMap 的结构是特殊且有效的,其用于映射的 key 只有在其没有被回收时才是有效的。
WeakMap 的 key 是不可枚举的 (没有方法能给出所有的 key)。如果key 是可枚举的话,其列表将会受垃圾回收机制的影响,从而得到不确定的结果。因此,如果你想要这种类型对象的 key 值的列表,你应该使用 Map。
react-router
子组件获得 react-router 的history对象
1 | //子组件中引入 |
history 属性值
- history.length - 历史堆栈中的条目数
- history.location - 当前的 location
- history.action - 当前导航操作
监听
可以使用history.listen监听当前位置的更改:
1 | const unlisten = history.listen((location, action) => { |
location对象实现 window.location 接口的子集,包括:
- location.pathname - The path of the URL
- location.search - The URL query string
- location.hash - The URL hash fragment
Location还可以具有以下属性:
- location.state - 当前location不存在于URL中的一些额外状态 (createBrowserHistory、createMemoryHistory支持该属性)
- location.key - 表示当前loaction的唯一字符串 (createBrowserHistory、createMemoryHistory支持该属性)
导航
history对象可以使用以下方法以编程方式更改当前位置:
- history.push(path, [state])
- history.replace(path, [state])
- history.go(n)
- history.goBack()
- history.goForward()
使用push或replace时,可以将url路径和状态指定为单独的参数,也可以将object等单个位置中的所有内容作为第一个参数:
- 一个url路径
- 一个路径对象 { pathname, search, hash, state }
1 | // Push a new entry onto the history stack. |
其它
- 使用basename
如果应用程序中的所有URL都与其他“base”URL相关,请使用 basename 选项。此选项将给定字符串添加到您使用的所有URL的前面。
1 | const history = createHistory({ |
注意:在createMemoryHistory中不支持basename属性。
- 在CreateBrowserHistory中强制刷新整页
默认情况下,createBrowserHistory使用HTML5 pushState和replaceState来防止在导航时从服务器重新加载整个页面。如果希望在url更改时重新加载,请使用forceRefresh选项。
1 | const history = createBrowserHistory({ |
- 修改createHashHistory中的Hash类型
默认情况下,createHashHistory在基于hash的URL中使用’/‘。可以使用hashType选项使用不同的hash格式。
1 | const history = createHashHistory({ |
一个 tcp 连接能发几个 http 请求?
如果是 HTTP 1.0 版本协议,一般情况下,不支持长连接,因此在每次请求发送完毕之后,TCP 连接即会断开,因此一个 TCP 发送一个 HTTP 请求,但是有一种情况可以将一条 TCP 连接保持在活跃状态,那就是通过 Connection 和 Keep-Alive 首部,在请求头带上 Connection: Keep-Alive,并且可以通过 Keep-Alive 通用首部中指定的,用逗号分隔的选项调节 keep-alive 的行为,如果客户端和服务端都支持,那么其实也可以发送多条,不过此方式也有限制,可以关注《HTTP 权威指南》4.5.5 节对于 Keep-Alive 连接的限制和规则。
而如果是 HTTP 1.1 版本协议,支持了长连接,因此只要 TCP 连接不断开,便可以一直发送 HTTP 请求,持续不断,没有上限;
同样,如果是 HTTP 2.0 版本协议,支持多用复用,一个 TCP 连接是可以并发多个 HTTP 请求的,同样也是支持长连接,因此只要不断开 TCP 的连接,HTTP 请求数也是可以没有上限地持续发送
Virtual Dom 的优势在哪里?
其次是 VDOM 和真实 DOM 的区别和优化:
- 虚拟 DOM 不会立马进行排版与重绘操作
- 虚拟 DOM 进行频繁修改,然后一次性比较并修改真实 DOM 中需要改的部分,最后在真实 DOM 中进行排版与重绘,减少过多DOM节点排版与重绘损耗
- 虚拟 DOM 有效降低大面积真实 DOM 的重绘与排版,因为最终与真实 DOM 比较差异,可以只渲染局部
如何选择图片格式,例如 png, webp
| 图片格式 | 压缩方式 | 透明度 | 动画 | 浏览器兼容 | 适应场景 |
|---|
| JPEG | 有损压缩 | 不支持 | 不支持 | 所有 | 复杂颜色及形状、尤其是照片 |
| GIF | 无损压缩 | 支持 | 支持 | 所有 | 简单颜色,动画 |
| PNG | 无损压缩 | 支持 | 不支持 | 所有 | 需要透明时 |
| APNG | 无损压缩 | 支持 | 支持 | Firefox SafariIOS Safari | 需要半透明效果的动画 |
| WebP | 有损压缩 | 支持 | 支持 | Chrome OperaAndroid ChromeAndroid Browser | 复杂颜色及形状浏览器平台可预知 |
| SVG | 无损压缩 | 支持 | 支持 | 所有(IE8以上)||
如何判断 0.1 + 0.2 与 0.3 相等?
- 非是 ECMAScript 独有
- IEEE754 标准中 64 位的储存格式,比如 11 位存偏移值
- 其中涉及的三次精度丢失
了解v8引擎吗,一段js代码如何执行的
在执行一段代码时,JS 引擎会首先创建一个执行栈
然后JS引擎会创建一个全局执行上下文,并push到执行栈中, 这个过程JS引擎会为这段代码中所有变量分配内存并赋一个初始值(undefined),在创建完成后,JS引擎会进入执行阶段,这个过程JS引擎会逐行的执行代码,即为之前分配好内存的变量逐个赋值(真实值)。
如果这段代码中存在function的声明和调用,那么JS引擎会创建一个函数执行上下文,并push到执行栈中,其创建和执行过程跟全局执行上下文一样。但有特殊情况,即当函数中存在对其它函数的调用时,JS引擎会在父函数执行的过程中,将子函数的全局执行上下文push到执行栈,这也是为什么子函数能够访问到父函数内所声明的变量。
还有一种特殊情况是,在子函数执行的过程中,父函数已经return了,这种情况下,JS引擎会将父函数的上下文从执行栈中移除,与此同时,JS引擎会为还在执行的子函数上下文创建一个闭包,这个闭包里保存了父函数内声明的变量及其赋值,子函数仍然能够在其上下文中访问并使用这边变量/常量。当子函数执行完毕,JS引擎才会将子函数的上下文及闭包一并从执行栈中移除。
最后,JS引擎是单线程的,那么它是如何处理高并发的呢?即当代码中存在异步调用时JS是如何执行的。比如setTimeout或fetch请求都是non-blocking的,当异步调用代码触发时,JS引擎会将需要异步执行的代码移出调用栈,直到等待到返回结果,JS引擎会立即将与之对应的回调函数push进任务队列中等待被调用,当调用(执行)栈中已经没有需要被执行的代码时,JS引擎会立刻将任务队列中的回调函数逐个push进调用栈并执行。这个过程我们也称之为事件循环。
common.js 和 es6 中模块引入的区别?
CommonJS 是一种模块规范,最初被应用于 Nodejs,成为 Nodejs 的模块规范。运行在浏览器端的 JavaScript 由于也缺少类似的规范,在 ES6 出来之前,前端也实现了一套相同的模块规范 (例如: AMD),用来对前端模块进行管理。自 ES6 起,引入了一套新的 ES6 Module 规范,在语言标准的层面上实现了模块功能,而且实现得相当简单,有望成为浏览器和服务器通用的模块解决方案。但目前浏览器对 ES6 Module 兼容还不太好,我们平时在 Webpack 中使用的 export 和 import,会经过 Babel 转换为 CommonJS 规范。在使用上的差别主要有:
- CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
- CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
- CommonJs 是单个值导出,ES6 Module可以导出多个
- CommonJs 是动态语法可以写在判断里,ES6 Module 静态语法只能写在顶层
- CommonJs 的 this 是当前模块,ES6 Module的 this 是 undefined
Tree-Shaking的工作原理
Tree-shaking (树摇)最早是由Rollup实现,是一种采用删除不需要的额外代码的方式优化代码体积的技术,webpack2借鉴了这个特性也增加了tree-shaking的功能。
tree-shaking 只能在静态modules下工作,在ES6之前我们使用CommonJS规范引入模块,具体采用require()的方式动态引入模块,这个特性可以通过判断条件解决按需记载的优化问题
是CommonJS规范无法确定在实际运行前需要或者不需要某些模块,所以CommonJS不适合tree-shaking机制。
在JavaScript模块话方案中,只有ES6的模块方案:import()引入模块的方式采用静态导入,可以采用一次导入所有的依赖包再根据条件判断的方式,获取不需要的包,然后执行删除操作。
Tree-shaking的实现原理
利用ES6模块特性:
- 只能作为模块顶层的语句出现
- import的模块名只能是字符串常量
- 引入的模块不能再进行修改
代码删除
uglify:判断程序流,判断变量是否被使用和引用,进而删除代码
实现原理可以简单的概况:
- ES6 Module引入进行静态分析,故而编译的时候正确判断到底加载了那些模块
- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
注:
- Tree-shaking不能移除export default方式导出的模块而导入的一个整体的模块,所以应该尽量避免使用export default { A, B, C }导出的方式,而应该替换成 export { A, B, C } 的方式到处
设计WebSDK站在什么样的角度思考问题
使用者方便的角度,接口尽可能的简单
- 多通道API接口兼容性的抹平
- 形成场景模式的使用线,根据不同的场景将多个API调用合并成一个,尽可能的简化API的调用。
事件监听回调函数的链式操作和设置属性同步方法的链式操作
工厂方法的模式创建多通道的实例
单实例埋点添加,保证出现问题后方便定位问题
说明文档
- 保持简单清晰,在线版和SDK包(如果有)离线版共存
- 跟随SDK及时更新,注明更新时间及对应版本号,若新版改动较大,需要保持老版文档及入口
- 如果使用了第三方库,需要包含详尽的使用步骤、注意事项以及问题解决方法
提供Demo
- 保证Demo可用并随SDK或开发工具的更新保持同步更新
- Demo中应包含完整的SDK功能示例
webpack插件
- 编写一个JavaScript命名函数。
- 在它的原型上定义一个apply方法。
- 指定挂载的webpack事件钩子。
- 处理webpack内部实例的特定数据。
- 功能完成后调用webpack提供的回调。
webpack构建的主要钩子
Compiler暴露了和webpack整个生命周期相关的钩子
Compiler钩子
entryOption: 在 entry 配置项处理过之后,执行插件。
afterPlugins: 设置完初始插件之后,执行插件。参数:compiler
afterResolvers: resolver 安装完成之后,执行插件。参数:compiler
environment: environment 准备好之后,执行插件。
afterEnvironment: environment 安装完成之后,执行插件。
beforeRun: compiler.run() 执行之前,添加一个钩子。参数:compiler
run: 开始读取 records 之前,钩入(hook into) compiler。参数:compiler
watchRun: 监听模式下,一个新的编译(compilation)触发之后,执行一个插件,但是是在实际编译开始之前。参数:compiler
watchRun: 监听模式下,一个新的编译(compilation)触发之后,执行一个插件,但是是在实际编译开始之前。参数:compiler
normalModuleFactory: NormalModuleFactory 创建之后,执行插件。参数:normalModuleFactory
contextModuleFactory: ContextModuleFactory 创建之后,执行插件。参数:contextModuleFactory
beforeCompile: 编译(compilation)参数创建之后,执行插件。参数:compilationParams
compile: 一个新的编译(compilation)创建之后,钩入(hook into) compiler。参数:compilationParams
thisCompilation: 触发 compilation 事件之前执行(查看下面的 compilation)。参数:compilation
compilation: 编译(compilation)创建之后,执行插件。参数:compilation
make: 分析模块依赖。参数:compilation
afterCompile:
shouldEmit: 此时返回 true/false。参数:compilation
needAdditionalPass:
emit: 生成资源到 output 目录之前。参数:compilation
afterEmit: 生成资源到 output 目录之后。参数:compilation
done: 编译(compilation)完成。参数:stats
failed: 编译(compilation)失败。参数:error
invalid: 监听模式下,编译无效时。参数:fileName, changeTime
watchClose: 监听模式停止
Compilation钩子
Compilation暴露了与模块和依赖有关的粒度更小的事件钩子。
在编译阶段,模块会被加载(loaded)、封存(sealed)、优化(optimized)、分块(chunked)、哈希(hashed)和重新创建(restored)。
从上面的示例可以看到,compilation是Compiler生命周期中的一个步骤,使用compilation相关钩子的通用写法为:
buildModule: 在模块构建开始之前触发。参数:module
rebuildModule: 在重新构建一个模块之前触发。参数:module
…
seal: 编译(compilation)停止接收新模块时触发。
unseal: 编译(compilation)开始接收新模块时触发。
…
- optimize: 优化阶段开始时触发。
CDN缓存
http缓存是浏览器端缓存,cdn是服务器端缓存。
客户端浏览器先检查是否有本地缓存是否过期,如果过期,则向CDN边缘节点发起请求,CDN边缘节点会检测用户请求数据的缓存是否过期,如果没有过期,则直接响应用户请求,此时一个完成http请求结束;如果数据已经过期,那么CDN还需要向源站发出回源请求(back to the source request),来拉取最新的数据。
DNS缓存
浏览器DNS缓存
浏览器DNS缓存的时间跟DNS服务器返回的TTL值无关。
浏览器在获取网站域名的实际IP地址后会对其IP进行缓存,减少网络请求的损耗。每种浏览器都有一个固定的DNS缓存时间,其中Chrome的过期时间是1分钟,在这个期限内不会重新请求DNS。Chrome浏览器看本身的DNS缓存时间比较方便,在地址栏输入
1 | chrome://net-internals/#dns |
系统DNS缓存
系统缓存会参考DNS服务器响应的TTL值,但是不完全等于TTL值。
ISP DNS缓存
ISP(电信运营商)缓存有些不靠谱,有些缓存服务器会忽略网站DNS提供的TTL,自己设置一个较长的TTL,导致顶级DNS更新时不能及时拿到新的IP地址。
vue中methods与computed,filters,watch的区别
methods
不是响应式的
methods属性里面的方法会在数据发生变化的时候你,只要引用了此里面分方法,方法就会自动执行。这个属性没有依赖缓存。
computed
响应式的
computed属性,是一个计算属性,该属性里面的方法名相当于data属性里面的key,他可以作为key值使用,该属性里面的方法必须要有return返回值,这个返回值就是(value值)。computed属性是有依赖缓存的。
filters
filters属性,是过滤器属性,在vue2.0以后取消了vue本身自带的过滤器,但是我们可以通过自定义过滤器来实现相应的功能。改属性里面的方法需要有一个参数,这个参数是我们在运用过滤器的时候的数据,通过各过滤器方法的返回值,就是我们在页面上实际渲染的东西。
watch
watch属性,是监听属性。这个监听的是data属性里面的数据,当这个数据发生变化时,将自动执行这个函数。
scoped style
当 <style> 标签带有 scoped attribute 的时候,它的 CSS 只会应用到当前组件的元素上。这类似于 Shadow DOM 中的样式封装。
1 | /deep/ .abc { |
CSS Modules
网页样式的一种描述方法,可以保证某个组件的样式,不会影响到其他组件。
CSS Modules 提供各种插件,支持不同的构建工具。本文使用的是 Webpack 的css-loader插件,它在css-loader后面加了一个查询参数modules,表示打开 CSS Modules 功能。
1 | module: { |
局部作用域
CSS的规则都是全局的,任何一个组件的样式规则,都对整个页面有效。
产生局部作用域的唯一方法,就是使用一个独一无二的class的名字,不会与其他选择器重名。这就是 CSS Modules 的做法。
1 | import React from 'react'; |
1 | /* App.css */ |
最终会编译成
1 | <h1 class="_3zyde4l1yATCOkgn-DBWEL"> |
全局作用域
CSS Modules 允许使用:global(.className)的语法,声明一个全局规则。凡是这样声明的class,都不会被编译成哈希字符串。
CSS Modules 还提供一种显式的局部作用域语法:local(.className),等同于.className
定制哈希类名
css-loader默认的哈希算法是[hash:base64],这会将.title编译成._3zyde4l1yATCOkgn-DBWEL这样的字符串。
webpack.config.js里面可以定制哈希字符串的格式。
1 | module: { |
Class 的的组合
1 | .className { |
编译成
1 | ._2DHwuiHWMnKTOYG45T0x34 { |
1 | <h1 class="_2DHwuiHWMnKTOYG45T0x34 _10B-buq6_BEOTOl9urIjf8"> |
组合输入其他模块
1 | /* another.css */ |
1 | .title { |
输入变量
CSS Modules 支持使用变量,不过需要安装 PostCSS 和 postcss-modules-values。
webpack.config.js
1 | var values = require('postcss-modules-values'); |
1 | /* color.css */ |
1 | @value colors: "./colors.css"; |
Vue两个简易代替vuex的方法
eventBus
声明一个全局Vue实例变量 eventBus , 把所有的通信数据,事件监听都存储到这个变量上
Vue.observable
让一个对象可响应。Vue 内部会用它来处理 data 函数返回的对象。
返回的对象可以直接用于渲染函数和计算属性内,并且会在发生变更时触发相应的更新。也可以作为最小化的跨组件状态存储器,用于简单的场景:
PerformanceObserver
接口用于观察性能评估事件,并在浏览器的性能时间表中记录新的性能指标时通知它们。
1 | const performanceMetrics = {}; |
网页移动端调试工具
vConsole
引入vconsole到项目中:
1 | <script src="path/to/vconsole.min.js"></script> |
或者通过import 初试化:
1 | import VConsole from 'vconsole/dist/vconsole.min.js' //import vconsole |
项目运行,点击页面右下角vconsole图标,即可看到debug内容
如果想要查看接口调用情况,和浏览器一样直接点击network按钮即可
AlloyLever
AlloyLever是腾讯AlloyTeam团队开源的一款Web 开发调试工具。和vConsole类似
通过npm安装:
1 | npm install alloylever |
使用:
在你的页面任何地方引用下面脚本就可以,但是该js必须引用在其他脚本之前。
1 | <script src="alloylever.js"></script> |
务必记住,该js必须引用在其他脚本之前!
Eruda
使用手机端网页的调试工具Eruda在你的代码里面,加入下面两行代码,就可以轻轻松松实现手机调试了
1 | <script src="//cdn.jsdelivr.net/npm/eruda"></script> |
ps:想要在手机上查看,可以使手机跟你的电脑在同一个局域网内,然后访问电脑的ip,然后就能查看你做的h5页面了
spy-debugger
spy-debugger 是一个一站式页面调试、抓包工具。远程调试任何手机浏览器页面,任何手机移动端webview(如:微信,HybridApp等)。支持HTTP/HTTPS,无需USB连接设备。
特性
- 页面调试+抓包
- 操作简单,无需USB连接设备
- 支持HTTPS。
- spy-debugger内部集成了weinre、node-mitmproxy、AnyProxy。
- 自动忽略原生App发起的https请求,只拦截webview发起的https请求。对使用了SSL pinning技术的原生App不造成任何影响。
- 可以配合其它代理工具一起使用(默认使用AnyProxy) (设置外部代理)
DevTools
android&Html5混合开发WebView调试必备神器DevTools,chrome浏览器调试手机端WebView
DevTools能在浏览器上调试手机中的webview代码,给手机端调试带来了极大的便利!
操作步骤:
- 打开手机开发者选项,开启USB调试
- 打开待调试的webview
- 手机通过USB数据线跟电脑连接
- 打开chrome浏览器,输入:chrome://inspect/#devices
- 点击inspect,进入调试页面进行调试,之后就可以直接在电脑上操作手机啦
DevTools需要外网环境才能访问,在内网环境测试的要保证电脑与外网联通;
dev-server是怎么跑起来
webpack-dev-server 可以作为命令行工具使用,核心模块依赖是 webpack 和 webpack-dev-middleware。webpack-dev-server 负责启动一个 express 服务器监听客户端请求;实例化 webpack compiler;启动负责推送 webpack 编译信息的 websocket 服务器;负责向 bundle.js 注入和服务端通信用的 websocket 客户端代码和处理逻辑。webpack-dev-middleware 把 webpack compiler 的 outputFileSystem 改为 in-memory fileSystem;启动 webpack watch 编译;处理浏览器发出的静态资源的请求,把 webpack 输出到内存的文件响应给浏览器。
每次 webpack 编译完成后向客户端广播 ok 消息,客户端收到信息后根据是否开启 hot 模式使用 liveReload 页面级刷新模式或者 hotReload 模块热替换。hotReload 存在失败的情况,失败的情况下会降级使用页面级刷新。
开启 hot 模式,即启用 HMR 插件。hot 模式会向服务器请求更新过后的模块,然后对模块的父模块进行回溯,对依赖路径进行判断,如果每条依赖路径都配置了模块更新后所需的业务处理回调函数则是 accepted 状态,否则就降级刷新页面。判断 accepted 状态后对旧的缓存模块和父子依赖模块进行替换和删除,然后执行 accept 方法的回调函数,执行新模块代码,引入新模块,执行业务处理代码。
https://blog.csdn.net/LuckyWinty/article/details/109507412
使用过webpack里面哪些plugin和loader
webpack整个生命周期,loader和plugin有什么区别
Loader,直译为”加载器”。主要是用来解析和检测对应资源,负责源文件从输入到输出的转换,它专注于实现资源模块加载
Plugin,直译为”插件”。主要是通过webpack内部的钩子机制,在webpack构建的不同阶段执行一些额外的工作,它的插件是一个函数或者是一个包含apply方法的对象,接受一个compile对象,通过webpack的钩子来处理资源
Loader开发思路
通过module.exports导出一个函数
该函数默认参数一个参数source(即要处理的资源文件)
在函数体中处理资源(loader里配置响应的loader后)
通过return返回最终打包后的结果(这里返回的结果需为字符串形式)
Plugin开发思路
通过钩子机制实现
插件必须是一个函数或包含apply方法的对象
在方法体内通过webpack提供的API获取资源做响应处理
将处理完的资源通过webpack提供的方法返回该资源
webpack打包的整个过程
- 初始化参数:根据用户在命令窗口输入的参数以及 webpack.config.js 文件的配置,得到最后的配置。
- 开始编译:根据上一步得到的最终配置初始化得到一个 compiler 对象,注册所有的插件 plugins,插件开始监听 webpack 构建过程的生命周期的环节(事件),不同的环节会有相应的处理,然后开始执行编译。
- 确定入口:根据 webpack.config.js 文件中的 entry 入口,开始解析文件构建 AST 语法树,找出依赖,递归下去。
- 编译模块:递归过程中,根据文件类型和 loader 配置,调用相应的 loader 对不同的文件做不同的转换处理,再找出该模块依赖的模块,然后递归本步骤,直到项目中依赖的所有模块都经过了本步骤的编译处理。
- 编译过程中,有一系列的插件在不同的环节做相应的事情,比如 UglifyPlugin 会在 loader 转换递归完对结果使用 UglifyJs 压缩覆盖之前的结果;再比如 clean-webpack-plugin ,会在结果输出之前清除 dist 目录等等。
- 完成编译并输出:递归结束后,得到每个文件结果,包含转换后的模块以及他们之间的依赖关系,根据 entry 以及 output 等配置生成代码块 chunk。
- 打包完成:根据 output 输出所有的 chunk 到相应的文件目录。
一般怎么组织CSS(Webpack)
如何配置把js、css、html单独打包成一个文件
webpack和gulp的优缺点
| gulp | webpack | |
|---|---|---|
| 定位 | 基于任务流的自动化打包工具 | 模块化打包工具 |
| 优点 | 易于学习和理解, 适合多页面应用开发 | 可以模块化的打包任何资源,适配任何模块系统,适合SPA单页应用的开发 |
| 缺点 | 不太适合单页或者自定义模块的开发 | 学习成本低,配置复杂,通过babel编译后的js代码打包后体积过 |
使用webpack构建时有无做一些自定义操作
webpack的热更新是如何做到的?说明其原理?
loader原理,css-loader与style-loader
css-loader 的作用是处理css中的 @import 和 url 这样的外部资源
style-loader 的作用是把样式插入到 DOM中,方法是在head中插入一个style标签,并把样式写入到这个标签的 innerHTML里
loader的原理
loader能把源文件翻译成新的结果,一个文件可以链式经过多个loader编译。以处理scss文件为例:
sass-loader把scss转成css
css-loader找出css中的依赖,压缩资源
style-loader把css转换成脚本加载的JavaScript代码
Redux应用场景
1. Redux应用场景
在react中,数据在组件中单向流动的,数据只能从父组件向子组件流通(通过props),而两个非父子关系的组件之间通信就比较麻烦,redux的出现就是为了解决这个问题,它将组件之间需要共享的数据存储在一个store里面,其他需要这些数据的组件通过订阅的方式来刷新自己的视图。
2. Redux设计思想
它将整个应用状态存储到store里面,组件可以派发(dispatch)修改数据(state)的行为(action)给store,store内部修改之后,其他组件可以通过订阅(subscribe)中的状态state来刷新(render)自己的视图。
3. Redux应用的三大原则
单一数据源
我们可以把Redux的状态管理理解成一个全局对象,那么这个全局对象是唯一的,所有的状态都在全局对象store下进行统一”配置”,这样做也是为了做统一管理,便于调试与维护。State是只读的
与React的setState相似,直接改变组件的state是不会触发render进行渲染组件的。同样,在Redux中唯一改变state的方法就是触发action,action是一个用于描述发生了什么的“关键词”,而具体使action在state上更新生效的是reducer,用来描述事件发生的详细过程,reducer充当了发起一个action连接到state的桥梁。这样做的好处是当开发者试图去修改状态时,Redux会记录这个动作是什么类型的、具体完成了什么功能等(更新、传播过程),在调试阶段可以为开发者提供完整的数据流路径。Reducer必须是一个纯函数
Reducer用来描述action如何改变state,接收旧的state和action,返回新的state。Reducer内部的执行操作必须是无副作用的,不能对state进行直接修改,当状态发生变化时,需要返回一个全新的对象代表新的state。这样做的好处是,状态的更新是可预测的,另外,这与Redux的比较分发机制相关,阅读Redux判断状态更新的源码部分(combineReducers),发现Redux是对新旧state直接用==来进行比较,也就是浅比较,如果我们直接在state对象上进行修改,那么state所分配的内存地址其实是没有变化的,“==”是比较对象间的内存地址,因此Redux将不会响应我们的更新。之所以这样处理是避免对象深层次比较所带来的性能损耗(需要递归遍历比较)。
4. 源码实现
4.1 createStore
1 | export default function createStore(reducer, initialState) { |
action_type.js
1 | export const ADD = 'ADD' |
reducer.js
1 | import * as TYPES from './actions_type' |
store.js
1 | import {createStore} from 'redux' |
组件Counter.js
1 | import React, {useState,useEffect} from 'react' |
4.2 bindActionCreators
简易版
1 | export default function (actionCreators, dispatch) { |
源码版
1 | function bindActionCreator(actionCreator, dispatch) { |
Counter.js
1 | import React, {useState,useEffect} from 'react' |
4.3 combineReducer
1 | /** |
react-redux Provider和connect
Provider.js
1 | import React from 'react' |
connect.js
1 | import React, {useContext, useState, useEffect} from 'react' |
4.5 redux 中间件middlewares
正常我们的redux是这样的工作流程,action -> reducer ,这相当于是同步操作,由dispatch触发action之后直接去reducer执行相应的操作。但有时候我们会实现一些异步任务,像点击按钮 -> 获取服务器数据 ->渲染视图,这个时候就需要引入中间件改变redux同步执行流程,形成异步流程来实现我们的任务。有了中间件redux的工作流程就是action -> 中间件 -> reducer ,点击按钮就相当于dispatch 触发action,接着就是服务器获取数据middlewares执行,成功获取数据后触发reducer对应的操作,更新需要渲染的视图数据。
中间件的机制就是改变数据流,实现异步action,日志输出,异常报告等功能。
4.5.1 日志中间件
1 | import {createStore} from 'redux' |
4.5.2 thunk中间件
1 | function thunk ({dispatch, getState}) { |
4.5.3 级联中间件
上面我们调用的中间件都是单个调用,传进applyMiddleware的参数也是单个的,但是我们要想一次调用多个中间件,那么传到applyMiddleware的参数就是个数组,这个时候就需要级联处理,让他们一次执行。
1 | function compose(...funcs) { |
React怎么做数据的检查和变化
setState之后,会把当前的component放到dirtyComponents = [], 在batchUpdateTransaction的close阶段,遍历dirtyComponents,对状态发生改变的Component进行update,该Component执行render方法,可以得到renderedElement,然后renderedElement进行递归的update,这样子组件就会re-render,根据当前的props得到新的markup,这样整个虚拟DOM树就进行了更新
TLS原理
Transport Layer Security (TLS) 是一个为计算机网络提供通信安全的加密协议。它广泛应用于大量应用程序,其中之一即浏览网页。网站可以使用 TLS 来保证服务器和网页浏览器之间的所有通信安全。
整个 TLS 握手过程包含以下几个步骤:
- 客户端向服务器发送 『Client hello』 信息,附带着客户端随机值(random_C)和支持的加密算法组合。
- 服务器返回给客户端 『Server hello』信息,附带着服务器随机值(random_S),以及选择一个客户端发送过来加密算法。
- 服务器返回给客户端认证证书及或许要求客户端返回一个类似的证书,认证证书里面携带服务端的公钥信息。
- 服务器返回『Server hello done』信息。
- 如果服务器要求客户端发送一个证书,客户端进行发送。
- 客户端创建一个随机的 Pre-Master 密钥然后使用服务器证书中的公钥来进行加密,向服务器发送加密过的 Pre-Master 密钥。
- 服务器收到 Pre-Master 密钥。服务器和客户端各自生成基于 Pre-Master 密钥的主密钥和会话密钥。两个明文随机数 random_C 和 random_S 与自己计算产生的 pre-master,计算得到协商密钥enc_key=Fuc(random_C, random_S, pre-master)
- 客户端给服务器发送一个 『Change cipher spec』的通知,表明客户端将会开始使用协商密钥和加密算法进行加密通信。
- 客户端也发送了一个 『Client finished』的消息。
- 服务器接收到『Change cipher spec』的通知然后使用协商密钥和加密算法进行加密通信。
- 服务器返回客户端一个 『Server finished』消息。
- 客户端和服务器现在可以通过建立的安全通道来交换程序数据。所有客户端和服务器之间发送的信息都会使用会话密钥进行加密。
每当发生任何验证失败的时候,用户会收到警告。比如服务器使用自签名的证书。
WeakRef 和 FinalizationRegistry
WeakRef是一个更高级的API,它提供了真正的弱引用。
WeakRef 和 FinalizationRegistry 属于高级Api,在Chrome v84 和 Node.js 13.0.0 后开始支持。一般情况下不建议使用。
post为什么会发送两次请求?
同源策略
在浏览器中,内容是很开放的,任何资源都可以接入其中,如 JavaScript 文件、图片、音频、视频等资源,甚至可以下载其他站点的可执行文件。
但也不是说浏览器就是完全自由的,如果不加以控制,就会出现一些不可控的局面,例如会出现一些安全问题,如:
- 跨站脚本攻击(XSS)
- SQL 注入攻击
- OS 命令注入攻击
- HTTP 首部注入攻击
- 跨站点请求伪造(CSRF)
- 等等……
如果这些都没有限制的话,对于我们用户而言,是相对危险的,因此需要一些安全策略来保障我们的隐私和数据安全。
这就引出了最基础、最核心的安全策略:同源策略。
什么是同源策略
同源策略是一个重要的安全策略,它用于限制一个源的文档或者它加载的脚本如何能与另一个源的资源进行交互。
如果两个 URL 的协议、主机和端口都相同,我们就称这两个 URL 同源。
- 协议:协议是定义了数据如何在计算机内和之间进行交换的规则的系统,例如 HTTP、HTTPS。
- 主机:是已连接到一个计算机网络的一台电子计算机或其他设备。网络主机可以向网络上的用户或其他节点提供信息资源、服务和应用。使用 TCP/IP 协议族参与网络的计算机也可称为 IP 主机。
- 端口:主机是计算机到计算机之间的通信,那么端口就是进程到进程之间的通信。
如下表给出了与 URL http://store.company.com:80/dir/page.html 的源进行对比的示例:
| URL | 结果 | 原因 |
|---|---|---|
| http://store.company.com:80/dir2/page.html | 同源只 | 有路径不同 |
| http://store.company.com:80/dir/inner/another.html | 同源 | 只有路径不同 |
| https://store.company.com:443/secure.html | 不同源 | 协议不同,HTTP 和 HTTPS |
| http://store.company.com:81/dir/etc.html | 不同源 | 端口不同 |
| http://news.company.com:80/dir/other.html | 不同源 | 主机不同 |
同源策略主要表现在以下三个方面:DOM、Web 数据和网络。
- DOM 访问限制:同源策略限制了网页脚本(如 JavaScript)访问其他源的 DOM。这意味着通过脚本无法直接访问跨源页面的 DOM 元素、属性或方法。这是为了防止恶意网站从其他网站窃取敏感信息。
- Web 数据限制:同源策略也限制了从其他源加载的 Web 数据(例如 XMLHttpRequest 或 Fetch API)。在同源策略下,XMLHttpRequest 或 Fetch 请求只能发送到与当前网页具有相同源的目标。这有助于防止跨站点请求伪造(CSRF)等攻击。
- 网络通信限制:同源策略还限制了跨源的网络通信。浏览器会阻止从一个源发出的请求获取来自其他源的响应。这样做是为了确保只有受信任的源能够与服务器进行通信,以避免恶意行为。
出于安全原因,浏览器限制从脚本内发起的跨源 HTTP 请求,XMLHttpRequest 和 Fetch API,只能从加载应用程序的同一个域请求 HTTP 资源,除非使用 CORS 头文件
CORS
对于浏览器限制这个词,要着重解释一下:不一定是浏览器限制了发起跨站请求,也可能是跨站请求可以正常发起,但是返回结果被浏览器拦截了。
浏览器将不同域的内容隔离在不同的进程中,网络进程负责下载资源并将其送到渲染进程中,但由于跨域限制,某些资源可能被阻止加载到渲染进程。如果浏览器发现一个跨域响应包含了敏感数据,它可能会阻止脚本访问这些数据,即使网络进程已经获得了这些数据。CORB 的目标是在渲染之前尽早阻止恶意代码获取跨域数据。
CORB 是一种安全机制,用于防止跨域请求恶意访问跨域响应的数据。渲染进程会在 CORB 机制的约束下,选择性地将哪些资源送入渲染进程供页面使用。
例如,一个网页可能通过 AJAX 请求从另一个域的服务器获取数据。虽然某些情况下这样的请求可能会成功,但如果浏览器检测到请求返回的数据可能包含恶意代码或与同源策略冲突,浏览器可能会阻止网页访问返回的数据,以确保用户的安全。
跨源资源共享(Cross-Origin Resource Sharing,CORS)是一种机制,允许在受控的条件下,不同源的网页能够请求和共享资源。由于浏览器的同源策略限制了跨域请求,CORS 提供了一种方式来解决在 Web 应用中进行跨域数据交换的问题。
CORS 的基本思想是,服务器在响应中提供一个标头(HTTP 头),指示哪些源被允许访问资源。浏览器在发起跨域请求时会先发送一个预检请求(OPTIONS 请求)到服务器,服务器通过设置适当的 CORS 标头来指定是否允许跨域请求,并指定允许的请求源、方法、标头等信息。
简单请求
不会触发 CORS 预检请求。这样的请求为 简单请求,。若请求满足所有下述条件,则该请求可视为 简单请求:
- HTTP 方法限制:只能使用 GET、HEAD、POST 这三种 HTTP 方法之一。如果请求使用了其他 HTTP 方法,就不再被视为简单请求。
- 自定义标头限制:请求的 HTTP 标头只能是以下几种常见的标头:
Accept、Accept-Language、Content-Language、Last-Event-ID、Content-Type(仅限于application/x-www-form-urlencoded、multipart/form-data、text/plain)。HTML 头部 header field 字段:DPR、Download、Save-Data、Viewport-Width、WIdth。如果请求使用了其他标头,同样不再被视为简单请求。 - 请求中没有使用 ReadableStream 对象。
- 不使用自定义请求标头:请求不能包含用户自定义的标头。
- 请求中的任意 XMLHttpRequestUpload 对象均没有注册任何事件监听器;XMLHttpRequestUpload 对象可以使用 XMLHttpRequest.upload 属性访问
预检请求
非简单请求的 CORS 请求,会在正式通信之前,增加一次 HTTP 查询请求,称为 预检请求。
需预检的请求要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。预检请求 的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。
例如我们在掘金上删除一条沸点:
它首先会发起一个预检请求,预检请求的头信息包括两个特殊字段:
- Access-Control-Request-Method:该字段是必须的,用来列出浏览器的 CORS 请求会用到哪些 HTTP 方法,上例是 POST。
- Access-Control-Request-Headers:该字段是一个逗号分隔的字符串,指定浏览器 CORS 请求会额外发送的头信息字段,上例是
content-type,x-secsdk-csrf-token。 - Access-Control-Allow-Origin:在上述例子中,表示
https://juejin.cn可以请求数据,也可以设置为* 符号,表示统一任意跨源请求。 - Access-Control-Max-Age:该字段可选,用来指定本次预检请求的有效期,单位为秒。上面结果中,有效期是 1 天(86408 秒),即允许缓存该条回应 1 天(86408 秒),在此期间,不用发出另一条预检请求。
一旦服务器通过了 预检请求,以后每次浏览器正常的 CORS 请求,就都跟简单请求一样,会有一个 Origin 头信息字段。服务器的回应,也都会有一个 Access-Control-Allow-Origin 头信息字段。
上面头信息中,Access-Control-Allow-Origin 字段是每次回应都必定包含的。
附带身份凭证的请求与通配符
在响应附带身份凭证的请求时:
- 为了避免恶意网站滥用 Access-Control-Allow-Origin 头部字段来获取用户敏感信息,服务器在设置时不能将其值设为通配符 *。相反,应该将其设置为特定的域,例如:Access-Control-Allow-Origin:
https://juejin.cn。通过将 Access-Control-Allow-Origin 设置为特定的域,服务器只允许来自指定域的请求进行跨域访问。这样可以限制跨域请求的范围,避免不可信的域获取到用户敏感信息。 - 为了避免潜在的安全风险,服务器不能将 Access-Control-Allow-Headers 的值设为通配符
*。这是因为不受限制的请求头可能被滥用。相反,应该将其设置为一个包含标头名称的列表,例如:Access-Control-Allow-Headers: X-PINGOTHER, Content-Type。通过将 Access-Control-Allow-Headers 设置为明确的标头名称列表,服务器可以限制哪些自定义请求头是允许的。只有在允许的标头列表中的头部字段才能在跨域请求中被接受。 - 为了避免潜在的安全风险,服务器不能将 Access-Control-Allow-Methods 的值设为通配符
*。这样做将允许来自任意域的请求使用任意的 HTTP 方法,可能导致滥用行为的发生。相反,应该将其设置为一个特定的请求方法名称列表,例如:Access-Control-Allow-Methods: POST, GET。通过将 Access-Control-Allow-Methods 设置为明确的请求方法列表,服务器可以限制哪些方法是允许的。只有在允许的方法列表中的方法才能在跨域请求中被接受和处理。 - 对于附带身份凭证的请求(通常是 Cookie),
这是因为请求的标头中携带了 Cookie 信息,如果 Access-Control-Allow-Origin 的值为 *,请求将会失败。而将 Access-Control-Allow-Origin 的值设置为 https://juejin.cn,则请求将成功执行。
另外,响应标头中也携带了 Set-Cookie 字段,尝试对 Cookie 进行修改。如果操作失败,将会抛出异常。
为什么本地使用 webpack 进行 dev 开发时,不需要服务器端配置 cors 的情况下访问到线上接口?
当你在本地通过 Ajax 或其他方式请求线上接口时,由于浏览器的同源策略,会出现跨域的问题。但是在服务器端并不会出现这个问题。
它是通过 Webpack Dev Server 来实现这个功能。当你在浏览器中发送请求时,请求会先被 Webpack Dev Server 捕获,然后根据你的代理规则将请求转发到目标服务器,目标服务器返回的数据再经由 Webpack Dev Server 转发回浏览器。这样就绕过了浏览器的同源策略限制,使你能够在本地开发环境中访问线上接口。